 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVclip: Face-based Speaker Generation by Face-voice Association Learning
Jan 06, 2026This paper discusses the task of face-based speech synthesis, a kind of personalized speech synthesis where the synthesized voices are constrained to perceptually match with a reference face image. Due to the lack of TTS-quality audio-visual corpora, previous approaches suffer from either low synthesis quality or domain mismatch induced by a knowledge transfer scheme. This paper proposes a new approach called Vclip that utilizes the facial-semantic knowledge of the CLIP encoder on noisy audio-visual data to learn the association between face and voice efficiently, achieving 89.63% cross-modal verification AUC score on Voxceleb testset. The proposed method then uses a retrieval-based strategy, combined with GMM-based speaker generation module for a downstream TTS system, to produce probable target speakers given reference images. Experimental results demonstrate that the proposed Vclip system in conjunction with the retrieval step can bridge the gap between face and voice features for face-based speech synthesis. And using the feedback information distilled from downstream TTS helps to synthesize voices that match closely with reference faces. Demos available at sos1sos2sixteen.github.io/vclip.
Kalman Filtering of Stationary Graph Signals
Sep 16, 2025In this paper, we propose a novel definition of stationary graph signals, formulated with respect to a symmetric graph shift, such as the graph Laplacian. We show that stationary graph signals can be generated by transmitting white noise through polynomial graph channels, and that their stationarity is preserved under polynomial channel transmission. In this paper, we also investigate Kalman filtering to dynamical systems characterized by polynomial state and observation matrices. We demonstrate that Kalman filtering maintains the stationarity of graph signals, while effectively incorporating both system dynamics and noise structure. In comparison to the static inverse filtering method and naive zero-signal strategy, the Kalman filtering procedure yields more accurate and adaptive signal estimates, highlighting its robustness and versatility in graph signal processing.
Blind Deconvolution of Nonstationary Graph Signals over Shift-Invariant Channels
Aug 24, 2025In this paper, we investigate blind deconvolution of nonstationary graph signals from noisy observations, transmitted through an unknown shift-invariant channel. The deconvolution process assumes that the observer has access to the covariance structure of the original graph signals. To evaluate the effectiveness of our channel estimation and blind deconvolution method, we conduct numerical experiments using a temperature dataset in the Brest region of France.
Time Travel is Cheating: Going Live with DeepFund for Real-Time Fund Investment Benchmarking
May 16, 2025Large Language Models (LLMs) have demonstrated notable capabilities across financial tasks, including financial report summarization, earnings call transcript analysis, and asset classification. However, their real-world effectiveness in managing complex fund investment remains inadequately assessed. A fundamental limitation of existing benchmarks for evaluating LLM-driven trading strategies is their reliance on historical back-testing, inadvertently enabling LLMs to "time travel"-leveraging future information embedded in their training corpora, thus resulting in possible information leakage and overly optimistic performance estimates. To address this issue, we introduce DeepFund, a live fund benchmark tool designed to rigorously evaluate LLM in real-time market conditions. Utilizing a multi-agent architecture, DeepFund connects directly with real-time stock market data-specifically data published after each model pretraining cutoff-to ensure fair and leakage-free evaluations. Empirical tests on nine flagship LLMs from leading global institutions across multiple investment dimensions-including ticker-level analysis, investment decision-making, portfolio management, and risk control-reveal significant practical challenges. Notably, even cutting-edge models such as DeepSeek-V3 and Claude-3.7-Sonnet incur net trading losses within DeepFund real-time evaluation environment, underscoring the present limitations of LLMs for active fund management. Our code is available at https://github.com/HKUSTDial/DeepFund.
EducationQ: Evaluating LLMs' Teaching Capabilities Through Multi-Agent Dialogue Framework
Apr 21, 2025Large language models (LLMs) increasingly serve as educational tools, yet evaluating their teaching capabilities remains challenging due to the resource-intensive, context-dependent, and methodologically complex nature of teacher-student interactions. We introduce EducationQ, a multi-agent dialogue framework that efficiently assesses teaching capabilities through simulated dynamic educational scenarios, featuring specialized agents for teaching, learning, and evaluation. Testing 14 LLMs across major AI Organizations (OpenAI, Meta, Google, Anthropic, and others) on 1,498 questions spanning 13 disciplines and 10 difficulty levels reveals that teaching effectiveness does not correlate linearly with model scale or general reasoning capabilities - with some smaller open-source models outperforming larger commercial counterparts in teaching contexts. This finding highlights a critical gap in current evaluations that prioritize knowledge recall over interactive pedagogy. Our mixed-methods evaluation, combining quantitative metrics with qualitative analysis and expert case studies, identifies distinct pedagogical strengths employed by top-performing models (e.g., sophisticated questioning strategies, adaptive feedback mechanisms). Human expert evaluations show 78% agreement with our automated qualitative analysis of effective teaching behaviors, validating our methodology. EducationQ demonstrates that LLMs-as-teachers require specialized optimization beyond simple scaling, suggesting next-generation educational AI prioritize targeted enhancement of specific pedagogical effectiveness.
ViDTA: Enhanced Drug-Target Affinity Prediction via Virtual Graph Nodes and Attention-based Feature Fusion
Dec 27, 2024



Drug-target interaction is fundamental in understanding how drugs affect biological systems, and accurately predicting drug-target affinity (DTA) is vital for drug discovery. Recently, deep learning methods have emerged as a significant approach for estimating the binding strength between drugs and target proteins. However, existing methods simply utilize the drug's local information from molecular topology rather than global information. Additionally, the features of drugs and proteins are usually fused with a simple concatenation operation, limiting their effectiveness. To address these challenges, we proposed ViDTA, an enhanced DTA prediction framework. We introduce virtual nodes into the Graph Neural Network (GNN)-based drug feature extraction network, which acts as a global memory to exchange messages more efficiently. By incorporating virtual graph nodes, we seamlessly integrate local and global features of drug molecular structures, expanding the GNN's receptive field. Additionally, we propose an attention-based linear feature fusion network for better capturing the interaction information between drugs and proteins. Experimental results evaluated on various benchmarks including Davis, Metz, and KIBA demonstrate that our proposed ViDTA outperforms the state-of-the-art baselines.
Distributed satellite information networks: Architecture, enabling technologies, and trends
Dec 17, 2024



Driven by the vision of ubiquitous connectivity and wireless intelligence, the evolution of ultra-dense constellation-based satellite-integrated Internet is underway, now taking preliminary shape. Nevertheless, the entrenched institutional silos and limited, nonrenewable heterogeneous network resources leave current satellite systems struggling to accommodate the escalating demands of next-generation intelligent applications. In this context, the distributed satellite information networks (DSIN), exemplified by the cohesive clustered satellites system, have emerged as an innovative architecture, bridging information gaps across diverse satellite systems, such as communication, navigation, and remote sensing, and establishing a unified, open information network paradigm to support resilient space information services. This survey first provides a profound discussion about innovative network architectures of DSIN, encompassing distributed regenerative satellite network architecture, distributed satellite computing network architecture, and reconfigurable satellite formation flying, to enable flexible and scalable communication, computing and control. The DSIN faces challenges from network heterogeneity, unpredictable channel dynamics, sparse resources, and decentralized collaboration frameworks. To address these issues, a series of enabling technologies is identified, including channel modeling and estimation, cloud-native distributed MIMO cooperation, grant-free massive access, network routing, and the proper combination of all these diversity techniques. Furthermore, to heighten the overall resource efficiency, the cross-layer optimization techniques are further developed to meet upper-layer deterministic, adaptive and secure information services requirements. In addition, emerging research directions and new opportunities are highlighted on the way to achieving the DSIN vision.
Adversarial Attacks and Robust Defenses in Speaker Embedding based Zero-Shot Text-to-Speech System
Oct 05, 2024Speaker embedding based zero-shot Text-to-Speech (TTS) systems enable high-quality speech synthesis for unseen speakers using minimal data. However, these systems are vulnerable to adversarial attacks, where an attacker introduces imperceptible perturbations to the original speaker's audio waveform, leading to synthesized speech sounds like another person. This vulnerability poses significant security risks, including speaker identity spoofing and unauthorized voice manipulation. This paper investigates two primary defense strategies to address these threats: adversarial training and adversarial purification. Adversarial training enhances the model's robustness by integrating adversarial examples during the training process, thereby improving resistance to such attacks. Adversarial purification, on the other hand, employs diffusion probabilistic models to revert adversarially perturbed audio to its clean form. Experimental results demonstrate that these defense mechanisms can significantly reduce the impact of adversarial perturbations, enhancing the security and reliability of speaker embedding based zero-shot TTS systems in adversarial environments.
BiSinger: Bilingual Singing Voice Synthesis
Sep 29, 2023



Although Singing Voice Synthesis (SVS) has made great strides with Text-to-Speech (TTS) techniques, multilingual singing voice modeling remains relatively unexplored. This paper presents BiSinger, a bilingual pop SVS system for English and Chinese Mandarin. Current systems require separate models per language and cannot accurately represent both Chinese and English, hindering code-switch SVS. To address this gap, we design a shared representation between Chinese and English singing voices, achieved by using the CMU dictionary with mapping rules. We fuse monolingual singing datasets with open-source singing voice conversion techniques to generate bilingual singing voices while also exploring the potential use of bilingual speech data. Experiments affirm that our language-independent representation and incorporation of related datasets enable a single model with enhanced performance in English and code-switch SVS while maintaining Chinese song performance. Audio samples are available at https://bisinger-svs.github.io.
VoiceLens: Controllable Speaker Generation and Editing with Flow
Sep 25, 2023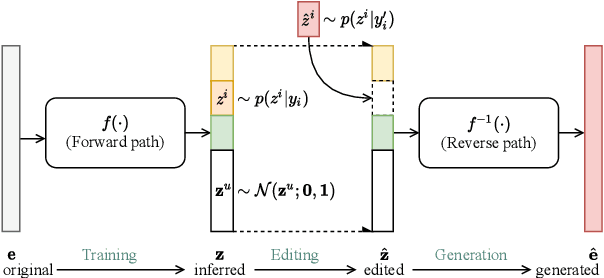
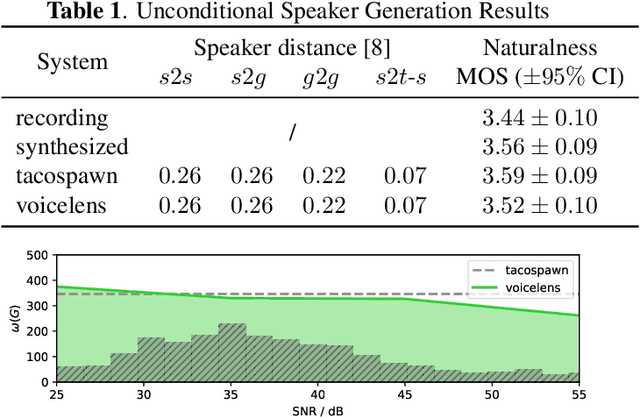

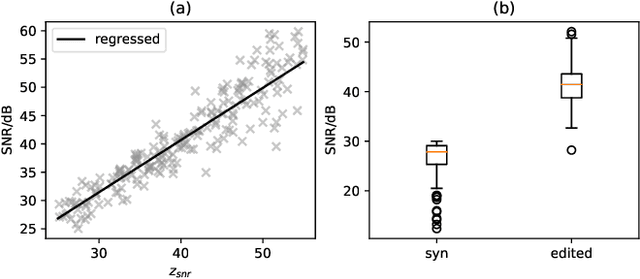
Currently, many multi-speaker speech synthesis and voice conversion systems address speaker variations with an embedding vector. Modeling it directly allows new voices outside of training data to be synthesized. GMM based approaches such as Tacospawn are favored in literature for this generation task, but there are still some limitations when difficult conditionings are involved. In this paper, we propose VoiceLens, a semi-supervised flow-based approach, to model speaker embedding distributions for multi-conditional speaker generation. VoiceLens maps speaker embeddings into a combination of independent attributes and residual information. It allows new voices associated with certain attributes to be \textit{generated} for existing TTS models, and attributes of known voices to be meaningfully \textit{edited}. We show in this paper, VoiceLens displays an unconditional generation capacity that is similar to Tacospawn while obtaining higher controllability and flexibility when used in a conditional manner. In addition, we show synthesizing less noisy speech from known noisy speakers without re-training the TTS model is possible via solely editing their embeddings with a SNR conditioned VoiceLens model. Demos are available at sos1sos2sixteen.github.io/voicelens.