 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAU-vMAE: Knowledge-Guide Action Units Detection via Video Masked Autoencoder
Jul 16, 2024



Current Facial Action Unit (FAU) detection methods generally encounter difficulties due to the scarcity of labeled video training data and the limited number of training face IDs, which renders the trained feature extractor insufficient coverage for modeling the large diversity of inter-person facial structures and movements. To explicitly address the above challenges, we propose a novel video-level pre-training scheme by fully exploring the multi-label property of FAUs in the video as well as the temporal label consistency. At the heart of our design is a pre-trained video feature extractor based on the video-masked autoencoder together with a fine-tuning network that jointly completes the multi-level video FAUs analysis tasks, \emph{i.e.} integrating both video-level and frame-level FAU detections, thus dramatically expanding the supervision set from sparse FAUs annotations to ALL video frames including masked ones. Moreover, we utilize inter-frame and intra-frame AU pair state matrices as prior knowledge to guide network training instead of traditional Graph Neural Networks, for better temporal supervision. Our approach demonstrates substantial enhancement in performance compared to the existing state-of-the-art methods used in BP4D and DISFA FAUs datasets.
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Apr 09, 2024
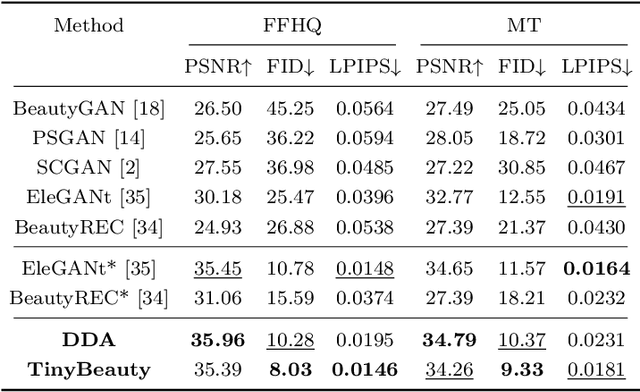

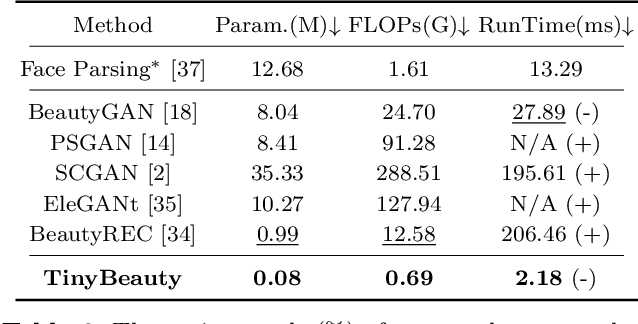
Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
Real-Time Neural BRDF with Spherically Distributed Primitives
Oct 12, 2023We propose a novel compact and efficient neural BRDF offering highly versatile material representation, yet with very-light memory and neural computation consumption towards achieving real-time rendering. The results in Figure 1, rendered at full HD resolution on a current desktop machine, show that our system achieves real-time rendering with a wide variety of appearances, which is approached by the following two designs. On the one hand, noting that bidirectional reflectance is distributed in a very sparse high-dimensional subspace, we propose to project the BRDF into two low-dimensional components, i.e., two hemisphere feature-grids for incoming and outgoing directions, respectively. On the other hand, learnable neural reflectance primitives are distributed on our highly-tailored spherical surface grid, which offer informative features for each component and alleviate the conventional heavy feature learning network to a much smaller one, leading to very fast evaluation. These primitives are centrally stored in a codebook and can be shared across multiple grids and even across materials, based on the low-cost indices stored in material-specific spherical surface grids. Our neural BRDF, which is agnostic to the material, provides a unified framework that can represent a variety of materials in consistent manner. Comprehensive experimental results on measured BRDF compression, Monte Carlo simulated BRDF acceleration, and extension to spatially varying effect demonstrate the superior quality and generalizability achieved by the proposed scheme.