 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceLens: Controllable Speaker Generation and Editing with Flow
Paper and Code
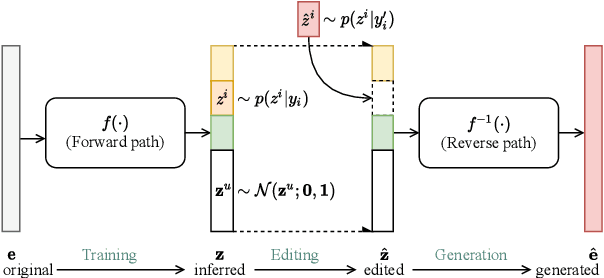
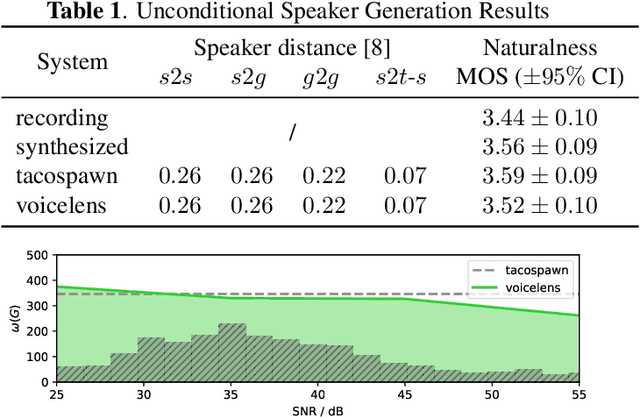

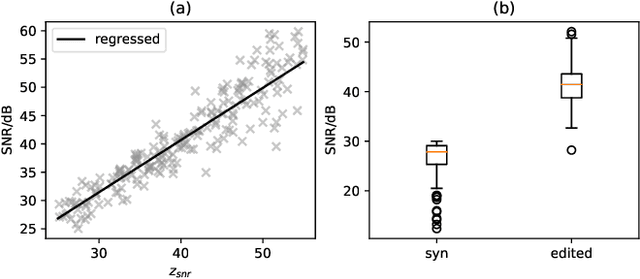
Currently, many multi-speaker speech synthesis and voice conversion systems address speaker variations with an embedding vector. Modeling it directly allows new voices outside of training data to be synthesized. GMM based approaches such as Tacospawn are favored in literature for this generation task, but there are still some limitations when difficult conditionings are involved. In this paper, we propose VoiceLens, a semi-supervised flow-based approach, to model speaker embedding distributions for multi-conditional speaker generation. VoiceLens maps speaker embeddings into a combination of independent attributes and residual information. It allows new voices associated with certain attributes to be \textit{generated} for existing TTS models, and attributes of known voices to be meaningfully \textit{edited}. We show in this paper, VoiceLens displays an unconditional generation capacity that is similar to Tacospawn while obtaining higher controllability and flexibility when used in a conditional manner. In addition, we show synthesizing less noisy speech from known noisy speakers without re-training the TTS model is possible via solely editing their embeddings with a SNR conditioned VoiceLens model. Demos are available at sos1sos2sixteen.github.io/voicelens.