 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAD: The First-Ever Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection
Oct 12, 2024



In the field of industrial inspection, Multimodal Large Language Models (MLLMs) have a high potential to renew the paradigms in practical applications due to their robust language capabilities and generalization abilities. However, despite their impressive problem-solving skills in many domains, MLLMs' ability in industrial anomaly detection has not been systematically studied. To bridge this gap, we present MMAD, the first-ever full-spectrum MLLMs benchmark in industrial Anomaly Detection. We defined seven key subtasks of MLLMs in industrial inspection and designed a novel pipeline to generate the MMAD dataset with 39,672 questions for 8,366 industrial images. With MMAD, we have conducted a comprehensive, quantitative evaluation of various state-of-the-art MLLMs. The commercial models performed the best, with the average accuracy of GPT-4o models reaching 74.9%. However, this result falls far short of industrial requirements. Our analysis reveals that current MLLMs still have significant room for improvement in answering questions related to industrial anomalies and defects. We further explore two training-free performance enhancement strategies to help models improve in industrial scenarios, highlighting their promising potential for future research.
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
May 08, 2024

Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
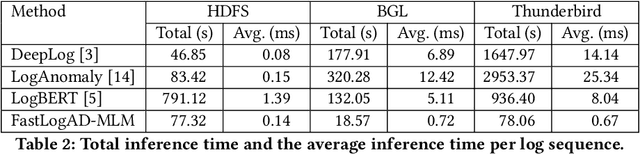
FastLogAD: Log Anomaly Detection with Mask-Guided Pseudo Anomaly Generation and Discrimination
Apr 12, 2024

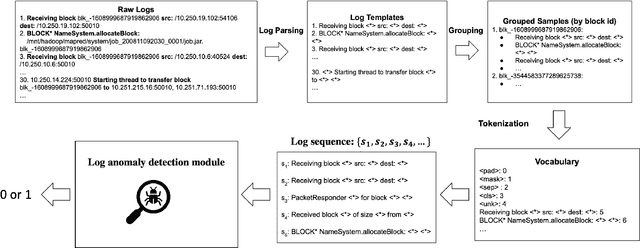
Nowadays large computers extensively output logs to record the runtime status and it has become crucial to identify any suspicious or malicious activities from the information provided by the realtime logs. Thus, fast log anomaly detection is a necessary task to be implemented for automating the infeasible manual detection. Most of the existing unsupervised methods are trained only on normal log data, but they usually require either additional abnormal data for hyperparameter selection or auxiliary datasets for discriminative model optimization. In this paper, aiming for a highly effective discriminative model that enables rapid anomaly detection,we propose FastLogAD, a generator-discriminator framework trained to exhibit the capability of generating pseudo-abnormal logs through the Mask-Guided Anomaly Generation (MGAG) model and efficiently identifying the anomalous logs via the Discriminative Abnormality Separation (DAS) model. Particularly, pseudo-abnormal logs are generated by replacing randomly masked tokens in a normal sequence with unlikely candidates. During the discriminative stage, FastLogAD learns a distinct separation between normal and pseudoabnormal samples based on their embedding norms, allowing the selection of a threshold without exposure to any test data and achieving competitive performance. Extensive experiments on several common benchmarks show that our proposed FastLogAD outperforms existing anomaly detection approaches. Furthermore, compared to previous methods, FastLogAD achieves at least x10 speed increase in anomaly detection over prior work. Our implementation is available at https://github.com/YifeiLin0226/FastLogAD.
Structural Teacher-Student Normality Learning for Multi-Class Anomaly Detection and Localization
Feb 27, 2024



Visual anomaly detection is a challenging open-set task aimed at identifying unknown anomalous patterns while modeling normal data. The knowledge distillation paradigm has shown remarkable performance in one-class anomaly detection by leveraging teacher-student network feature comparisons. However, extending this paradigm to multi-class anomaly detection introduces novel scalability challenges. In this study, we address the significant performance degradation observed in previous teacher-student models when applied to multi-class anomaly detection, which we identify as resulting from cross-class interference. To tackle this issue, we introduce a novel approach known as Structural Teacher-Student Normality Learning (SNL): (1) We propose spatial-channel distillation and intra-&inter-affinity distillation techniques to measure structural distance between the teacher and student networks. (2) We introduce a central residual aggregation module (CRAM) to encapsulate the normal representation space of the student network. We evaluate our proposed approach on two anomaly detection datasets, MVTecAD and VisA. Our method surpasses the state-of-the-art distillation-based algorithms by a significant margin of 3.9% and 1.5% on MVTecAD and 1.2% and 2.5% on VisA in the multi-class anomaly detection and localization tasks, respectively. Furthermore, our algorithm outperforms the current state-of-the-art unified models on both MVTecAD and VisA.
AnoVL: Adapting Vision-Language Models for Unified Zero-shot Anomaly Localization
Aug 30, 2023



Contrastive Language-Image Pre-training (CLIP) models have shown promising performance on zero-shot visual recognition tasks by learning visual representations under natural language supervision. Recent studies attempt the use of CLIP to tackle zero-shot anomaly detection by matching images with normal and abnormal state prompts. However, since CLIP focuses on building correspondence between paired text prompts and global image-level representations, the lack of patch-level vision to text alignment limits its capability on precise visual anomaly localization. In this work, we introduce a training-free adaptation (TFA) framework of CLIP for zero-shot anomaly localization. In the visual encoder, we innovate a training-free value-wise attention mechanism to extract intrinsic local tokens of CLIP for patch-level local description. From the perspective of text supervision, we particularly design a unified domain-aware contrastive state prompting template. On top of the proposed TFA, we further introduce a test-time adaptation (TTA) mechanism to refine anomaly localization results, where a layer of trainable parameters in the adapter is optimized using TFA's pseudo-labels and synthetic noise-corrupted tokens. With both TFA and TTA adaptation, we significantly exploit the potential of CLIP for zero-shot anomaly localization and demonstrate the effectiveness of our proposed methods on various datasets.
BMAD: Benchmarks for Medical Anomaly Detection
Jun 28, 2023Anomaly detection (AD) is a fundamental research problem in machine learning and computer vision, with practical applications in industrial inspection, video surveillance, and medical diagnosis. In medical imaging, AD is especially vital for detecting and diagnosing anomalies that may indicate rare diseases or conditions. However, there is a lack of a universal and fair benchmark for evaluating AD methods on medical images, which hinders the development of more generalized and robust AD methods in this specific domain. To bridge this gap, we introduce a comprehensive evaluation benchmark for assessing anomaly detection methods on medical images. This benchmark encompasses six reorganized datasets from five medical domains (i.e. brain MRI, liver CT, retinal OCT, chest X-ray, and digital histopathology) and three key evaluation metrics, and includes a total of fourteen state-of-the-art AD algorithms. This standardized and well-curated medical benchmark with the well-structured codebase enables comprehensive comparisons among recently proposed anomaly detection methods. It will facilitate the community to conduct a fair comparison and advance the field of AD on medical imaging. More information on BMAD is available in our GitHub repository: https://github.com/DorisBao/BMAD
Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
Mar 03, 2023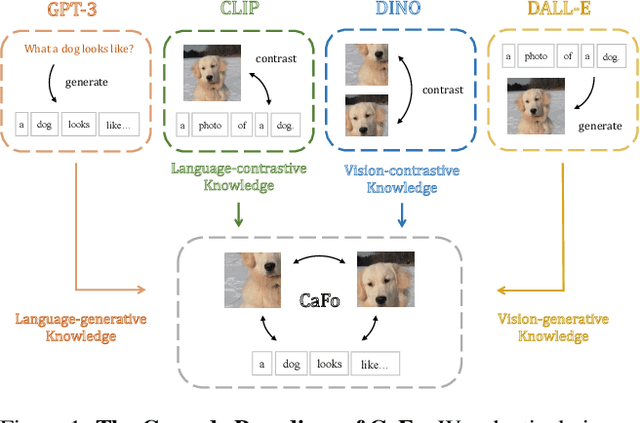
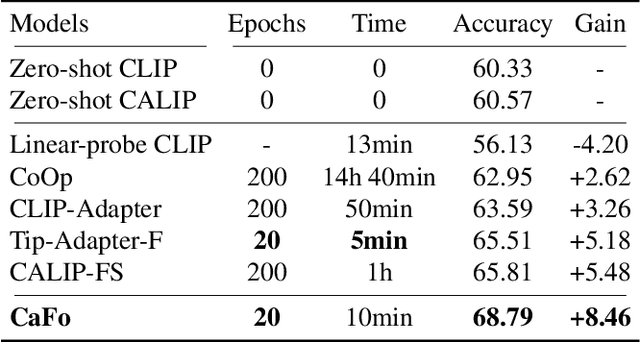
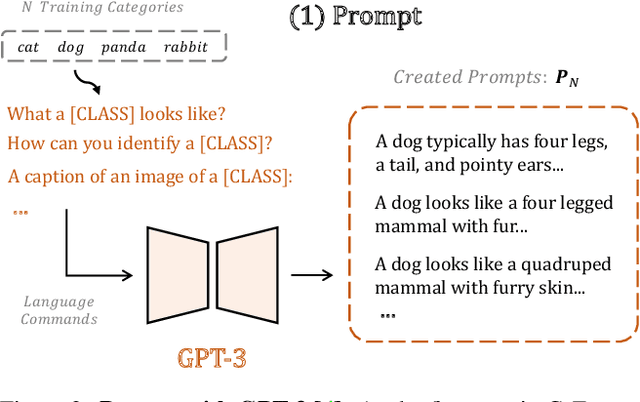
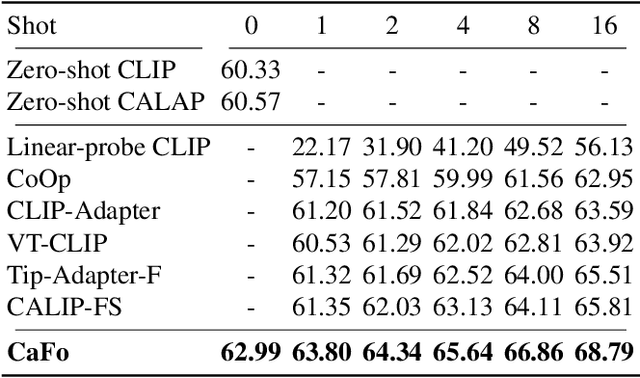
Visual recognition in low-data regimes requires deep neural networks to learn generalized representations from limited training samples. Recently, CLIP-based methods have shown promising few-shot performance benefited from the contrastive language-image pre-training. We then question, if the more diverse pre-training knowledge can be cascaded to further assist few-shot representation learning. In this paper, we propose CaFo, a Cascade of Foundation models that incorporates diverse prior knowledge of various pre-training paradigms for better few-shot learning. Our CaFo incorporates CLIP's language-contrastive knowledge, DINO's vision-contrastive knowledge, DALL-E's vision-generative knowledge, and GPT-3's language-generative knowledge. Specifically, CaFo works by 'Prompt, Generate, then Cache'. Firstly, we leverage GPT-3 to produce textual inputs for prompting CLIP with rich downstream linguistic semantics. Then, we generate synthetic images via DALL-E to expand the few-shot training data without any manpower. At last, we introduce a learnable cache model to adaptively blend the predictions from CLIP and DINO. By such collaboration, CaFo can fully unleash the potential of different pre-training methods and unify them to perform state-of-the-art for few-shot classification. Code is available at https://github.com/ZrrSkywalker/CaFo.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Collaboration of Pre-trained Models Makes Better Few-shot Learner
Sep 25, 2022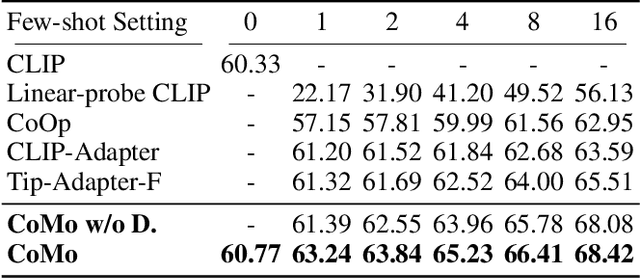
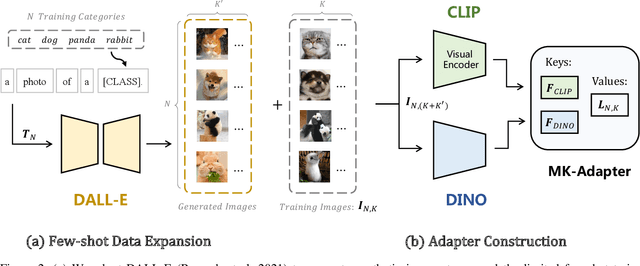
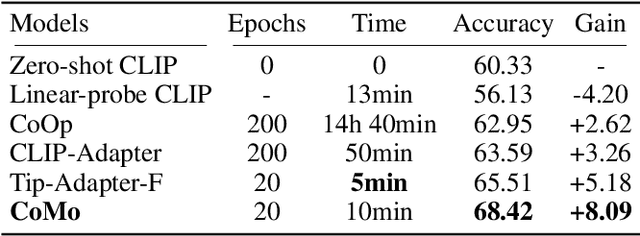
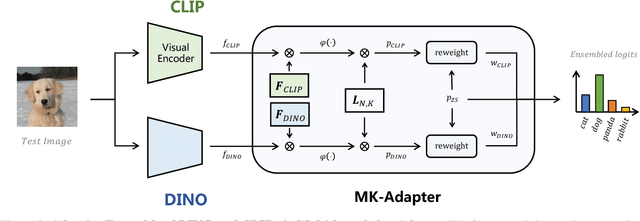
Few-shot classification requires deep neural networks to learn generalized representations only from limited training images, which is challenging but significant in low-data regimes. Recently, CLIP-based methods have shown promising few-shot performance benefited from the contrastive language-image pre-training. Based on this point, we question if the large-scale pre-training can alleviate the few-shot data deficiency and also assist the representation learning by the pre-learned knowledge. In this paper, we propose CoMo, a Collaboration of pre-trained Models that incorporates diverse prior knowledge from various pre-training paradigms for better few-shot learning. Our CoMo includes: CLIP's language-contrastive knowledge, DINO's vision-contrastive knowledge, and DALL-E's language-generative knowledge. Specifically, CoMo works in two aspects: few-shot data expansion and diverse knowledge ensemble. For one, we generate synthetic images via zero-shot DALL-E to enrich the few-shot training data without any manpower. For the other, we introduce a learnable Multi-Knowledge Adapter (MK-Adapter) to adaptively blend the predictions from CLIP and DINO. By such collaboration, CoMo can fully unleash the potential of different pre-training methods and unify them to perform state-of-the-art for few-shot classification. We conduct extensive experiments on 11 datasets to demonstrate the superiority and generalization ability of our approach.
Anomaly Detection via Reverse Distillation from One-Class Embedding
Jan 26, 2022
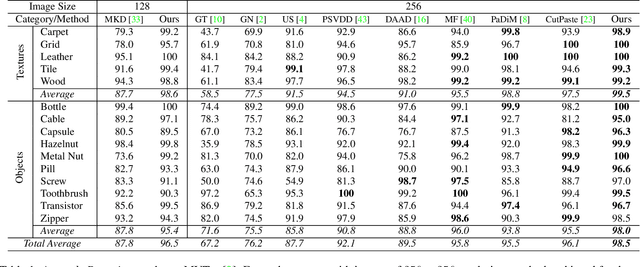
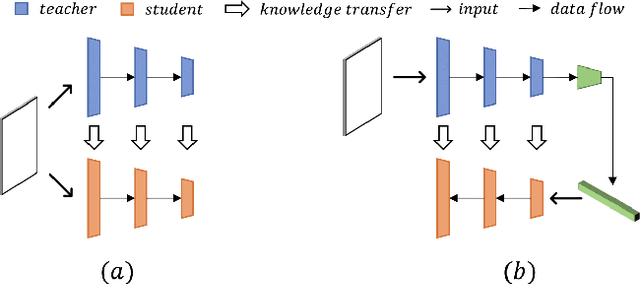

Knowledge distillation (KD) achieves promising results on the challenging problem of unsupervised anomaly detection (AD).The representation discrepancy of anomalies in the teacher-student (T-S) model provides essential evidence for AD. However, using similar or identical architectures to build the teacher and student models in previous studies hinders the diversity of anomalous representations. To tackle this problem, we propose a novel T-S model consisting of a teacher encoder and a student decoder and introduce a simple yet effective "reverse distillation" paradigm accordingly. Instead of receiving raw images directly, the student network takes teacher model's one-class embedding as input and targets to restore the teacher's multiscale representations. Inherently, knowledge distillation in this study starts from abstract, high-level presentations to low-level features. In addition, we introduce a trainable one-class bottleneck embedding (OCBE) module in our T-S model. The obtained compact embedding effectively preserves essential information on normal patterns, but abandons anomaly perturbations. Extensive experimentation on AD and one-class novelty detection benchmarks shows that our method surpasses SOTA performance, demonstrating our proposed approach's effectiveness and generalizability.