 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation
Apr 18, 2024



Retrieval-Augmented Generation (RAG) has shown significant improvements in various natural language processing tasks by integrating the strengths of large language models (LLMs) and external knowledge databases. However, RAG introduces long sequence generation and leads to high computation and memory costs. We propose Thoth, a novel multilevel dynamic caching system tailored for RAG. Our analysis benchmarks current RAG systems, pinpointing the performance bottleneck (i.e., long sequence due to knowledge injection) and optimization opportunities (i.e., caching knowledge's intermediate states). Based on these insights, we design Thoth, which organizes the intermediate states of retrieved knowledge in a knowledge tree and caches them in the GPU and host memory hierarchy. Thoth proposes a replacement policy that is aware of LLM inference characteristics and RAG retrieval patterns. It also dynamically overlaps the retrieval and inference steps to minimize the end-to-end latency. We implement Thoth and evaluate it on vLLM, a state-of-the-art LLM inference system and Faiss, a state-of-the-art vector database. The experimental results show that Thoth reduces the time to first token (TTFT) by up to 4x and improves the throughput by up to 2.1x compared to vLLM integrated with Faiss.
XMP-Font: Self-Supervised Cross-Modality Pre-training for Few-Shot Font Generation
Apr 11, 2022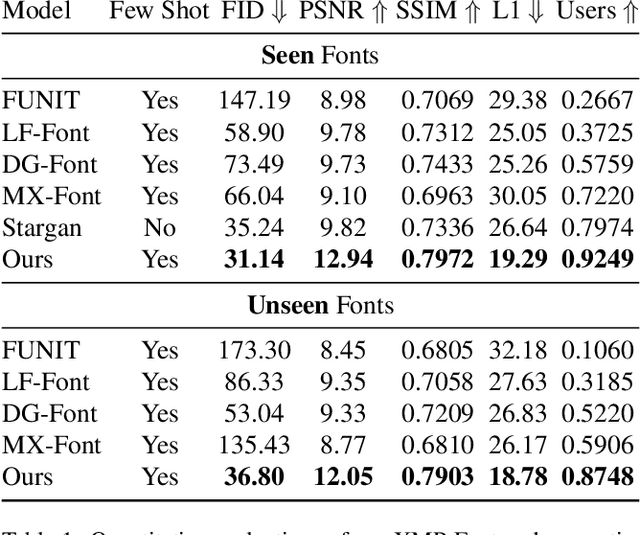
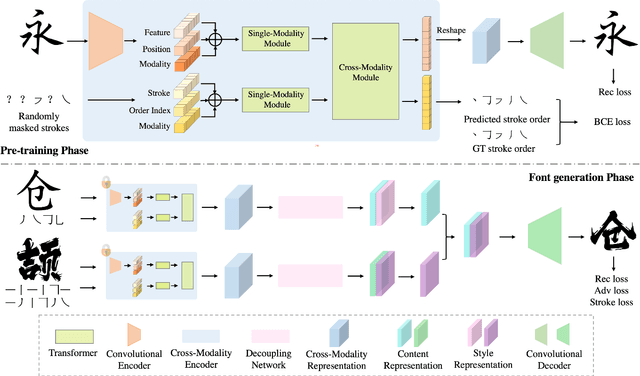
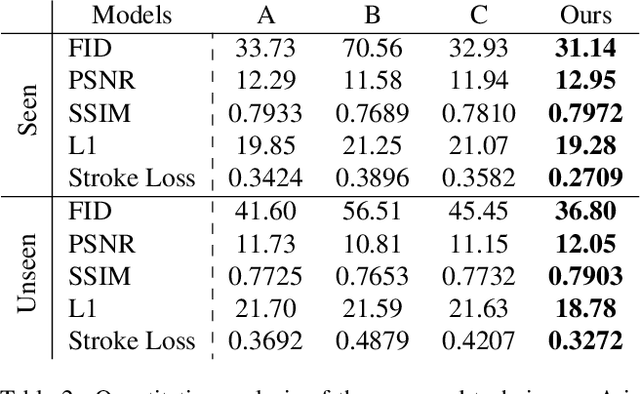
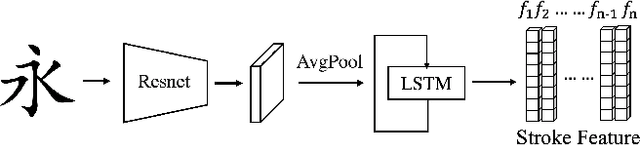
Generating a new font library is a very labor-intensive and time-consuming job for glyph-rich scripts. Few-shot font generation is thus required, as it requires only a few glyph references without fine-tuning during test. Existing methods follow the style-content disentanglement paradigm and expect novel fonts to be produced by combining the style codes of the reference glyphs and the content representations of the source. However, these few-shot font generation methods either fail to capture content-independent style representations, or employ localized component-wise style representations, which is insufficient to model many Chinese font styles that involve hyper-component features such as inter-component spacing and "connected-stroke". To resolve these drawbacks and make the style representations more reliable, we propose a self-supervised cross-modality pre-training strategy and a cross-modality transformer-based encoder that is conditioned jointly on the glyph image and the corresponding stroke labels. The cross-modality encoder is pre-trained in a self-supervised manner to allow effective capture of cross- and intra-modality correlations, which facilitates the content-style disentanglement and modeling style representations of all scales (stroke-level, component-level and character-level). The pre-trained encoder is then applied to the downstream font generation task without fine-tuning. Experimental comparisons of our method with state-of-the-art methods demonstrate our method successfully transfers styles of all scales. In addition, it only requires one reference glyph and achieves the lowest rate of bad cases in the few-shot font generation task 28% lower than the second best