 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre GUI Agents Focused Enough? Automated Distraction via Semantic-level UI Element Injection
Apr 09, 2026Existing red-teaming studies on GUI agents have important limitations. Adversarial perturbations typically require white-box access, which is unavailable for commercial systems, while prompt injection is increasingly mitigated by stronger safety alignment. To study robustness under a more practical threat model, we propose Semantic-level UI Element Injection, a red-teaming setting that overlays safety-aligned and harmless UI elements onto screenshots to misdirect the agent's visual grounding. Our method uses a modular Editor-Overlapper-Victim pipeline and an iterative search procedure that samples multiple candidate edits, keeps the best cumulative overlay, and adapts future prompt strategies based on previous failures. Across five victim models, our optimized attacks improve attack success rate by up to 4.4x over random injection on the strongest victims. Moreover, elements optimized on one source model transfer effectively to other target models, indicating model-agnostic vulnerabilities. After the first successful attack, the victim still clicks the attacker-controlled element in more than 15% of later independent trials, versus below 1% for random injection, showing that the injected element acts as a persistent attractor rather than simple visual clutter.
Heddle: A Distributed Orchestration System for Agentic RL Rollout
Mar 30, 2026Agentic Reinforcement Learning (RL) enables LLMs to solve complex tasks by alternating between a data-collection rollout phase and a policy training phase. During rollout, the agent generates trajectories, i.e., multi-step interactions between LLMs and external tools. Yet, frequent tool calls induce long-tailed trajectory generation that bottlenecks rollouts. This stems from step-centric designs that ignore trajectory context, triggering three system problems for long-tail trajectory generation: queueing delays, interference overhead, and inflated per-token time. We propose Heddle, a trajectory-centric system to optimize the when, where, and how of agentic rollout execution. Heddle integrates three core mechanisms: trajectory-level scheduling using runtime prediction and progressive priority to minimize cumulative queueing; trajectory-aware placement via presorted dynamic programming and opportunistic migration during idle tool call intervals to minimize interference; and trajectory-adaptive resource manager that dynamically tunes model parallelism to accelerate the per-token time of long-tail trajectories while maintaining high throughput for short trajectories. Evaluations across diverse agentic RL workloads demonstrate that Heddle effectively neutralizes the long-tail bottleneck, achieving up to 2.5$\times$ higher end-to-end rollout throughput compared to state-of-the-art baselines.
MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production
May 19, 2025We present MegaScale-MoE, a production system tailored for the efficient training of large-scale mixture-of-experts (MoE) models. MoE emerges as a promising architecture to scale large language models (LLMs) to unprecedented sizes, thereby enhancing model performance. However, existing MoE training systems experience a degradation in training efficiency, exacerbated by the escalating scale of MoE models and the continuous evolution of hardware. Recognizing the pivotal role of efficient communication in enhancing MoE training, MegaScale-MoE customizes communication-efficient parallelism strategies for attention and FFNs in each MoE layer and adopts a holistic approach to overlap communication with computation at both inter- and intra-operator levels. Additionally, MegaScale-MoE applies communication compression with adjusted communication patterns to lower precision, further improving training efficiency. When training a 352B MoE model on 1,440 NVIDIA Hopper GPUs, MegaScale-MoE achieves a training throughput of 1.41M tokens/s, improving the efficiency by 1.88$\times$ compared to Megatron-LM. We share our operational experience in accelerating MoE training and hope that by offering our insights in system design, this work will motivate future research in MoE systems.
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Apr 22, 2025Reinforcement learning (RL) has become the core post-training technique for large language models (LLMs). RL for LLMs involves two stages: generation and training. The LLM first generates samples online, which are then used to derive rewards for training. The conventional view holds that the colocated architecture, where the two stages share resources via temporal multiplexing, outperforms the disaggregated architecture, in which dedicated resources are assigned to each stage. However, in real-world deployments, we observe that the colocated architecture suffers from resource coupling, where the two stages are constrained to use the same resources. This coupling compromises the scalability and cost-efficiency of colocated RL in large-scale training. In contrast, the disaggregated architecture allows for flexible resource allocation, supports heterogeneous training setups, and facilitates cross-datacenter deployment. StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching and scheduling. Experiments show that StreamRL improves throughput by up to 2.66x compared to existing state-of-the-art systems, and improves cost-effectiveness by up to 1.33x in a heterogeneous, cross-datacenter setting.
Task Assignment and Exploration Optimization for Low Altitude UAV Rescue via Generative AI Enhanced Multi-agent Reinforcement Learning
Apr 18, 2025Artificial Intelligence (AI)-driven convolutional neural networks enhance rescue, inspection, and surveillance tasks performed by low-altitude uncrewed aerial vehicles (UAVs) and ground computing nodes (GCNs) in unknown environments. However, their high computational demands often exceed a single UAV's capacity, leading to system instability, further exacerbated by the limited and dynamic resources of GCNs. To address these challenges, this paper proposes a novel cooperation framework involving UAVs, ground-embedded robots (GERs), and high-altitude platforms (HAPs), which enable resource pooling through UAV-to-GER (U2G) and UAV-to-HAP (U2H) communications to provide computing services for UAV offloaded tasks. Specifically, we formulate the multi-objective optimization problem of task assignment and exploration optimization in UAVs as a dynamic long-term optimization problem. Our objective is to minimize task completion time and energy consumption while ensuring system stability over time. To achieve this, we first employ the Lyapunov optimization technique to transform the original problem, with stability constraints, into a per-slot deterministic problem. We then propose an algorithm named HG-MADDPG, which combines the Hungarian algorithm with a generative diffusion model (GDM)-based multi-agent deep deterministic policy gradient (MADDPG) approach. We first introduce the Hungarian algorithm as a method for exploration area selection, enhancing UAV efficiency in interacting with the environment. We then innovatively integrate the GDM and multi-agent deep deterministic policy gradient (MADDPG) to optimize task assignment decisions, such as task offloading and resource allocation. Simulation results demonstrate the effectiveness of the proposed approach, with significant improvements in task offloading efficiency, latency reduction, and system stability compared to baseline methods.
MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism
Apr 03, 2025



Mixture-of-Experts (MoE) showcases tremendous potential to scale large language models (LLMs) with enhanced performance and reduced computational complexity. However, its sparsely activated architecture shifts feed-forward networks (FFNs) from being compute-intensive to memory-intensive during inference, leading to substantially lower GPU utilization and increased operational costs. We present MegaScale-Infer, an efficient and cost-effective system for serving large-scale MoE models. MegaScale-Infer disaggregates attention and FFN modules within each model layer, enabling independent scaling, tailored parallelism strategies, and heterogeneous deployment for both modules. To fully exploit disaggregation in the presence of MoE's sparsity, MegaScale-Infer introduces ping-pong pipeline parallelism, which partitions a request batch into micro-batches and shuttles them between attention and FFNs for inference. Combined with distinct model parallelism for each module, MegaScale-Infer effectively hides communication overhead and maximizes GPU utilization. To adapt to disaggregated attention and FFN modules and minimize data transmission overhead (e.g., token dispatch), MegaScale-Infer provides a high-performance M2N communication library that eliminates unnecessary GPU-to-CPU data copies, group initialization overhead, and GPU synchronization. Experimental results indicate that MegaScale-Infer achieves up to 1.90x higher per-GPU throughput than state-of-the-art solutions.
From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
May 09, 2024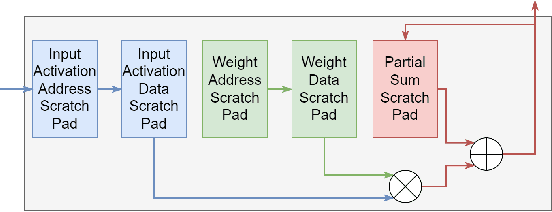
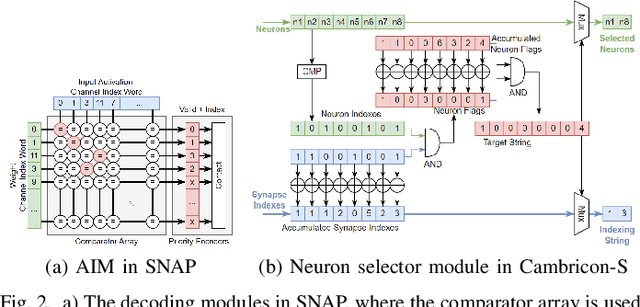
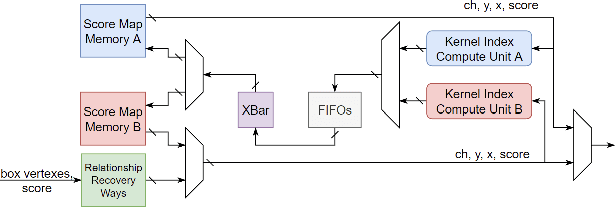

Deep neural networks (DNNs) have been widely used in many artificial intelligence (AI) tasks. However, deploying them brings significant challenges due to the huge cost of memory, energy, and computation. To address these challenges, researchers have developed various model compression techniques such as model quantization and model pruning. Recently, there has been a surge in research of compression methods to achieve model efficiency while retaining the performance. Furthermore, more and more works focus on customizing the DNN hardware accelerators to better leverage the model compression techniques. In addition to efficiency, preserving security and privacy is critical for deploying DNNs. However, the vast and diverse body of related works can be overwhelming. This inspires us to conduct a comprehensive survey on recent research toward the goal of high-performance, cost-efficient, and safe deployment of DNNs. Our survey first covers the mainstream model compression techniques such as model quantization, model pruning, knowledge distillation, and optimizations of non-linear operations. We then introduce recent advances in designing hardware accelerators that can adapt to efficient model compression approaches. Additionally, we discuss how homomorphic encryption can be integrated to secure DNN deployment. Finally, we discuss several issues, such as hardware evaluation, generalization, and integration of various compression approaches. Overall, we aim to provide a big picture of efficient DNNs, from algorithm to hardware accelerators and security perspectives.
RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation
Apr 18, 2024



Retrieval-Augmented Generation (RAG) has shown significant improvements in various natural language processing tasks by integrating the strengths of large language models (LLMs) and external knowledge databases. However, RAG introduces long sequence generation and leads to high computation and memory costs. We propose Thoth, a novel multilevel dynamic caching system tailored for RAG. Our analysis benchmarks current RAG systems, pinpointing the performance bottleneck (i.e., long sequence due to knowledge injection) and optimization opportunities (i.e., caching knowledge's intermediate states). Based on these insights, we design Thoth, which organizes the intermediate states of retrieved knowledge in a knowledge tree and caches them in the GPU and host memory hierarchy. Thoth proposes a replacement policy that is aware of LLM inference characteristics and RAG retrieval patterns. It also dynamically overlaps the retrieval and inference steps to minimize the end-to-end latency. We implement Thoth and evaluate it on vLLM, a state-of-the-art LLM inference system and Faiss, a state-of-the-art vector database. The experimental results show that Thoth reduces the time to first token (TTFT) by up to 4x and improves the throughput by up to 2.1x compared to vLLM integrated with Faiss.
Portrait Diffusion: Training-free Face Stylization with Chain-of-Painting
Dec 03, 2023Face stylization refers to the transformation of a face into a specific portrait style. However, current methods require the use of example-based adaptation approaches to fine-tune pre-trained generative models so that they demand lots of time and storage space and fail to achieve detailed style transformation. This paper proposes a training-free face stylization framework, named Portrait Diffusion. This framework leverages off-the-shelf text-to-image diffusion models, eliminating the need for fine-tuning specific examples. Specifically, the content and style images are first inverted into latent codes. Then, during image reconstruction using the corresponding latent code, the content and style features in the attention space are delicately blended through a modified self-attention operation called Style Attention Control. Additionally, a Chain-of-Painting method is proposed for the gradual redrawing of unsatisfactory areas from rough adjustments to fine-tuning. Extensive experiments validate the effectiveness of our Portrait Diffusion method and demonstrate the superiority of Chain-of-Painting in achieving precise face stylization. Code will be released at \url{https://github.com/liujin112/PortraitDiffusion}.
Punctate White Matter Lesion Segmentation in Preterm Infants Powered by Counterfactually Generative Learning
Sep 07, 2023Accurate segmentation of punctate white matter lesions (PWMLs) are fundamental for the timely diagnosis and treatment of related developmental disorders. Automated PWMLs segmentation from infant brain MR images is challenging, considering that the lesions are typically small and low-contrast, and the number of lesions may dramatically change across subjects. Existing learning-based methods directly apply general network architectures to this challenging task, which may fail to capture detailed positional information of PWMLs, potentially leading to severe under-segmentations. In this paper, we propose to leverage the idea of counterfactual reasoning coupled with the auxiliary task of brain tissue segmentation to learn fine-grained positional and morphological representations of PWMLs for accurate localization and segmentation. A simple and easy-to-implement deep-learning framework (i.e., DeepPWML) is accordingly designed. It combines the lesion counterfactual map with the tissue probability map to train a lightweight PWML segmentation network, demonstrating state-of-the-art performance on a real-clinical dataset of infant T1w MR images. The code is available at \href{https://github.com/ladderlab-xjtu/DeepPWML}{https://github.com/ladderlab-xjtu/DeepPWML}.