 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Tiny and High-quality Facial Makeup with Data Amplify Learning
Apr 09, 2024
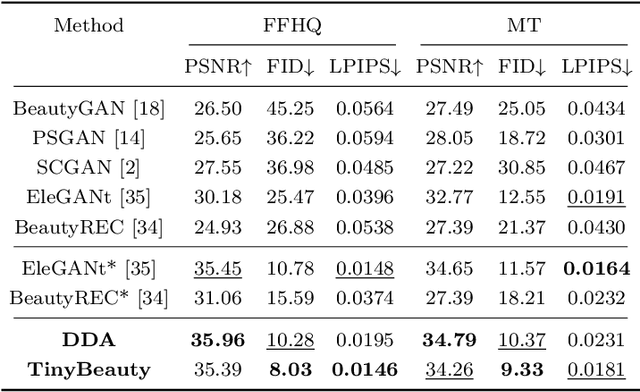

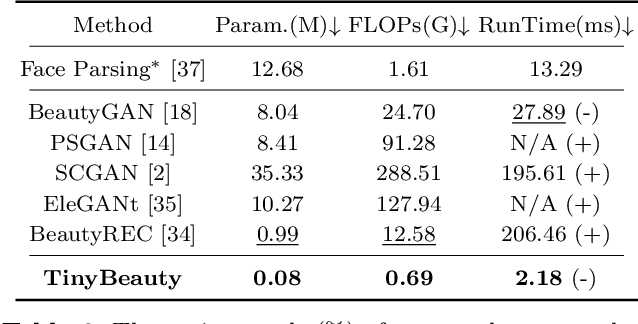
Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
Coded Illumination for 3D Lensless Imaging
Dec 22, 2022Mask-based lensless cameras offer a novel design for imaging systems by replacing the lens in a conventional camera with a layer of coded mask. Each pixel of the lensless camera encodes the information of the entire 3D scene. Existing methods for 3D reconstruction from lensless measurements suffer from poor spatial and depth resolution. This is partially due to the system ill conditioning that arises because the point-spread functions (PSFs) from different depth planes are very similar. In this paper, we propose to capture multiple measurements of the scene under a sequence of coded illumination patterns to improve the 3D image reconstruction quality. In addition, we put the illumination source at a distance away from the camera. With such baseline distance between the lensless camera and illumination source, the camera observes a slice of the 3D volume, and the PSF of each depth plane becomes more resolvable from each other. We present simulation results along with experimental results with a camera prototype to demonstrate the effectiveness of our approach.
Coded Illumination for Improved Lensless Imaging
Nov 25, 2021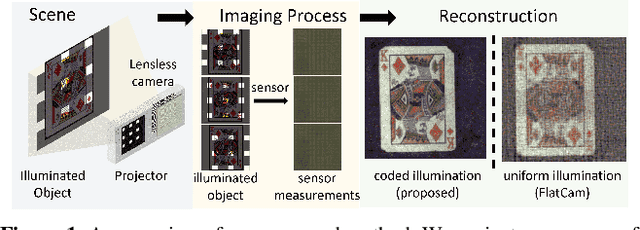
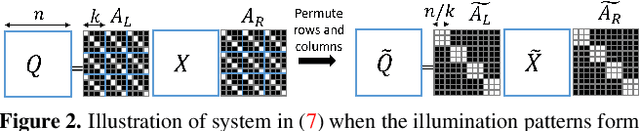
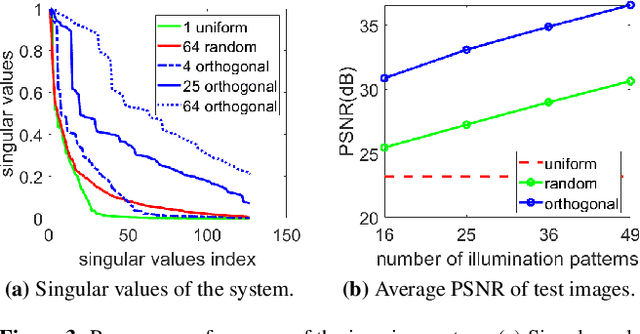
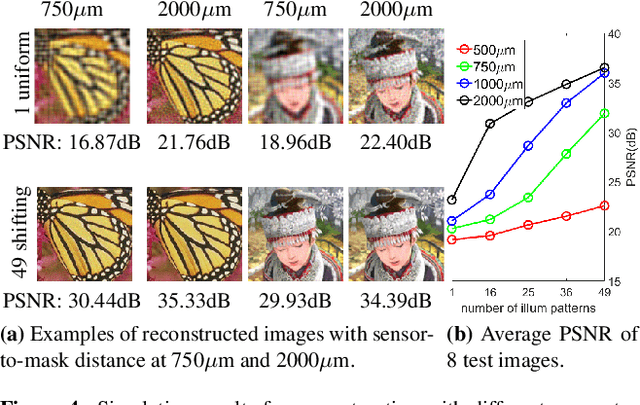
Mask-based lensless cameras can be flat, thin and light-weight, which makes them suitable for novel designs of computational imaging systems with large surface areas and arbitrary shapes. Despite recent progress in lensless cameras, the quality of images recovered from the lensless cameras is often poor due to the ill-conditioning of the underlying measurement system. In this paper, we propose to use coded illumination to improve the quality of images reconstructed with lensless cameras. In our imaging model, the scene/object is illuminated by multiple coded illumination patterns as the lensless camera records sensor measurements. We designed and tested a number of illumination patterns and observed that shifting dots (and related orthogonal) patterns provide the best overall performance. We propose a fast and low-complexity recovery algorithm that exploits the separability and block-diagonal structure in our system. We present simulation results and hardware experiment results to demonstrate that our proposed method can significantly improve the reconstruction quality.
A Simple Framework for 3D Lensless Imaging with Programmable Masks
Aug 18, 2021
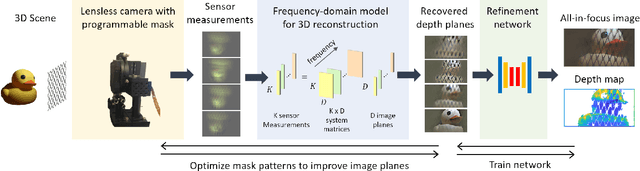
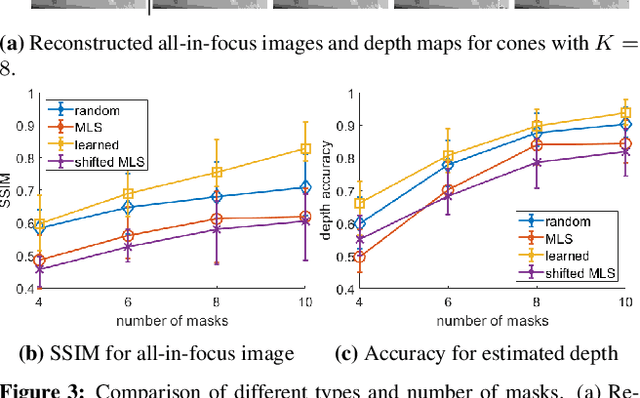

Lensless cameras provide a framework to build thin imaging systems by replacing the lens in a conventional camera with an amplitude or phase mask near the sensor. Existing methods for lensless imaging can recover the depth and intensity of the scene, but they require solving computationally-expensive inverse problems. Furthermore, existing methods struggle to recover dense scenes with large depth variations. In this paper, we propose a lensless imaging system that captures a small number of measurements using different patterns on a programmable mask. In this context, we make three contributions. First, we present a fast recovery algorithm to recover textures on a fixed number of depth planes in the scene. Second, we consider the mask design problem, for programmable lensless cameras, and provide a design template for optimizing the mask patterns with the goal of improving depth estimation. Third, we use a refinement network as a post-processing step to identify and remove artifacts in the reconstruction. These modifications are evaluated extensively with experimental results on a lensless camera prototype to showcase the performance benefits of the optimized masks and recovery algorithms over the state of the art.
* Supplementary material available at https://github.com/CSIPlab/Programmable3Dcam.git
Joint Image and Depth Estimation with Mask-Based Lensless Cameras
Oct 06, 2019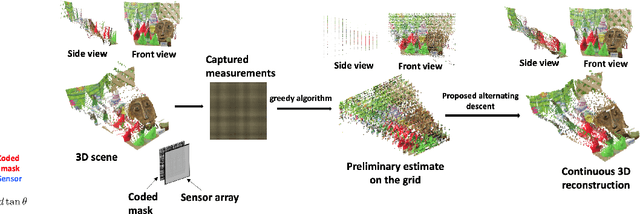


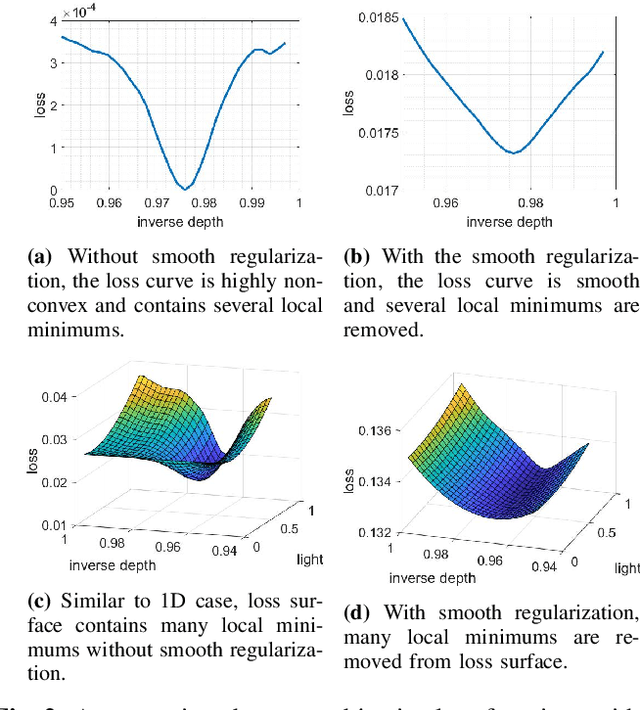
Mask-based lensless cameras replace the lens of a conventional camera with a customized mask. These cameras can potentially be very thin and even flexible. Recently, it has been demonstrated that such mask-based cameras can recover light intensity and depth information of a scene. Existing depth recovery algorithms either assume that the scene consists of a small number of depth planes or solve a sparse recovery problem over a large 3D volume. Both these approaches fail to recover scene with large depth variations. In this paper, we propose a new approach for depth estimation based on alternating gradient descent algorithm that jointly estimates a continuous depth map and light distribution of the unknown scene from its lensless measurements. The computational complexity of the algorithm scales linearly with the spatial dimension of the imaging system. We present simulation results on image and depth reconstruction for a variety of 3D test scenes. A comparison between the proposed algorithm and other method shows that our algorithm is faster and more robust for natural scenes with a large range of depths.