 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-KV: Redundancy-aware KV Cache Compression for Training-Free Reasoning Models Acceleration
May 30, 2025Reasoning models have demonstrated impressive performance in self-reflection and chain-of-thought reasoning. However, they often produce excessively long outputs, leading to prohibitively large key-value (KV) caches during inference. While chain-of-thought inference significantly improves performance on complex reasoning tasks, it can also lead to reasoning failures when deployed with existing KV cache compression approaches. To address this, we propose Redundancy-aware KV Cache Compression for Reasoning models (R-KV), a novel method specifically targeting redundant tokens in reasoning models. Our method preserves nearly 100% of the full KV cache performance using only 10% of the KV cache, substantially outperforming existing KV cache baselines, which reach only 60% of the performance. Remarkably, R-KV even achieves 105% of full KV cache performance with 16% of the KV cache. This KV-cache reduction also leads to a 90% memory saving and a 6.6X throughput over standard chain-of-thought reasoning inference. Experimental results show that R-KV consistently outperforms existing KV cache compression baselines across two mathematical reasoning datasets.
HeadInfer: Memory-Efficient LLM Inference by Head-wise Offloading
Feb 18, 2025



Transformer-based large language models (LLMs) demonstrate impressive performance in long context generation. Extending the context length has disproportionately shifted the memory footprint of LLMs during inference to the key-value cache (KV cache). In this paper, we propose HEADINFER, which offloads the KV cache to CPU RAM while avoiding the need to fully store the KV cache for any transformer layer on the GPU. HEADINFER employs a fine-grained, head-wise offloading strategy, maintaining only selective attention heads KV cache on the GPU while computing attention output dynamically. Through roofline analysis, we demonstrate that HEADINFER maintains computational efficiency while significantly reducing memory footprint. We evaluate HEADINFER on the Llama-3-8B model with a 1-million-token sequence, reducing the GPU memory footprint of the KV cache from 128 GB to 1 GB and the total GPU memory usage from 207 GB to 17 GB, achieving a 92% reduction compared to BF16 baseline inference. Notably, HEADINFER enables 4-million-token inference with an 8B model on a single consumer GPU with 24GB memory (e.g., NVIDIA RTX 4090) without approximation methods.
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference
Oct 28, 2024With the widespread deployment of long-context large language models (LLMs), there has been a growing demand for efficient support of high-throughput inference. However, as the key-value (KV) cache expands with the sequence length, the increasing memory footprint and the need to access it for each token generation both result in low throughput when serving long-context LLMs. While various dynamic sparse attention methods have been proposed to speed up inference while maintaining generation quality, they either fail to sufficiently reduce GPU memory consumption or introduce significant decoding latency by offloading the KV cache to the CPU. We present ShadowKV, a high-throughput long-context LLM inference system that stores the low-rank key cache and offloads the value cache to reduce the memory footprint for larger batch sizes and longer sequences. To minimize decoding latency, ShadowKV employs an accurate KV selection strategy that reconstructs minimal sparse KV pairs on-the-fly. By evaluating ShadowKV on a broad range of benchmarks, including RULER, LongBench, and Needle In A Haystack, and models like Llama-3.1-8B, Llama-3-8B-1M, GLM-4-9B-1M, Yi-9B-200K, Phi-3-Mini-128K, and Qwen2-7B-128K, we demonstrate that it can support up to 6$\times$ larger batch sizes and boost throughput by up to 3.04$\times$ on an A100 GPU without sacrificing accuracy, even surpassing the performance achievable with infinite batch size under the assumption of infinite GPU memory. The code is available at https://github.com/bytedance/ShadowKV.
Fast Best-of-N Decoding via Speculative Rejection
Oct 26, 2024



The safe and effective deployment of Large Language Models (LLMs) involves a critical step called alignment, which ensures that the model's responses are in accordance with human preferences. Prevalent alignment techniques, such as DPO, PPO and their variants, align LLMs by changing the pre-trained model weights during a phase called post-training. While predominant, these post-training methods add substantial complexity before LLMs can be deployed. Inference-time alignment methods avoid the complex post-training step and instead bias the generation towards responses that are aligned with human preferences. The best-known inference-time alignment method, called Best-of-N, is as effective as the state-of-the-art post-training procedures. Unfortunately, Best-of-N requires vastly more resources at inference time than standard decoding strategies, which makes it computationally not viable. In this work, we introduce Speculative Rejection, a computationally-viable inference-time alignment algorithm. It generates high-scoring responses according to a given reward model, like Best-of-N does, while being between 16 to 32 times more computationally efficient.
TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
Apr 18, 2024With large language models (LLMs) widely deployed in long content generation recently, there has emerged an increasing demand for efficient long-sequence inference support. However, key-value (KV) cache, which is stored to avoid re-computation, has emerged as a critical bottleneck by growing linearly in size with the sequence length. Due to the auto-regressive nature of LLMs, the entire KV cache will be loaded for every generated token, resulting in low utilization of computational cores and high latency. While various compression methods for KV cache have been proposed to alleviate this issue, they suffer from degradation in generation quality. We introduce TriForce, a hierarchical speculative decoding system that is scalable to long sequence generation. This approach leverages the original model weights and dynamic sparse KV cache via retrieval as a draft model, which serves as an intermediate layer in the hierarchy and is further speculated by a smaller model to reduce its drafting latency. TriForce not only facilitates impressive speedups for Llama2-7B-128K, achieving up to 2.31$\times$ on an A100 GPU but also showcases scalability in handling even longer contexts. For the offloading setting on two RTX 4090 GPUs, TriForce achieves 0.108s/token$\unicode{x2014}$only half as slow as the auto-regressive baseline on an A100, which attains 7.78$\times$ on our optimized offloading system. Additionally, TriForce performs 4.86$\times$ than DeepSpeed-Zero-Inference on a single RTX 4090 GPU. TriForce's robustness is highlighted by its consistently outstanding performance across various temperatures. The code is available at https://github.com/Infini-AI-Lab/TriForce.
BMAD: Benchmarks for Medical Anomaly Detection
Jun 28, 2023Anomaly detection (AD) is a fundamental research problem in machine learning and computer vision, with practical applications in industrial inspection, video surveillance, and medical diagnosis. In medical imaging, AD is especially vital for detecting and diagnosing anomalies that may indicate rare diseases or conditions. However, there is a lack of a universal and fair benchmark for evaluating AD methods on medical images, which hinders the development of more generalized and robust AD methods in this specific domain. To bridge this gap, we introduce a comprehensive evaluation benchmark for assessing anomaly detection methods on medical images. This benchmark encompasses six reorganized datasets from five medical domains (i.e. brain MRI, liver CT, retinal OCT, chest X-ray, and digital histopathology) and three key evaluation metrics, and includes a total of fourteen state-of-the-art AD algorithms. This standardized and well-curated medical benchmark with the well-structured codebase enables comprehensive comparisons among recently proposed anomaly detection methods. It will facilitate the community to conduct a fair comparison and advance the field of AD on medical imaging. More information on BMAD is available in our GitHub repository: https://github.com/DorisBao/BMAD
Arrhythmia Classifier Based on Ultra-Lightweight Binary Neural Network
Apr 04, 2023Reasonably and effectively monitoring arrhythmias through ECG signals has significant implications for human health. With the development of deep learning, numerous ECG classification algorithms based on deep learning have emerged. However, most existing algorithms trade off high accuracy for complex models, resulting in high storage usage and power consumption. This also inevitably increases the difficulty of implementation on wearable Artificial Intelligence-of-Things (AIoT) devices with limited resources. In this study, we proposed a universally applicable ultra-lightweight binary neural network(BNN) that is capable of 5-class and 17-class arrhythmia classification based on ECG signals. Our BNN achieves 96.90% (full precision 97.09%) and 97.50% (full precision 98.00%) accuracy for 5-class and 17-class classification, respectively, with state-of-the-art storage usage (3.76 KB and 4.45 KB). Compared to other binarization works, our approach excels in supporting two multi-classification modes while achieving the smallest known storage space. Moreover, our model achieves optimal accuracy in 17-class classification and boasts an elegantly simple network architecture. The algorithm we use is optimized specifically for hardware implementation. Our research showcases the potential of lightweight deep learning models in the healthcare industry, specifically in wearable medical devices, which hold great promise for improving patient outcomes and quality of life. Code is available on: https://github.com/xpww/ECG_BNN_Net
Arrhythmia Classifier using Binarized Convolutional Neural Network for Resource-Constrained Devices
May 13, 2022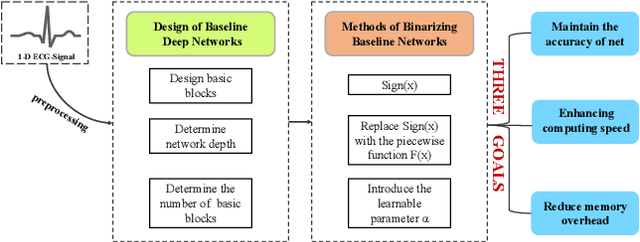
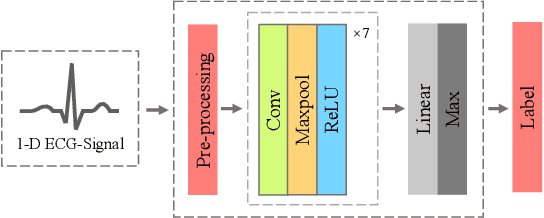
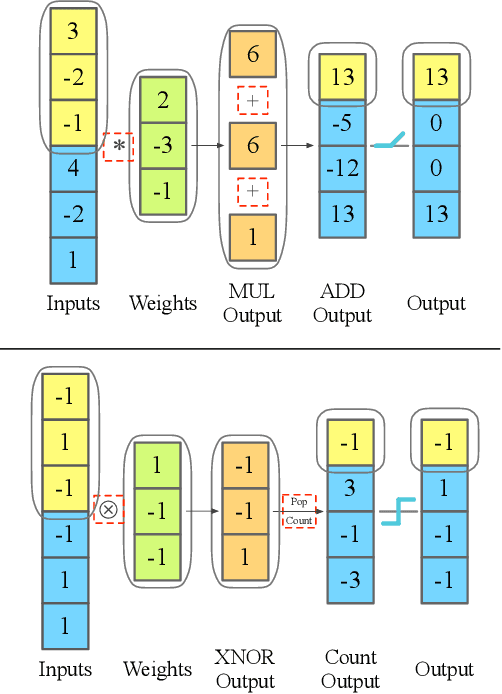
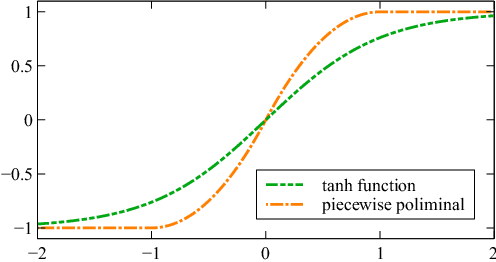
Monitoring electrocardiogram signals is of great significance for the diagnosis of arrhythmias. In recent years, deep learning and convolutional neural networks have been widely used in the classification of cardiac arrhythmias. However, the existing neural network applied to ECG signal detection usually requires a lot of computing resources, which is not friendlyF to resource-constrained equipment, and it is difficult to realize real-time monitoring. In this paper, a binarized convolutional neural network suitable for ECG monitoring is proposed, which is hardware-friendly and more suitable for use in resource-constrained wearable devices. Targeting the MIT-BIH arrhythmia database, the classifier based on this network reached an accuracy of 95.67% in the five-class test. Compared with the proposed baseline full-precision network with an accuracy of 96.45%, it is only 0.78% lower. Importantly, it achieves 12.65 times the computing speedup, 24.8 times the storage compression ratio, and only requires a quarter of the memory overhead.
Arrhythmia Classifier Using Convolutional Neural Network with Adaptive Loss-aware Multi-bit Networks Quantization
Feb 27, 2022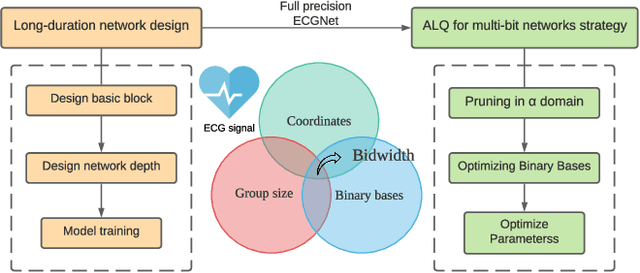
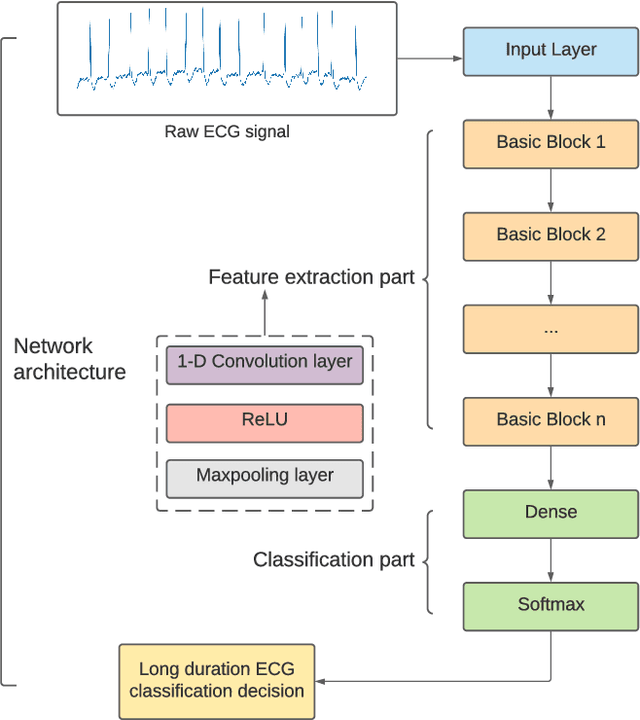


Cardiovascular disease (CVDs) is one of the universal deadly diseases, and the detection of it in the early stage is a challenging task to tackle. Recently, deep learning and convolutional neural networks have been employed widely for the classification of objects. Moreover, it is promising that lots of networks can be deployed on wearable devices. An increasing number of methods can be used to realize ECG signal classification for the sake of arrhythmia detection. However, the existing neural networks proposed for arrhythmia detection are not hardware-friendly enough due to a remarkable quantity of parameters resulting in memory and power consumption. In this paper, we present a 1-D adaptive loss-aware quantization, achieving a high compression rate that reduces memory consumption by 23.36 times. In order to adapt to our compression method, we need a smaller and simpler network. We propose a 17 layer end-to-end neural network classifier to classify 17 different rhythm classes trained on the MIT-BIH dataset, realizing a classification accuracy of 93.5%, which is higher than most existing methods. Due to the adaptive bitwidth method making important layers get more attention and offered a chance to prune useless parameters, the proposed quantization method avoids accuracy degradation. It even improves the accuracy rate, which is 95.84%, 2.34% higher than before. Our study achieves a 1-D convolutional neural network with high performance and low resources consumption, which is hardware-friendly and illustrates the possibility of deployment on wearable devices to realize a real-time arrhythmia diagnosis.