 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Tabular Anomaly Detection via Pseudo-Label-Guided Generation
Apr 20, 2026Identifying anomalous instances in tabular data is essential for improving data reliability and maintaining system stability. Due to the scarcity of ground-truth anomaly labels, existing methods mainly rely on unsupervised anomaly detection models, or exploit a small number of labeled anomalies to facilitate detection via sample generation or contrastive learning. However, unsupervised methods lack sufficient anomaly awareness, while current generation and contrastive approaches tend to compute anomalies globally, overlooking the localized anomaly patterns of tabular features, resulting in suboptimal detection performance. To address these limitations, we propose PLAG, a pseudo-label-guided anomaly generation method designed to enhance tabular anomaly detection. Specifically, by utilizing pseudo-anomalies as guidance signals and decoupling the overall anomaly quantification of a sample into an accumulation of feature-level abnormalities, PLAG not only effectively obviates the need for scarce ground-truth labels but also provides a novel perspective for the model to comprehend localized anomalous signals at a fine-grained level. Furthermore, a two-stage data selection strategy is proposed, integrating format verification and uncertainty estimation to rigorously filter candidate samples, thereby ensuring the fidelity and diversity of the synthetic anomalies. Ultimately, these filtered synthetic anomalies serve as robust discriminative guidance, empowering the model to better separate normal and anomalous instances. Extensive experiments demonstrate that PLAG achieves state-of-the-art performance against eight representative baselines. Moreover, as a flexible framework, it integrates seamlessly with existing unsupervised detectors, consistently boosting F1-scores by 0.08 to 0.21.
PASTE: Physics-Aware Scattering Topology Embedding Framework for SAR Object Detection
Mar 16, 2026Current deep learning-based object detection for Synthetic Aperture Radar (SAR) imagery mainly adopts optical image methods, treating targets as texture patches while ignoring inherent electromagnetic scattering mechanisms. Though scattering points have been studied to boost detection performance, most methods still rely on amplitude-based statistical models. Some approaches introduce frequency-domain information for scattering center extraction, but they suffer from high computation cost and poor compatibility with diverse datasets. Thus, effectively embedding scattering topological information into modern detection frameworks remains challenging. To solve these problems, this paper proposes the Physics-Aware Scattering Topology Embedding Framework (PASTE), a novel closed-loop architecture for comprehensive scattering prior integration. By building the full pipeline from topology generation, injection to joint supervision, PASTE elegantly integrates scattering physics into modern SAR detectors. Specifically, it designs a scattering keypoint generation and automatic annotation scheme based on the Attributed Scattering Center (ASC) model to produce scalable and physically consistent priors. A scattering topology injection module guides multi-scale feature learning, and a scattering prior supervision strategy constrains network optimization by aligning predictions with scattering center distributions. Experiments on real datasets show that PASTE is compatible with various detectors and brings relative mAP gains of 2.9% to 11.3% over baselines with acceptable computation overhead. Visualization of scattering maps verifies that PASTE successfully embeds scattering topological priors into feature space, clearly distinguishing target and background scattering regions, thus providing strong interpretability for results.
CEI-3D: Collaborative Explicit-Implicit 3D Reconstruction for Realistic and Fine-Grained Object Editing
Mar 12, 2026Existing 3D editing methods often produce unrealistic and unrefined results due to the deeply integrated nature of their reconstruction networks. To address the challenge, this paper introduces CEI-3D, an editing-oriented reconstruction pipeline designed to facilitate realistic and fine-grained editing. Specifically, we propose a collaborative explicit-implicit reconstruction approach, which represents the target object using an implicit SDF network and a differentially sampled, locally controllable set of handler points. The implicit network provides a smooth and continuous geometry prior, while the explicit handler points offer localized control, enabling mutual guidance between the global 3D structure and user-specified local editing regions. To independently control each attribute of the handler points, we design a physical properties disentangling module to decouple the color of the handler points into separate physical properties. We also propose a dual-diffuse-albedo network in this module to process the edited and non-edited regions through separate branches, thereby preventing undesired interference from editing operations. Building on the reconstructed collaborative explicit-implicit representation with disentangled properties, we introduce a spatial-aware editing module that enables part-wise adjustment of relevant handler points. This module employs a cross-view propagation-based 3D segmentation strategy, which helps users to edit the specified physical attributes of a target part efficiently. Extensive experiments on both real and synthetic datasets demonstrate that our approach achieves more realistic and fine-grained editing results than the state-of-the-art (SOTA) methods while requiring less editing time. Our code is available on https://github.com/shiyue001/CEI-3D.
HPR3D: Hierarchical Proxy Representation for High-Fidelity 3D Reconstruction and Controllable Editing
Jul 16, 2025



Current 3D representations like meshes, voxels, point clouds, and NeRF-based neural implicit fields exhibit significant limitations: they are often task-specific, lacking universal applicability across reconstruction, generation, editing, and driving. While meshes offer high precision, their dense vertex data complicates editing; NeRFs deliver excellent rendering but suffer from structural ambiguity, hindering animation and manipulation; all representations inherently struggle with the trade-off between data complexity and fidelity. To overcome these issues, we introduce a novel 3D Hierarchical Proxy Node representation. Its core innovation lies in representing an object's shape and texture via a sparse set of hierarchically organized (tree-structured) proxy nodes distributed on its surface and interior. Each node stores local shape and texture information (implicitly encoded by a small MLP) within its neighborhood. Querying any 3D coordinate's properties involves efficient neural interpolation and lightweight decoding from relevant nearby and parent nodes. This framework yields a highly compact representation where nodes align with local semantics, enabling direct drag-and-edit manipulation, and offers scalable quality-complexity control. Extensive experiments across 3D reconstruction and editing demonstrate our method's expressive efficiency, high-fidelity rendering quality, and superior editability.
LiftFeat: 3D Geometry-Aware Local Feature Matching
May 06, 2025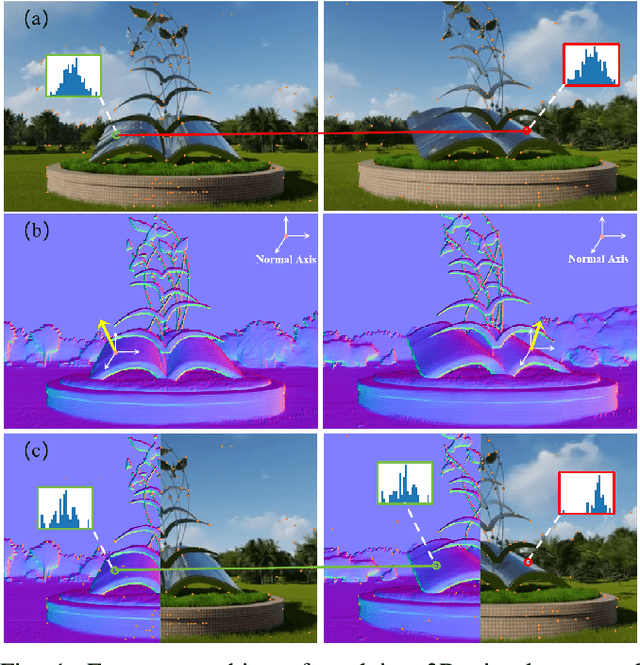
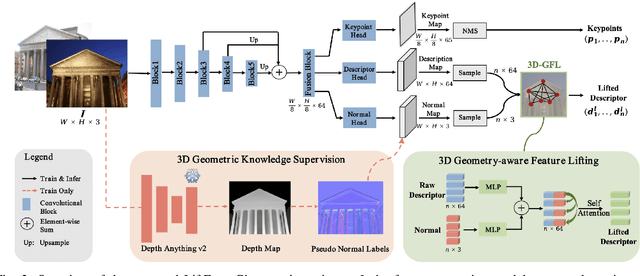

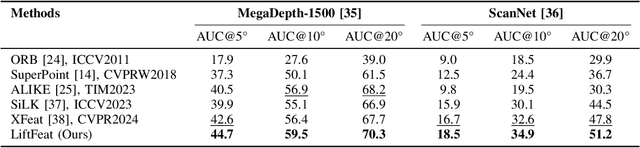
Robust and efficient local feature matching plays a crucial role in applications such as SLAM and visual localization for robotics. Despite great progress, it is still very challenging to extract robust and discriminative visual features in scenarios with drastic lighting changes, low texture areas, or repetitive patterns. In this paper, we propose a new lightweight network called \textit{LiftFeat}, which lifts the robustness of raw descriptor by aggregating 3D geometric feature. Specifically, we first adopt a pre-trained monocular depth estimation model to generate pseudo surface normal label, supervising the extraction of 3D geometric feature in terms of predicted surface normal. We then design a 3D geometry-aware feature lifting module to fuse surface normal feature with raw 2D descriptor feature. Integrating such 3D geometric feature enhances the discriminative ability of 2D feature description in extreme conditions. Extensive experimental results on relative pose estimation, homography estimation, and visual localization tasks, demonstrate that our LiftFeat outperforms some lightweight state-of-the-art methods. Code will be released at : https://github.com/lyp-deeplearning/LiftFeat.
LLM Sensitivity Evaluation Framework for Clinical Diagnosis
Apr 18, 2025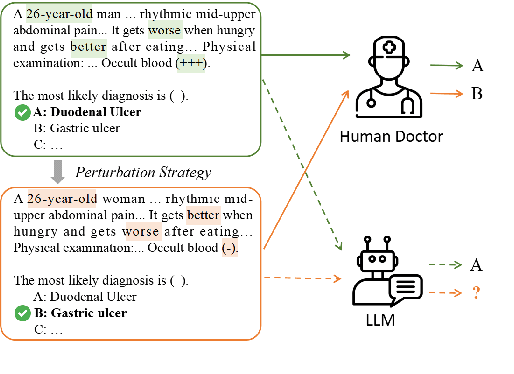
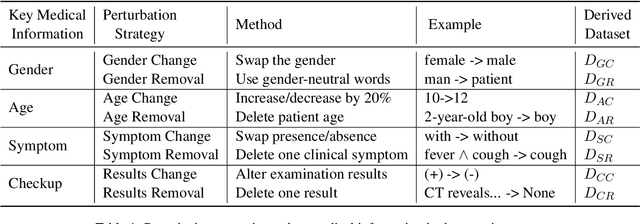
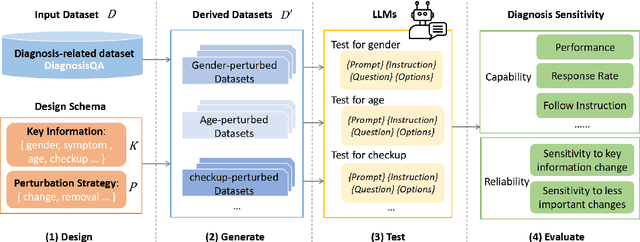
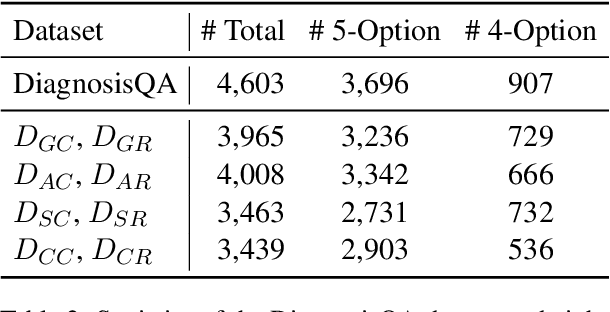
Large language models (LLMs) have demonstrated impressive performance across various domains. However, for clinical diagnosis, higher expectations are required for LLM's reliability and sensitivity: thinking like physicians and remaining sensitive to key medical information that affects diagnostic reasoning, as subtle variations can lead to different diagnosis results. Yet, existing works focus mainly on investigating the sensitivity of LLMs to irrelevant context and overlook the importance of key information. In this paper, we investigate the sensitivity of LLMs, i.e. GPT-3.5, GPT-4, Gemini, Claude3 and LLaMA2-7b, to key medical information by introducing different perturbation strategies. The evaluation results highlight the limitations of current LLMs in remaining sensitive to key medical information for diagnostic decision-making. The evolution of LLMs must focus on improving their reliability, enhancing their ability to be sensitive to key information, and effectively utilizing this information. These improvements will enhance human trust in LLMs and facilitate their practical application in real-world scenarios. Our code and dataset are available at https://github.com/chenwei23333/DiagnosisQA.
DualNeRF: Text-Driven 3D Scene Editing via Dual-Field Representation
Feb 22, 2025



Recently, denoising diffusion models have achieved promising results in 2D image generation and editing. Instruct-NeRF2NeRF (IN2N) introduces the success of diffusion into 3D scene editing through an "Iterative dataset update" (IDU) strategy. Though achieving fascinating results, IN2N suffers from problems of blurry backgrounds and trapping in local optima. The first problem is caused by IN2N's lack of efficient guidance for background maintenance, while the second stems from the interaction between image editing and NeRF training during IDU. In this work, we introduce DualNeRF to deal with these problems. We propose a dual-field representation to preserve features of the original scene and utilize them as additional guidance to the model for background maintenance during IDU. Moreover, a simulated annealing strategy is embedded into IDU to endow our model with the power of addressing local optima issues. A CLIP-based consistency indicator is used to further improve the editing quality by filtering out low-quality edits. Extensive experiments demonstrate that our method outperforms previous methods both qualitatively and quantitatively.
USR: Unsupervised Separated 3D Garment and Human Reconstruction via Geometry and Semantic Consistency
Mar 02, 2023



Dressed people reconstruction from images is a popular task with promising applications in the creative media and game industry. However, most existing methods reconstruct the human body and garments as a whole with the supervision of 3D models, which hinders the downstream interaction tasks and requires hard-to-obtain data. To address these issues, we propose an unsupervised separated 3D garments and human reconstruction model (USR), which reconstructs the human body and authentic textured clothes in layers without 3D models. More specifically, our method proposes a generalized surface-aware neural radiance field to learn the mapping between sparse multi-view images and geometries of the dressed people. Based on the full geometry, we introduce a Semantic and Confidence Guided Separation strategy (SCGS) to detect, segment, and reconstruct the clothes layer, leveraging the consistency between 2D semantic and 3D geometry. Moreover, we propose a Geometry Fine-tune Module to smooth edges. Extensive experiments on our dataset show that comparing with state-of-the-art methods, USR achieves improvements on both geometry and appearance reconstruction while supporting generalizing to unseen people in real time. Besides, we also introduce SMPL-D model to show the benefit of the separated modeling of clothes and the human body that allows swapping clothes and virtual try-on.
Variational Gaussian Topic Model with Invertible Neural Projections
May 21, 2021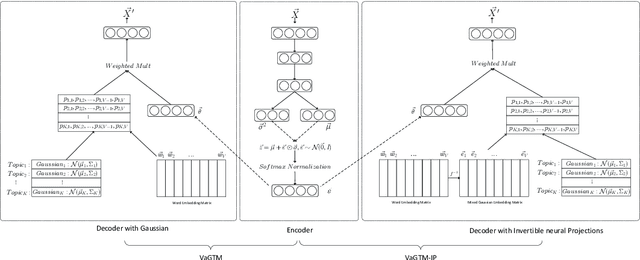
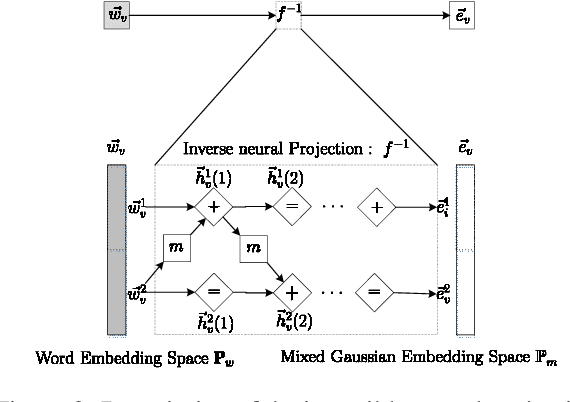
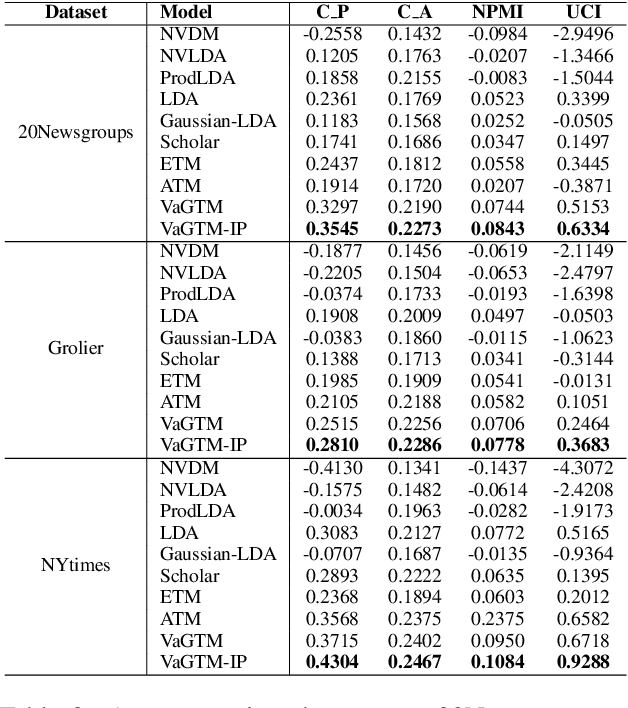
Neural topic models have triggered a surge of interest in extracting topics from text automatically since they avoid the sophisticated derivations in conventional topic models. However, scarce neural topic models incorporate the word relatedness information captured in word embedding into the modeling process. To address this issue, we propose a novel topic modeling approach, called Variational Gaussian Topic Model (VaGTM). Based on the variational auto-encoder, the proposed VaGTM models each topic with a multivariate Gaussian in decoder to incorporate word relatedness. Furthermore, to address the limitation that pre-trained word embeddings of topic-associated words do not follow a multivariate Gaussian, Variational Gaussian Topic Model with Invertible neural Projections (VaGTM-IP) is extended from VaGTM. Three benchmark text corpora are used in experiments to verify the effectiveness of VaGTM and VaGTM-IP. The experimental results show that VaGTM and VaGTM-IP outperform several competitive baselines and obtain more coherent topics.
WebSRC: A Dataset for Web-Based Structural Reading Comprehension
Jan 23, 2021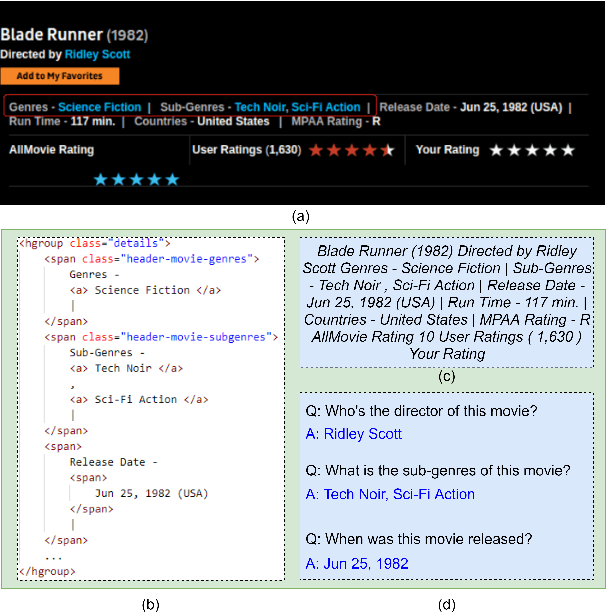

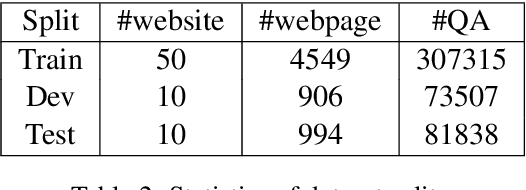

Web search is an essential way for human to obtain information, but it's still a great challenge for machines to understand the contents of web pages. In this paper, we introduce the task of web-based structural reading comprehension. Given a web page and a question about it, the task is to find an answer from the web page. This task requires a system not only to understand the semantics of texts but also the structure of the web page. Moreover, we proposed WebSRC, a novel Web-based Structural Reading Comprehension dataset. WebSRC consists of 0.44M question-answer pairs, which are collected from 6.5K web pages with corresponding HTML source code, screenshots, and metadata. Each question in WebSRC requires a certain structural understanding of a web page to answer, and the answer is either a text span on the web page or yes/no. We evaluate various strong baselines on our dataset to show the difficulty of our task. We also investigate the usefulness of structural information and visual features. Our dataset and task are publicly available at https://speechlab-sjtu.github.io/WebSRC/.