 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-Branch Aggregation Network for Real-Time Semantic Segmentation in Street Scenes
Mar 08, 2022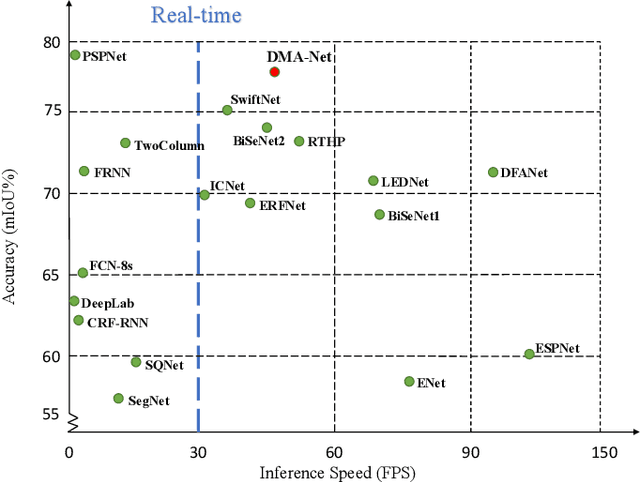


Real-time semantic segmentation, which aims to achieve high segmentation accuracy at real-time inference speed, has received substantial attention over the past few years. However, many state-of-the-art real-time semantic segmentation methods tend to sacrifice some spatial details or contextual information for fast inference, thus leading to degradation in segmentation quality. In this paper, we propose a novel Deep Multi-branch Aggregation Network (called DMA-Net) based on the encoder-decoder structure to perform real-time semantic segmentation in street scenes. Specifically, we first adopt ResNet-18 as the encoder to efficiently generate various levels of feature maps from different stages of convolutions. Then, we develop a Multi-branch Aggregation Network (MAN) as the decoder to effectively aggregate different levels of feature maps and capture the multi-scale information. In MAN, a lattice enhanced residual block is designed to enhance feature representations of the network by taking advantage of the lattice structure. Meanwhile, a feature transformation block is introduced to explicitly transform the feature map from the neighboring branch before feature aggregation. Moreover, a global context block is used to exploit the global contextual information. These key components are tightly combined and jointly optimized in a unified network. Extensive experimental results on the challenging Cityscapes and CamVid datasets demonstrate that our proposed DMA-Net respectively obtains 77.0% and 73.6% mean Intersection over Union (mIoU) at the inference speed of 46.7 FPS and 119.8 FPS by only using a single NVIDIA GTX 1080Ti GPU. This shows that DMA-Net provides a good tradeoff between segmentation quality and speed for semantic segmentation in street scenes.
Real-Time High-Performance Semantic Image Segmentation of Urban Street Scenes
Apr 03, 2020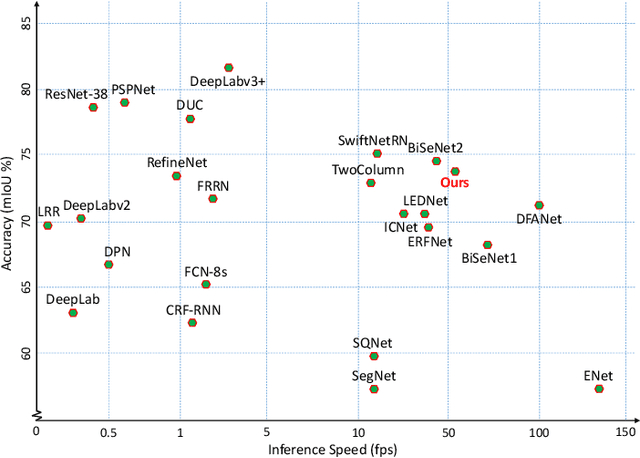


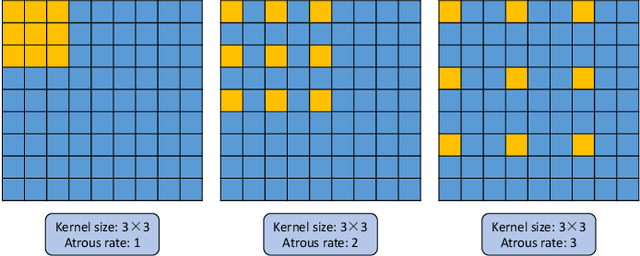
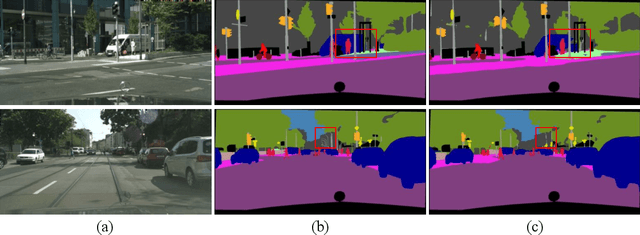
Deep Convolutional Neural Networks (DCNNs) have recently shown outstanding performance in semantic image segmentation. However, state-of-the-art DCNN-based semantic segmentation methods usually suffer from high computational complexity due to the use of complex network architectures. This greatly limits their applications in the real-world scenarios that require real-time processing. In this paper, we propose a real-time high-performance DCNN-based method for robust semantic segmentation of urban street scenes, which achieves a good trade-off between accuracy and speed. Specifically, a Lightweight Baseline Network with Atrous convolution and Attention (LBN-AA) is firstly used as our baseline network to efficiently obtain dense feature maps. Then, the Distinctive Atrous Spatial Pyramid Pooling (DASPP), which exploits the different sizes of pooling operations to encode the rich and distinctive semantic information, is developed to detect objects at multiple scales. Meanwhile, a Spatial detail-Preserving Network (SPN) with shallow convolutional layers is designed to generate high-resolution feature maps preserving the detailed spatial information. Finally, a simple but practical Feature Fusion Network (FFN) is used to effectively combine both shallow and deep features from the semantic branch (DASPP) and the spatial branch (SPN), respectively. Extensive experimental results show that the proposed method respectively achieves the accuracy of 73.6% and 68.0% mean Intersection over Union (mIoU) with the inference speed of 51.0 fps and 39.3 fps on the challenging Cityscapes and CamVid test datasets (by only using a single NVIDIA TITAN X card). This demonstrates that the proposed method offers excellent performance at the real-time speed for semantic segmentation of urban street scenes.