 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxyImg: Towards Highly-Controllable Image Representation via Hierarchical Disentangled Proxy Embedding
Feb 02, 2026Prevailing image representation methods, including explicit representations such as raster images and Gaussian primitives, as well as implicit representations such as latent images, either suffer from representation redundancy that leads to heavy manual editing effort, or lack a direct mapping from latent variables to semantic instances or parts, making fine-grained manipulation difficult. These limitations hinder efficient and controllable image and video editing. To address these issues, we propose a hierarchical proxy-based parametric image representation that disentangles semantic, geometric, and textural attributes into independent and manipulable parameter spaces. Based on a semantic-aware decomposition of the input image, our representation constructs hierarchical proxy geometries through adaptive Bezier fitting and iterative internal region subdivision and meshing. Multi-scale implicit texture parameters are embedded into the resulting geometry-aware distributed proxy nodes, enabling continuous high-fidelity reconstruction in the pixel domain and instance- or part-independent semantic editing. In addition, we introduce a locality-adaptive feature indexing mechanism to ensure spatial texture coherence, which further supports high-quality background completion without relying on generative models. Extensive experiments on image reconstruction and editing benchmarks, including ImageNet, OIR-Bench, and HumanEdit, demonstrate that our method achieves state-of-the-art rendering fidelity with significantly fewer parameters, while enabling intuitive, interactive, and physically plausible manipulation. Moreover, by integrating proxy nodes with Position-Based Dynamics, our framework supports real-time physics-driven animation using lightweight implicit rendering, achieving superior temporal consistency and visual realism compared with generative approaches.
3DProxyImg: Controllable 3D-Aware Animation Synthesis from Single Image via 2D-3D Aligned Proxy Embedding
Dec 19, 20253D animation is central to modern visual media, yet traditional production pipelines remain labor-intensive, expertise-demanding, and computationally expensive. Recent AIGC-based approaches partially automate asset creation and rigging, but they either inherit the heavy costs of full 3D pipelines or rely on video-synthesis paradigms that sacrifice 3D controllability and interactivity. We focus on single-image 3D animation generation and argue that progress is fundamentally constrained by a trade-off between rendering quality and 3D control. To address this limitation, we propose a lightweight 3D animation framework that decouples geometric control from appearance synthesis. The core idea is a 2D-3D aligned proxy representation that uses a coarse 3D estimate as a structural carrier, while delegating high-fidelity appearance and view synthesis to learned image-space generative priors. This proxy formulation enables 3D-aware motion control and interaction comparable to classical pipelines, without requiring accurate geometry or expensive optimization, and naturally extends to coherent background animation. Extensive experiments demonstrate that our method achieves efficient animation generation on low-power platforms and outperforms video-based 3D animation generation in identity preservation, geometric and textural consistency, and the level of precise, interactive control it offers to users.
QoE-oriented Communication Service Provision for Annotation Rendering in Mobile Augmented Reality
Jan 13, 2025


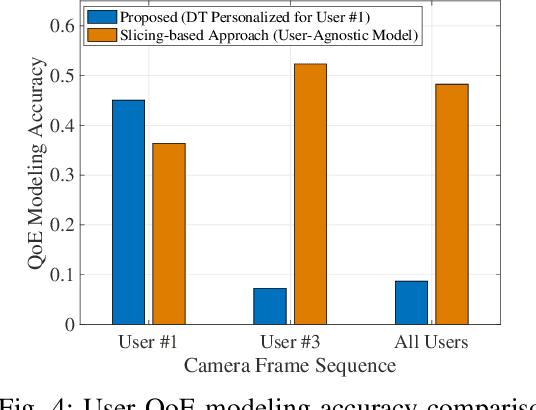
As mobile augmented reality (MAR) continues to evolve, future 6G networks will play a pivotal role in supporting immersive and personalized user experiences. In this paper, we address the communication service provision problem for annotation rendering in edge-assisted MAR, with the objective of optimizing spectrum resource utilization while ensuring the required quality of experience (QoE) for MAR users. To overcome the challenges of user-specific uplink data traffic patterns and the complex operational mechanisms of annotation rendering, we propose a digital twin (DT)-based approach. We first design a DT specifically tailored for MAR applications to learn key annotation rendering mechanisms, enabling the network controller to access MAR application-specific information. Then, we develop a DT based QoE modeling approach to capture the unique relationship between individual user QoE and spectrum resource demands. Finally, we propose a QoE-oriented resource allocation algorithm that decreases resource utilization compared to conventional net work slicing-based approaches. Simulation results demonstrate that our DT-based approach outperforms benchmark approaches in the accuracy and granularity of QoE modeling.
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Apr 09, 2024
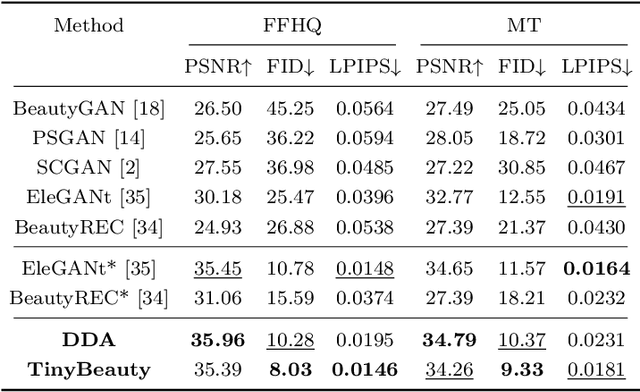

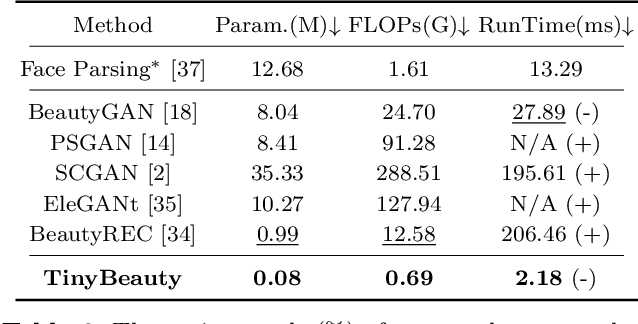
Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.