 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACFN: Transformer-based Adaptive Cross-modal Fusion Network for Multimodal Emotion Recognition
May 10, 2025The fusion technique is the key to the multimodal emotion recognition task. Recently, cross-modal attention-based fusion methods have demonstrated high performance and strong robustness. However, cross-modal attention suffers from redundant features and does not capture complementary features well. We find that it is not necessary to use the entire information of one modality to reinforce the other during cross-modal interaction, and the features that can reinforce a modality may contain only a part of it. To this end, we design an innovative Transformer-based Adaptive Cross-modal Fusion Network (TACFN). Specifically, for the redundant features, we make one modality perform intra-modal feature selection through a self-attention mechanism, so that the selected features can adaptively and efficiently interact with another modality. To better capture the complementary information between the modalities, we obtain the fused weight vector by splicing and use the weight vector to achieve feature reinforcement of the modalities. We apply TCAFN to the RAVDESS and IEMOCAP datasets. For fair comparison, we use the same unimodal representations to validate the effectiveness of the proposed fusion method. The experimental results show that TACFN brings a significant performance improvement compared to other methods and reaches the state-of-the-art. All code and models could be accessed from https://github.com/shuzihuaiyu/TACFN.
LMR-CBT: Learning Modality-fused Representations with CB-Transformer for Multimodal Emotion Recognition from Unaligned Multimodal Sequences
Dec 03, 2021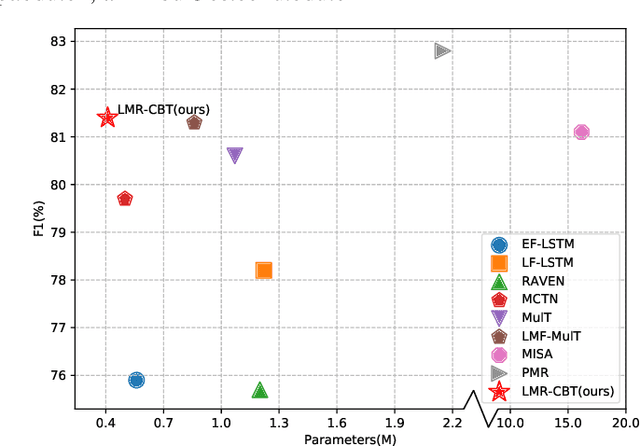
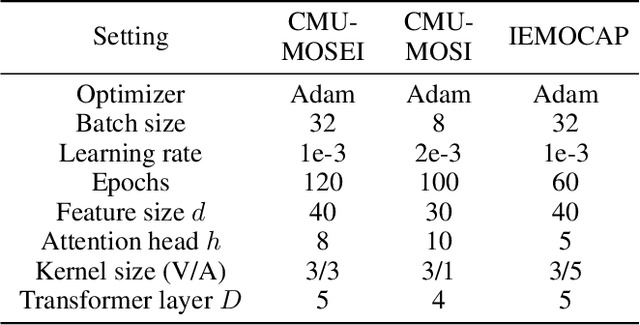
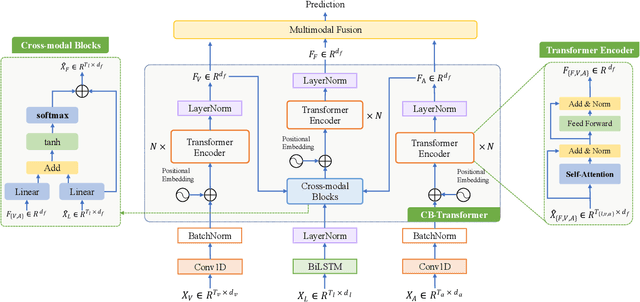
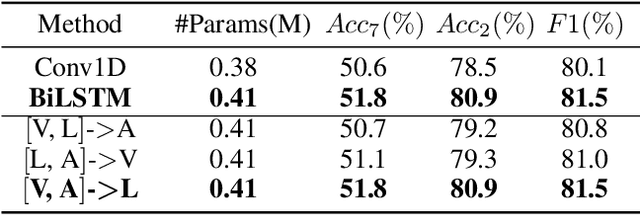
Learning modality-fused representations and processing unaligned multimodal sequences are meaningful and challenging in multimodal emotion recognition. Existing approaches use directional pairwise attention or a message hub to fuse language, visual, and audio modalities. However, those approaches introduce information redundancy when fusing features and are inefficient without considering the complementarity of modalities. In this paper, we propose an efficient neural network to learn modality-fused representations with CB-Transformer (LMR-CBT) for multimodal emotion recognition from unaligned multimodal sequences. Specifically, we first perform feature extraction for the three modalities respectively to obtain the local structure of the sequences. Then, we design a novel transformer with cross-modal blocks (CB-Transformer) that enables complementary learning of different modalities, mainly divided into local temporal learning,cross-modal feature fusion and global self-attention representations. In addition, we splice the fused features with the original features to classify the emotions of the sequences. Finally, we conduct word-aligned and unaligned experiments on three challenging datasets, IEMOCAP, CMU-MOSI, and CMU-MOSEI. The experimental results show the superiority and efficiency of our proposed method in both settings. Compared with the mainstream methods, our approach reaches the state-of-the-art with a minimum number of parameters.
A cross-modal fusion network based on self-attention and residual structure for multimodal emotion recognition
Nov 03, 2021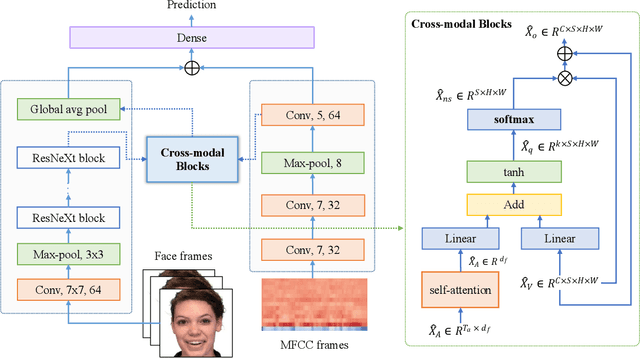
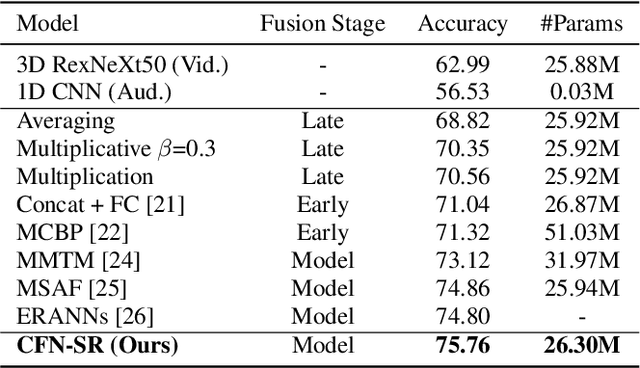
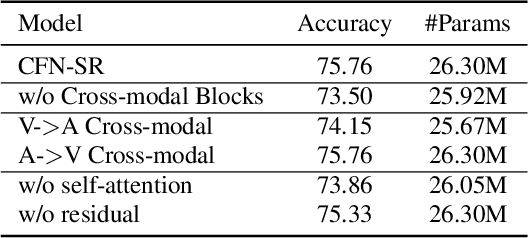
The audio-video based multimodal emotion recognition has attracted a lot of attention due to its robust performance. Most of the existing methods focus on proposing different cross-modal fusion strategies. However, these strategies introduce redundancy in the features of different modalities without fully considering the complementary properties between modal information, and these approaches do not guarantee the non-loss of original semantic information during intra- and inter-modal interactions. In this paper, we propose a novel cross-modal fusion network based on self-attention and residual structure (CFN-SR) for multimodal emotion recognition. Firstly, we perform representation learning for audio and video modalities to obtain the semantic features of the two modalities by efficient ResNeXt and 1D CNN, respectively. Secondly, we feed the features of the two modalities into the cross-modal blocks separately to ensure efficient complementarity and completeness of information through the self-attention mechanism and residual structure. Finally, we obtain the output of emotions by splicing the obtained fused representation with the original representation. To verify the effectiveness of the proposed method, we conduct experiments on the RAVDESS dataset. The experimental results show that the proposed CFN-SR achieves the state-of-the-art and obtains 75.76% accuracy with 26.30M parameters. Our code is available at https://github.com/skeletonNN/CFN-SR.
EvoGAN: An Evolutionary Computation Assisted GAN
Oct 22, 2021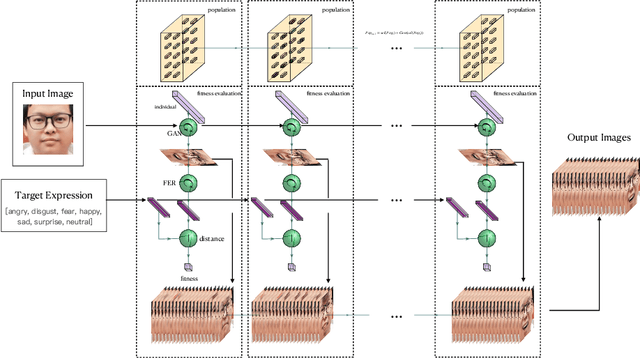

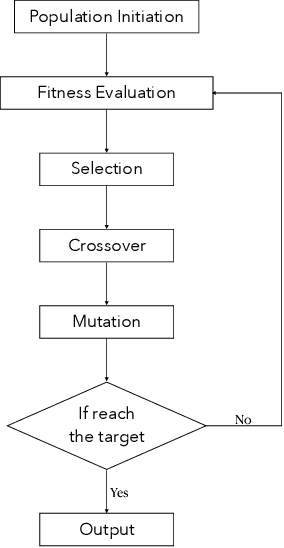
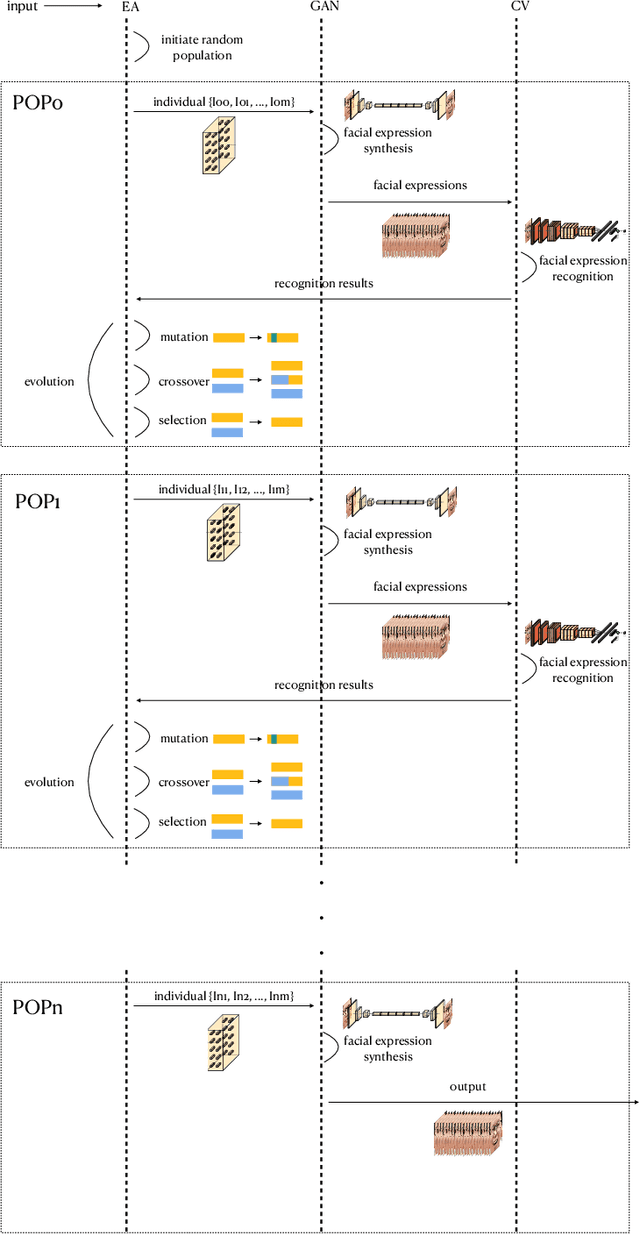
The image synthesis technique is relatively well established which can generate facial images that are indistinguishable even by human beings. However, all of these approaches uses gradients to condition the output, resulting in the outputting the same image with the same input. Also, they can only generate images with basic expression or mimic an expression instead of generating compound expression. In real life, however, human expressions are of great diversity and complexity. In this paper, we propose an evolutionary algorithm (EA) assisted GAN, named EvoGAN, to generate various compound expressions with any accurate target compound expression. EvoGAN uses an EA to search target results in the data distribution learned by GAN. Specifically, we use the Facial Action Coding System (FACS) as the encoding of an EA and use a pre-trained GAN to generate human facial images, and then use a pre-trained classifier to recognize the expression composition of the synthesized images as the fitness function to guide the search of the EA. Combined random searching algorithm, various images with the target expression can be easily sythesized. Quantitative and Qualitative results are presented on several compound expressions, and the experimental results demonstrate the feasibility and the potential of EvoGAN.