 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaboration of Pre-trained Models Makes Better Few-shot Learner
Paper and Code
Sep 25, 2022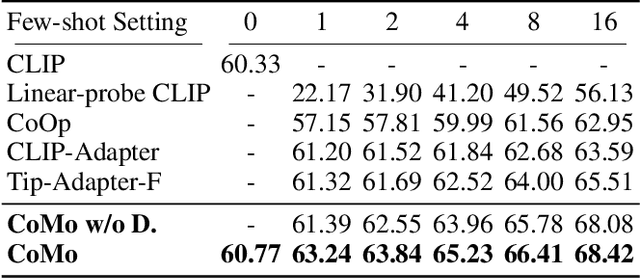
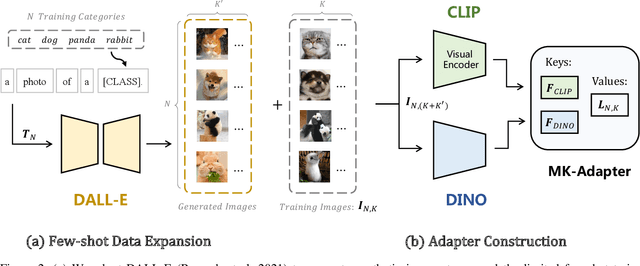
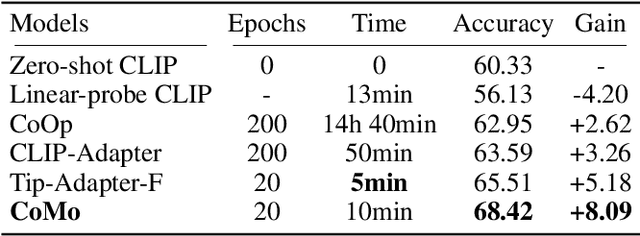
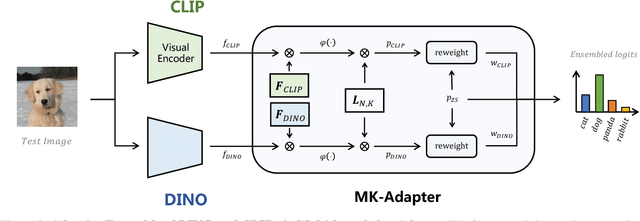
Few-shot classification requires deep neural networks to learn generalized representations only from limited training images, which is challenging but significant in low-data regimes. Recently, CLIP-based methods have shown promising few-shot performance benefited from the contrastive language-image pre-training. Based on this point, we question if the large-scale pre-training can alleviate the few-shot data deficiency and also assist the representation learning by the pre-learned knowledge. In this paper, we propose CoMo, a Collaboration of pre-trained Models that incorporates diverse prior knowledge from various pre-training paradigms for better few-shot learning. Our CoMo includes: CLIP's language-contrastive knowledge, DINO's vision-contrastive knowledge, and DALL-E's language-generative knowledge. Specifically, CoMo works in two aspects: few-shot data expansion and diverse knowledge ensemble. For one, we generate synthetic images via zero-shot DALL-E to enrich the few-shot training data without any manpower. For the other, we introduce a learnable Multi-Knowledge Adapter (MK-Adapter) to adaptively blend the predictions from CLIP and DINO. By such collaboration, CoMo can fully unleash the potential of different pre-training methods and unify them to perform state-of-the-art for few-shot classification. We conduct extensive experiments on 11 datasets to demonstrate the superiority and generalization ability of our approach.