 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWireless Channel Identification via Conditional Diffusion Model
Jun 14, 2025The identification of channel scenarios in wireless systems plays a crucial role in channel modeling, radio fingerprint positioning, and transceiver design. Traditional methods to classify channel scenarios are based on typical statistical characteristics of channels, such as K-factor, path loss, delay spread, etc. However, statistic-based channel identification methods cannot accurately differentiate implicit features induced by dynamic scatterers, thus performing very poorly in identifying similar channel scenarios. In this paper, we propose a novel channel scenario identification method, formulating the identification task as a maximum a posteriori (MAP) estimation. Furthermore, the MAP estimation is reformulated by a maximum likelihood estimation (MLE), which is then approximated and solved by the conditional generative diffusion model. Specifically, we leverage a transformer network to capture hidden channel features in multiple latent noise spaces within the reverse process of the conditional generative diffusion model. These detailed features, which directly affect likelihood functions in MLE, enable highly accurate scenario identification. Experimental results show that the proposed method outperforms traditional methods, including convolutional neural networks (CNNs), back-propagation neural networks (BPNNs), and random forest-based classifiers, improving the identification accuracy by more than 10%.
Regret-Optimal Q-Learning with Low Cost for Single-Agent and Federated Reinforcement Learning
Jun 05, 2025Motivated by real-world settings where data collection and policy deployment -- whether for a single agent or across multiple agents -- are costly, we study the problem of on-policy single-agent reinforcement learning (RL) and federated RL (FRL) with a focus on minimizing burn-in costs (the sample sizes needed to reach near-optimal regret) and policy switching or communication costs. In parallel finite-horizon episodic Markov Decision Processes (MDPs) with $S$ states and $A$ actions, existing methods either require superlinear burn-in costs in $S$ and $A$ or fail to achieve logarithmic switching or communication costs. We propose two novel model-free RL algorithms -- Q-EarlySettled-LowCost and FedQ-EarlySettled-LowCost -- that are the first in the literature to simultaneously achieve: (i) the best near-optimal regret among all known model-free RL or FRL algorithms, (ii) low burn-in cost that scales linearly with $S$ and $A$, and (iii) logarithmic policy switching cost for single-agent RL or communication cost for FRL. Additionally, we establish gap-dependent theoretical guarantees for both regret and switching/communication costs, improving or matching the best-known gap-dependent bounds.
MSWAL: 3D Multi-class Segmentation of Whole Abdominal Lesions Dataset
Mar 17, 2025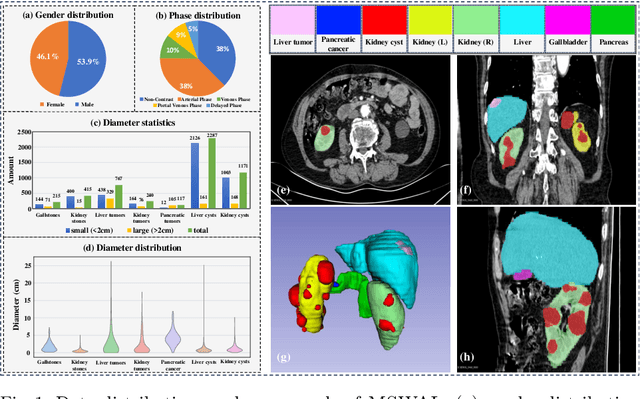
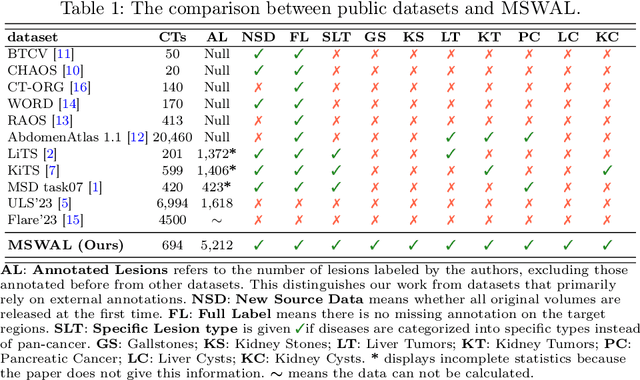
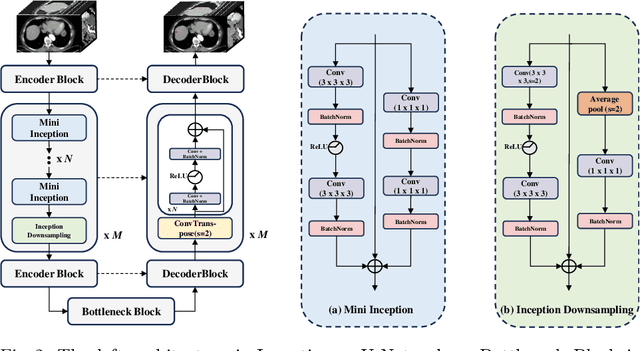
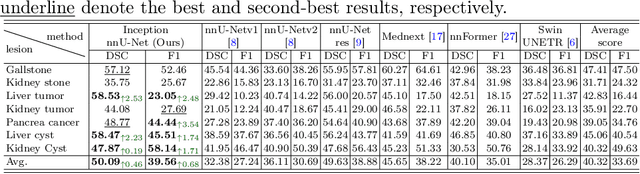
With the significantly increasing incidence and prevalence of abdominal diseases, there is a need to embrace greater use of new innovations and technology for the diagnosis and treatment of patients. Although deep-learning methods have notably been developed to assist radiologists in diagnosing abdominal diseases, existing models have the restricted ability to segment common lesions in the abdomen due to missing annotations for typical abdominal pathologies in their training datasets. To address the limitation, we introduce MSWAL, the first 3D Multi-class Segmentation of the Whole Abdominal Lesions dataset, which broadens the coverage of various common lesion types, such as gallstones, kidney stones, liver tumors, kidney tumors, pancreatic cancer, liver cysts, and kidney cysts. With CT scans collected from 694 patients (191,417 slices) of different genders across various scanning phases, MSWAL demonstrates strong robustness and generalizability. The transfer learning experiment from MSWAL to two public datasets, LiTS and KiTS, effectively demonstrates consistent improvements, with Dice Similarity Coefficient (DSC) increase of 3.00% for liver tumors and 0.89% for kidney tumors, demonstrating that the comprehensive annotations and diverse lesion types in MSWAL facilitate effective learning across different domains and data distributions. Furthermore, we propose Inception nnU-Net, a novel segmentation framework that effectively integrates an Inception module with the nnU-Net architecture to extract information from different receptive fields, achieving significant enhancement in both voxel-level DSC and region-level F1 compared to the cutting-edge public algorithms on MSWAL. Our dataset will be released after being accepted, and the code is publicly released at https://github.com/tiuxuxsh76075/MSWAL-.
Gap-Dependent Bounds for Federated $Q$-learning
Feb 05, 2025We present the first gap-dependent analysis of regret and communication cost for on-policy federated $Q$-Learning in tabular episodic finite-horizon Markov decision processes (MDPs). Existing FRL methods focus on worst-case scenarios, leading to $\sqrt{T}$-type regret bounds and communication cost bounds with a $\log T$ term scaling with the number of agents $M$, states $S$, and actions $A$, where $T$ is the average total number of steps per agent. In contrast, our novel framework leverages the benign structures of MDPs, such as a strictly positive suboptimality gap, to achieve a $\log T$-type regret bound and a refined communication cost bound that disentangles exploration and exploitation. Our gap-dependent regret bound reveals a distinct multi-agent speedup pattern, and our gap-dependent communication cost bound removes the dependence on $MSA$ from the $\log T$ term. Notably, our gap-dependent communication cost bound also yields a better global switching cost when $M=1$, removing $SA$ from the $\log T$ term.
Mutual Information-oriented ISAC Beamforming Design under Statistical CSI
Nov 20, 2024Existing integrated sensing and communication (ISAC) beamforming design were mostly designed under perfect instantaneous channel state information (CSI), limiting their use in practical dynamic environments. In this paper, we study the beamforming design for multiple-input multiple-output (MIMO) ISAC systems based on statistical CSI, with the weighted mutual information (MI) comprising sensing and communication perspectives adopted as the performance metric. In particular, the operator-valued free probability theory is utilized to derive the closed-form expression for the weighted MI under statistical CSI. Subsequently, an efficient projected gradient ascent (PGA) algorithm is proposed to optimize the transmit beamforming matrix with the aim of maximizing the weighted MI.Numerical results validate that the derived closed-form expression matches well with the Monte Carlo simulation results and the proposed optimization algorithm is able to improve the weighted MI significantly. We also illustrate the trade-off between sensing and communication MI.
Analysis and Optimization of Multiple-STAR-RIS Assisted MIMO-NOMA with GSVD Precoding: An Operator-Valued Free Probability Approach
Nov 14, 2024



Among the key enabling 6G techniques, multiple-input multiple-output (MIMO) and non-orthogonal multiple-access (NOMA) play an important role in enhancing the spectral efficiency of the wireless communication systems. To further extend the coverage and the capacity, the simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) has recently emerged out as a cost-effective technology. To exploit the benefit of STAR-RIS in the MIMO-NOMA systems, in this paper, we investigate the analysis and optimization of the downlink dual-user MIMO-NOMA systems assisted by multiple STAR-RISs under the generalized singular value decomposition (GSVD) precoding scheme, in which the channel is assumed to be Rician faded with the Weichselberger's correlation structure. To analyze the asymptotic information rate of the users, we apply the operator-valued free probability theory to obtain the Cauchy transform of the generalized singular values (GSVs) of the MIMO-NOMA channel matrices, which can be used to obtain the information rate by Riemann integral. Then, considering the special case when the channels between the BS and the STAR-RISs are deterministic, we obtain the closed-form expression for the asymptotic information rates of the users. Furthermore, a projected gradient ascent method (PGAM) is proposed with the derived closed-form expression to design the STAR-RISs thereby maximizing the sum rate based on the statistical channel state information. The numerical results show the accuracy of the asymptotic expression compared to the Monte Carlo simulations and the superiority of the proposed PGAM algorithm.
Gap-Dependent Bounds for Q-Learning using Reference-Advantage Decomposition
Oct 10, 2024We study the gap-dependent bounds of two important algorithms for on-policy Q-learning for finite-horizon episodic tabular Markov Decision Processes (MDPs): UCB-Advantage (Zhang et al. 2020) and Q-EarlySettled-Advantage (Li et al. 2021). UCB-Advantage and Q-EarlySettled-Advantage improve upon the results based on Hoeffding-type bonuses and achieve the almost optimal $\sqrt{T}$-type regret bound in the worst-case scenario, where $T$ is the total number of steps. However, the benign structures of the MDPs such as a strictly positive suboptimality gap can significantly improve the regret. While gap-dependent regret bounds have been obtained for Q-learning with Hoeffding-type bonuses, it remains an open question to establish gap-dependent regret bounds for Q-learning using variance estimators in their bonuses and reference-advantage decomposition for variance reduction. We develop a novel error decomposition framework to prove gap-dependent regret bounds of UCB-Advantage and Q-EarlySettled-Advantage that are logarithmic in $T$ and improve upon existing ones for Q-learning algorithms. Moreover, we establish the gap-dependent bound for the policy switching cost of UCB-Advantage and improve that under the worst-case MDPs. To our knowledge, this paper presents the first gap-dependent regret analysis for Q-learning using variance estimators and reference-advantage decomposition and also provides the first gap-dependent analysis on policy switching cost for Q-learning.
Smoothed Robust Phase Retrieval
Sep 03, 2024The phase retrieval problem in the presence of noise aims to recover the signal vector of interest from a set of quadratic measurements with infrequent but arbitrary corruptions, and it plays an important role in many scientific applications. However, the essential geometric structure of the nonconvex robust phase retrieval based on the $\ell_1$-loss is largely unknown to study spurious local solutions, even under the ideal noiseless setting, and its intrinsic nonsmooth nature also impacts the efficiency of optimization algorithms. This paper introduces the smoothed robust phase retrieval (SRPR) based on a family of convolution-type smoothed loss functions. Theoretically, we prove that the SRPR enjoys a benign geometric structure with high probability: (1) under the noiseless situation, the SRPR has no spurious local solutions, and the target signals are global solutions, and (2) under the infrequent but arbitrary corruptions, we characterize the stationary points of the SRPR and prove its benign landscape, which is the first landscape analysis of phase retrieval with corruption in the literature. Moreover, we prove the local linear convergence rate of gradient descent for solving the SRPR under the noiseless situation. Experiments on both simulated datasets and image recovery are provided to demonstrate the numerical performance of the SRPR.
Federated Q-Learning with Reference-Advantage Decomposition: Almost Optimal Regret and Logarithmic Communication Cost
May 29, 2024In this paper, we consider model-free federated reinforcement learning for tabular episodic Markov decision processes. Under the coordination of a central server, multiple agents collaboratively explore the environment and learn an optimal policy without sharing their raw data. Despite recent advances in federated Q-learning algorithms achieving near-linear regret speedup with low communication cost, existing algorithms only attain suboptimal regrets compared to the information bound. We propose a novel model-free federated Q-learning algorithm, termed FedQ-Advantage. Our algorithm leverages reference-advantage decomposition for variance reduction and operates under two distinct mechanisms: synchronization between the agents and the server, and policy update, both triggered by events. We prove that our algorithm not only requires a lower logarithmic communication cost but also achieves an almost optimal regret, reaching the information bound up to a logarithmic factor and near-linear regret speedup compared to its single-agent counterpart when the time horizon is sufficiently large.
YNetr: Dual-Encoder architecture on Plain Scan Liver Tumors
Mar 30, 2024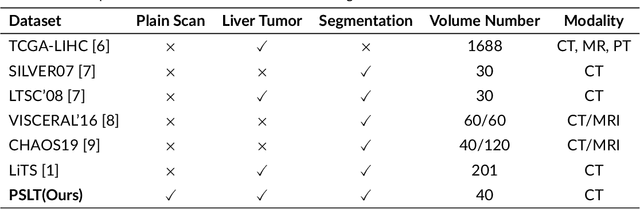

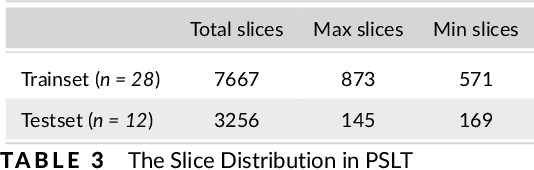
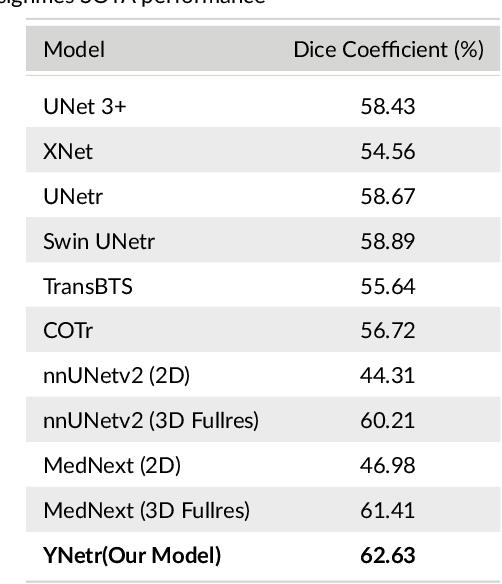
Background: Liver tumors are abnormal growths in the liver that can be either benign or malignant, with liver cancer being a significant health concern worldwide. However, there is no dataset for plain scan segmentation of liver tumors, nor any related algorithms. To fill this gap, we propose Plain Scan Liver Tumors(PSLT) and YNetr. Methods: A collection of 40 liver tumor plain scan segmentation datasets was assembled and annotated. Concurrently, we utilized Dice coefficient as the metric for assessing the segmentation outcomes produced by YNetr, having advantage of capturing different frequency information. Results: The YNetr model achieved a Dice coefficient of 62.63% on the PSLT dataset, surpassing the other publicly available model by an accuracy margin of 1.22%. Comparative evaluations were conducted against a range of models including UNet 3+, XNet, UNetr, Swin UNetr, Trans-BTS, COTr, nnUNetv2 (2D), nnUNetv2 (3D fullres), MedNext (2D) and MedNext(3D fullres). Conclusions: We not only proposed a dataset named PSLT(Plain Scan Liver Tumors), but also explored a structure called YNetr that utilizes wavelet transform to extract different frequency information, which having the SOTA in PSLT by experiments.