 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyLLaVA: A Framework of Small-scale Large Multimodal Models
Paper and Code
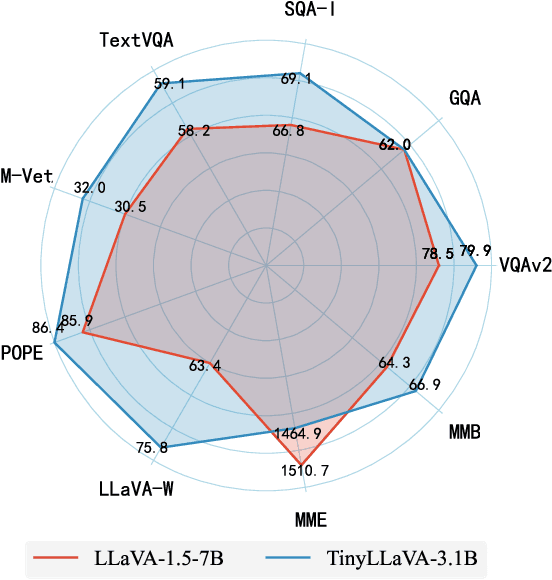
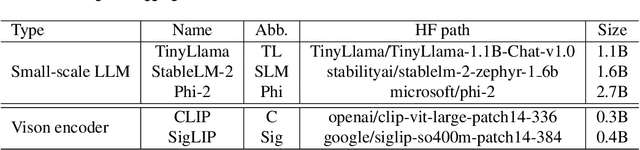
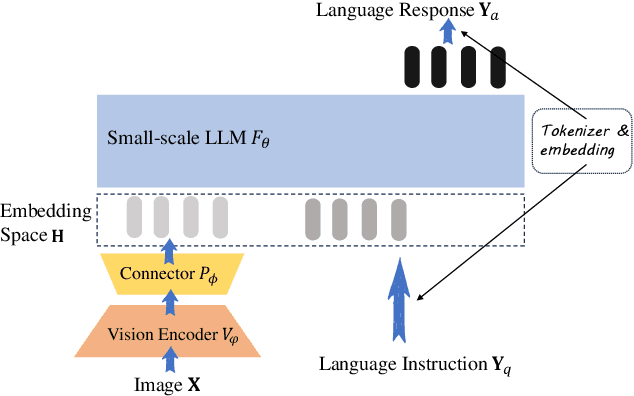

We present the TinyLLaVA framework that provides a unified perspective in designing and analyzing the small-scale Large Multimodal Models (LMMs). We empirically study the effects of different vision encoders, connection modules, language models, training data and training recipes. Our extensive experiments showed that better quality of data combined with better training recipes, smaller LMMs can consistently achieve on-par performances compared to bigger LMMs. Under our framework, we train a family of small-scale LMMs. Our best model, TinyLLaVA-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL. We hope our findings can serve as baselines for future research in terms of data scaling, training setups and model selections. Our model weights and codes will be made public.