 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
Jan 10, 2024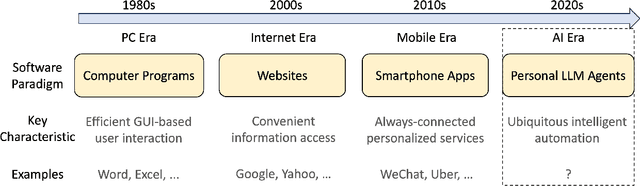
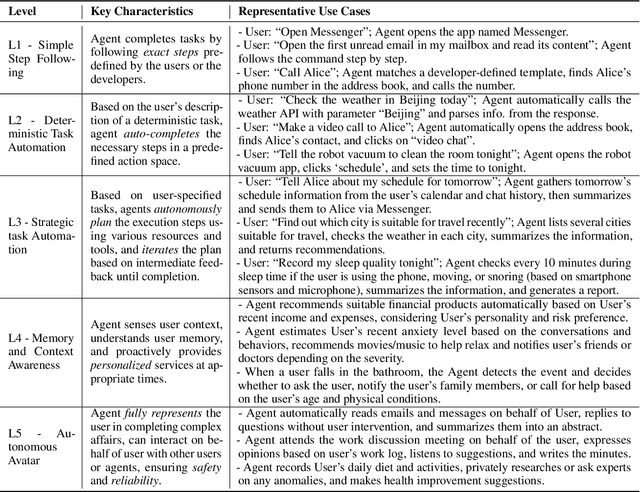
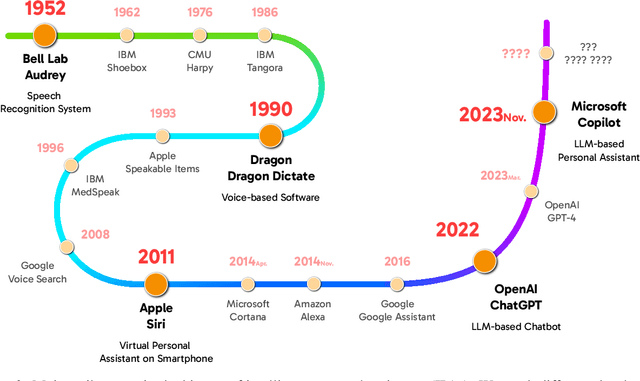
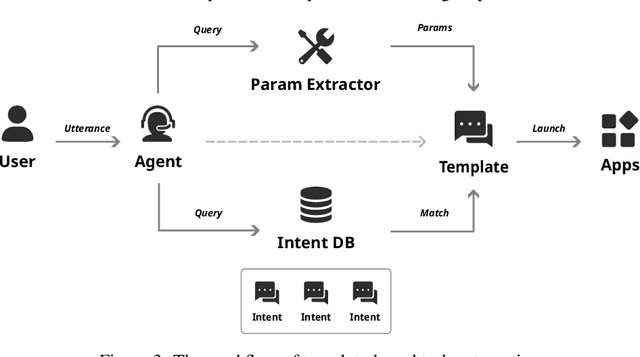
Since the advent of personal computing devices, intelligent personal assistants (IPAs) have been one of the key technologies that researchers and engineers have focused on, aiming to help users efficiently obtain information and execute tasks, and provide users with more intelligent, convenient, and rich interaction experiences. With the development of smartphones and IoT, computing and sensing devices have become ubiquitous, greatly expanding the boundaries of IPAs. However, due to the lack of capabilities such as user intent understanding, task planning, tool using, and personal data management etc., existing IPAs still have limited practicality and scalability. Recently, the emergence of foundation models, represented by large language models (LLMs), brings new opportunities for the development of IPAs. With the powerful semantic understanding and reasoning capabilities, LLM can enable intelligent agents to solve complex problems autonomously. In this paper, we focus on Personal LLM Agents, which are LLM-based agents that are deeply integrated with personal data and personal devices and used for personal assistance. We envision that Personal LLM Agents will become a major software paradigm for end-users in the upcoming era. To realize this vision, we take the first step to discuss several important questions about Personal LLM Agents, including their architecture, capability, efficiency and security. We start by summarizing the key components and design choices in the architecture of Personal LLM Agents, followed by an in-depth analysis of the opinions collected from domain experts. Next, we discuss several key challenges to achieve intelligent, efficient and secure Personal LLM Agents, followed by a comprehensive survey of representative solutions to address these challenges.
Generative Model for Models: Rapid DNN Customization for Diverse Tasks and Resource Constraints
Aug 29, 2023Unlike cloud-based deep learning models that are often large and uniform, edge-deployed models usually demand customization for domain-specific tasks and resource-limited environments. Such customization processes can be costly and time-consuming due to the diversity of edge scenarios and the training load for each scenario. Although various approaches have been proposed for rapid resource-oriented customization and task-oriented customization respectively, achieving both of them at the same time is challenging. Drawing inspiration from the generative AI and the modular composability of neural networks, we introduce NN-Factory, an one-for-all framework to generate customized lightweight models for diverse edge scenarios. The key idea is to use a generative model to directly produce the customized models, instead of training them. The main components of NN-Factory include a modular supernet with pretrained modules that can be conditionally activated to accomplish different tasks and a generative module assembler that manipulate the modules according to task and sparsity requirements. Given an edge scenario, NN-Factory can efficiently customize a compact model specialized in the edge task while satisfying the edge resource constraints by searching for the optimal strategy to assemble the modules. Based on experiments on image classification and object detection tasks with different edge devices, NN-Factory is able to generate high-quality task- and resource-specific models within few seconds, faster than conventional model customization approaches by orders of magnitude.
Arrhythmia Classifier using Binarized Convolutional Neural Network for Resource-Constrained Devices
May 13, 2022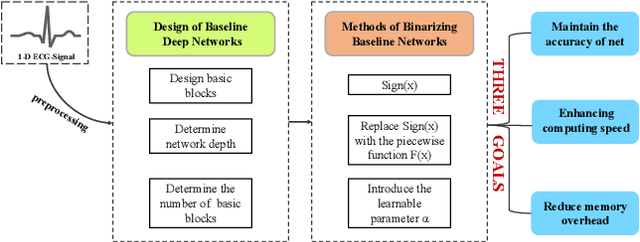
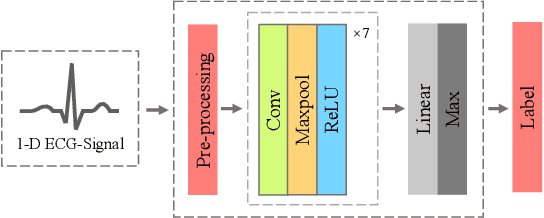
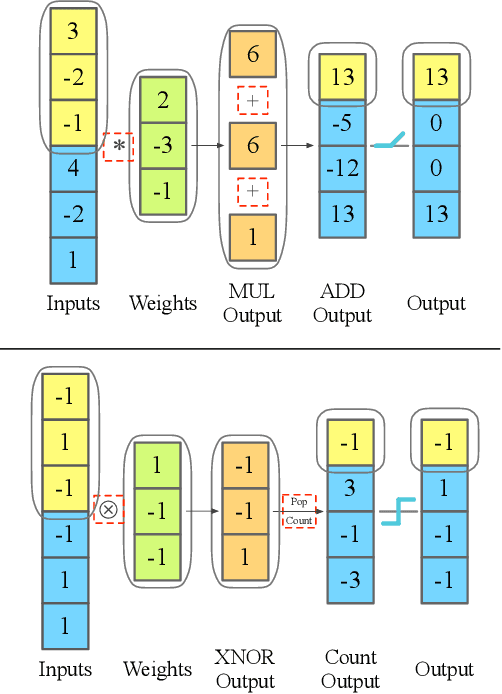
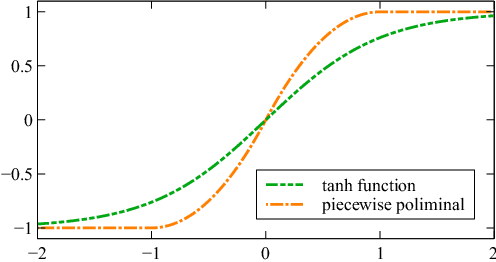
Monitoring electrocardiogram signals is of great significance for the diagnosis of arrhythmias. In recent years, deep learning and convolutional neural networks have been widely used in the classification of cardiac arrhythmias. However, the existing neural network applied to ECG signal detection usually requires a lot of computing resources, which is not friendlyF to resource-constrained equipment, and it is difficult to realize real-time monitoring. In this paper, a binarized convolutional neural network suitable for ECG monitoring is proposed, which is hardware-friendly and more suitable for use in resource-constrained wearable devices. Targeting the MIT-BIH arrhythmia database, the classifier based on this network reached an accuracy of 95.67% in the five-class test. Compared with the proposed baseline full-precision network with an accuracy of 96.45%, it is only 0.78% lower. Importantly, it achieves 12.65 times the computing speedup, 24.8 times the storage compression ratio, and only requires a quarter of the memory overhead.