 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Aug 20, 2025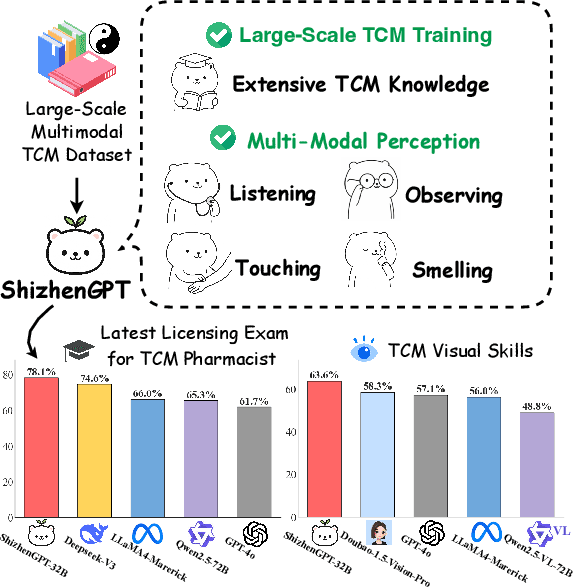
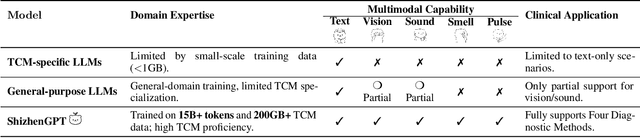
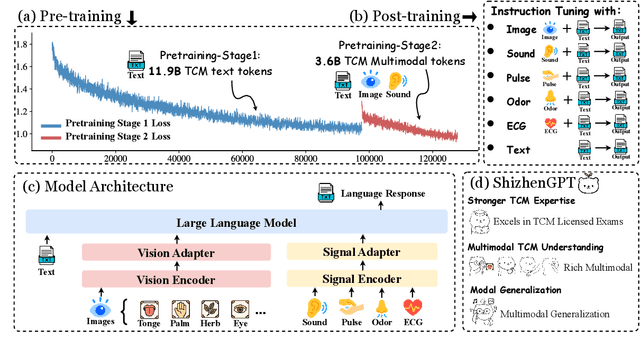
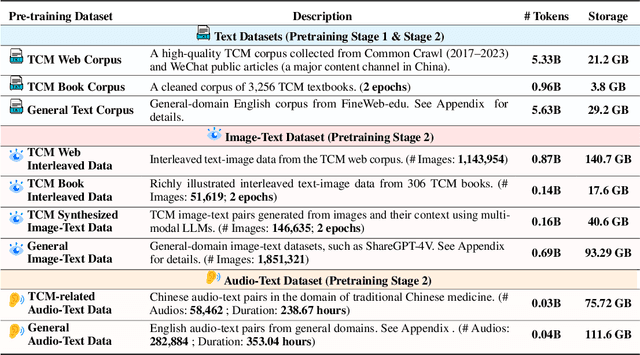
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
SyncAnimation: A Real-Time End-to-End Framework for Audio-Driven Human Pose and Talking Head Animation
Jan 24, 2025Generating talking avatar driven by audio remains a significant challenge. Existing methods typically require high computational costs and often lack sufficient facial detail and realism, making them unsuitable for applications that demand high real-time performance and visual quality. Additionally, while some methods can synchronize lip movement, they still face issues with consistency between facial expressions and upper body movement, particularly during silent periods. In this paper, we introduce SyncAnimation, the first NeRF-based method that achieves audio-driven, stable, and real-time generation of speaking avatar by combining generalized audio-to-pose matching and audio-to-expression synchronization. By integrating AudioPose Syncer and AudioEmotion Syncer, SyncAnimation achieves high-precision poses and expression generation, progressively producing audio-synchronized upper body, head, and lip shapes. Furthermore, the High-Synchronization Human Renderer ensures seamless integration of the head and upper body, and achieves audio-sync lip. The project page can be found at https://syncanimation.github.io
Environmental large language model Evaluation (ELLE) dataset: A Benchmark for Evaluating Generative AI applications in Eco-environment Domain
Jan 10, 2025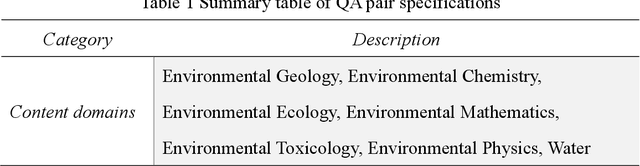
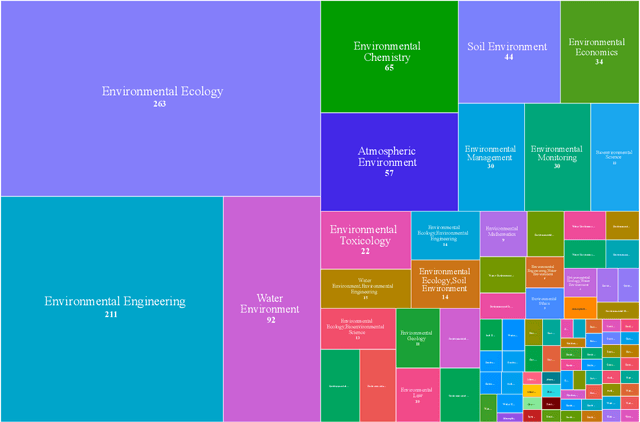
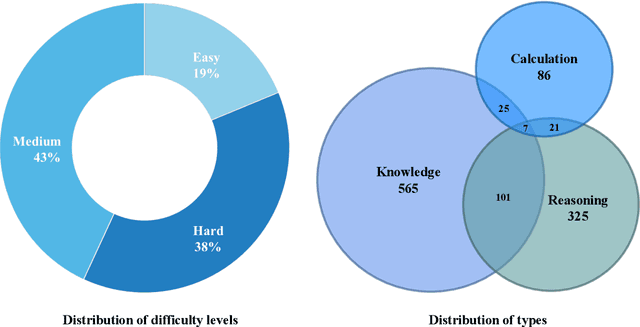
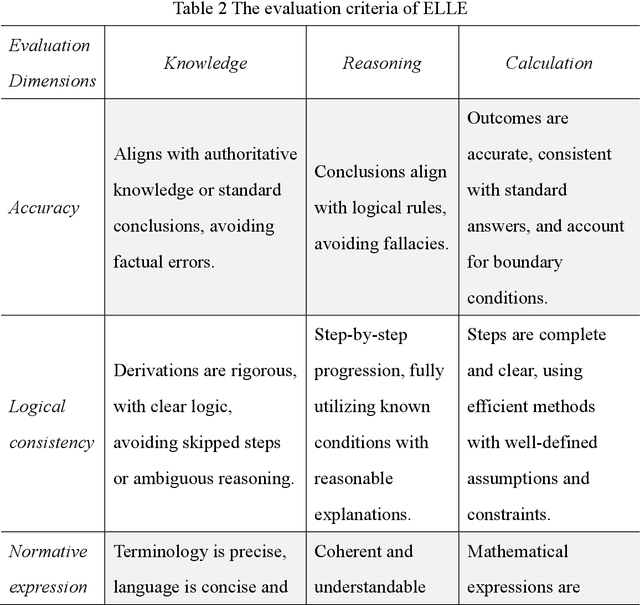
Generative AI holds significant potential for ecological and environmental applications such as monitoring, data analysis, education, and policy support. However, its effectiveness is limited by the lack of a unified evaluation framework. To address this, we present the Environmental Large Language model Evaluation (ELLE) question answer (QA) dataset, the first benchmark designed to assess large language models and their applications in ecological and environmental sciences. The ELLE dataset includes 1,130 question answer pairs across 16 environmental topics, categorized by domain, difficulty, and type. This comprehensive dataset standardizes performance assessments in these fields, enabling consistent and objective comparisons of generative AI performance. By providing a dedicated evaluation tool, ELLE dataset promotes the development and application of generative AI technologies for sustainable environmental outcomes. The dataset and code are available at https://elle.ceeai.net/ and https://github.com/CEEAI/elle.
Learning Quadrupedal Robot Locomotion for Narrow Pipe Inspection
Dec 18, 2024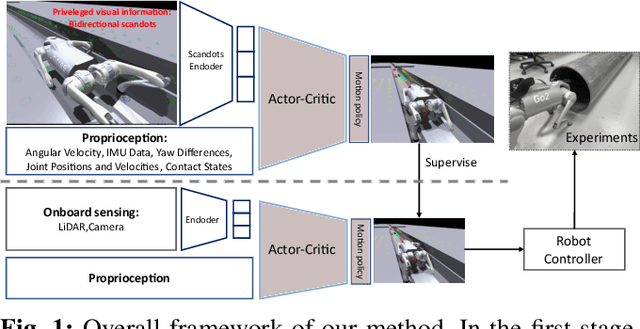
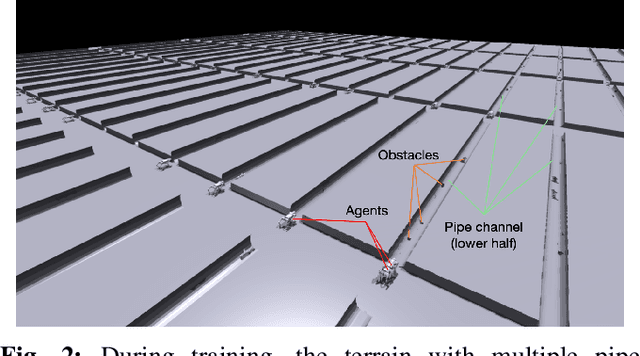
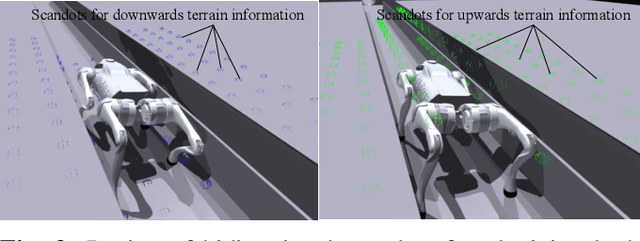
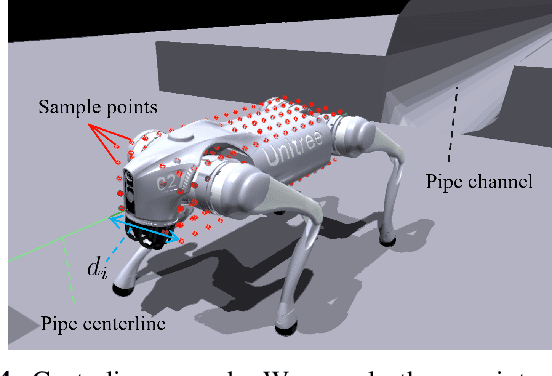
Various pipes are extensively used in both industrial settings and daily life, but the pipe inspection especially those with narrow sizes are still very challenging with tremendous time and manufacturing consumed. Quadrupedal robots, inspired from patrol dogs, can be a substitution of traditional solutions but always suffer from navigation and locomotion difficulties. In this paper, we introduce a Reinforcement Learning (RL) based method to train a policy enabling the quadrupedal robots to cross narrow pipes adaptively. A new privileged visual information and a new reward function are defined to tackle the problems. Experiments on both simulation and real world scenarios were completed, demonstrated that the proposed method can achieve the pipe-crossing task even with unexpected obstacles inside.
Deep Learning-Enabled ISAC-OTFS Pre-equalization Design for Aerial-Terrestrial Networks
Dec 06, 2024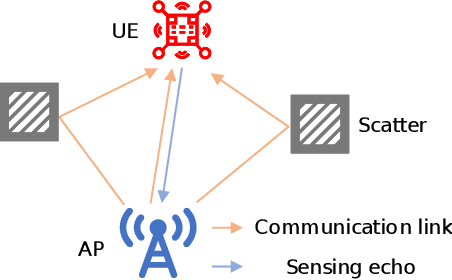
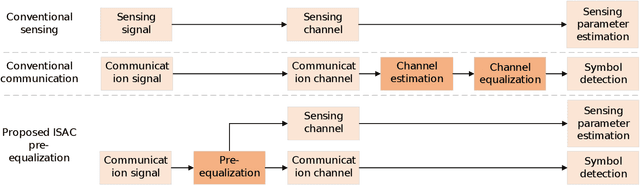
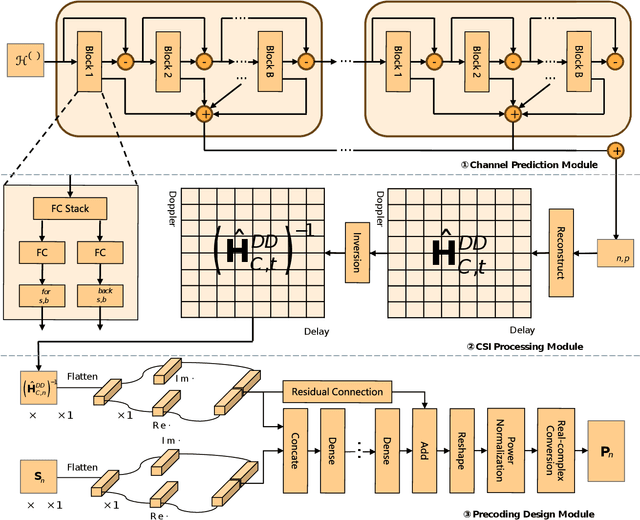
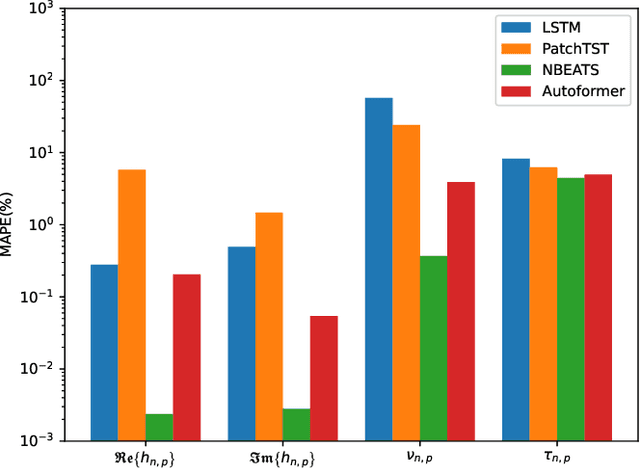
Orthogonal time frequency space (OTFS) modulation has been viewed as a promising technique for integrated sensing and communication (ISAC) systems and aerial-terrestrial networks, due to its delay-Doppler domain transmission property and strong Doppler-resistance capability. However, it also suffers from high processing complexity at the receiver. In this work, we propose a novel pre-equalization based ISAC-OTFS transmission framework, where the terrestrial base station (BS) executes pre-equalization based on its estimated channel state information (CSI). In particular, the mean square error of OTFS symbol demodulation and Cramer-Rao lower bound of sensing parameter estimation are derived, and their weighted sum is utilized as the metric for optimizing the pre-equalization matrix. To address the formulated problem while taking the time-varying CSI into consideration, a deep learning enabled channel prediction-based pre-equalization framework is proposed, where a parameter-level channel prediction module is utilized to decouple OTFS channel parameters, and a low-dimensional prediction network is leveraged to correct outdated CSI. A CSI processing module is then used to initialize the input of the pre-equalization module. Finally, a residual-structured deep neural network is cascaded to execute pre-equalization. Simulation results show that under the proposed framework, the demodulation complexity at the receiver as well as the pilot overhead for channel estimation, are significantly reduced, while the symbol detection performance approaches those of conventional minimum mean square error equalization and perfect CSI.
Analysis and Optimization of Multiple-STAR-RIS Assisted MIMO-NOMA with GSVD Precoding: An Operator-Valued Free Probability Approach
Nov 14, 2024



Among the key enabling 6G techniques, multiple-input multiple-output (MIMO) and non-orthogonal multiple-access (NOMA) play an important role in enhancing the spectral efficiency of the wireless communication systems. To further extend the coverage and the capacity, the simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) has recently emerged out as a cost-effective technology. To exploit the benefit of STAR-RIS in the MIMO-NOMA systems, in this paper, we investigate the analysis and optimization of the downlink dual-user MIMO-NOMA systems assisted by multiple STAR-RISs under the generalized singular value decomposition (GSVD) precoding scheme, in which the channel is assumed to be Rician faded with the Weichselberger's correlation structure. To analyze the asymptotic information rate of the users, we apply the operator-valued free probability theory to obtain the Cauchy transform of the generalized singular values (GSVs) of the MIMO-NOMA channel matrices, which can be used to obtain the information rate by Riemann integral. Then, considering the special case when the channels between the BS and the STAR-RISs are deterministic, we obtain the closed-form expression for the asymptotic information rates of the users. Furthermore, a projected gradient ascent method (PGAM) is proposed with the derived closed-form expression to design the STAR-RISs thereby maximizing the sum rate based on the statistical channel state information. The numerical results show the accuracy of the asymptotic expression compared to the Monte Carlo simulations and the superiority of the proposed PGAM algorithm.
CtrSVDD: A Benchmark Dataset and Baseline Analysis for Controlled Singing Voice Deepfake Detection
Jun 04, 2024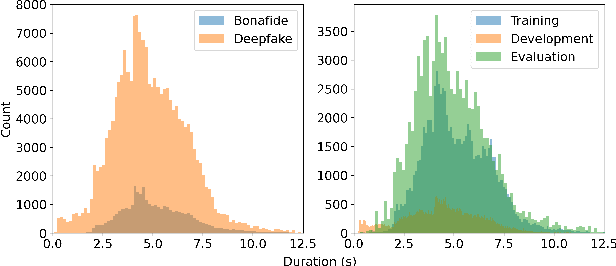
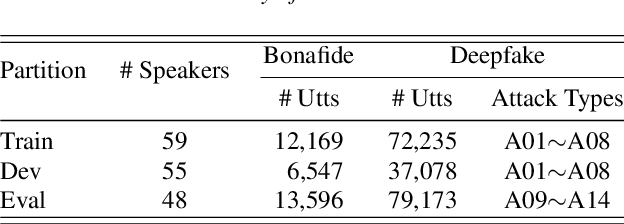
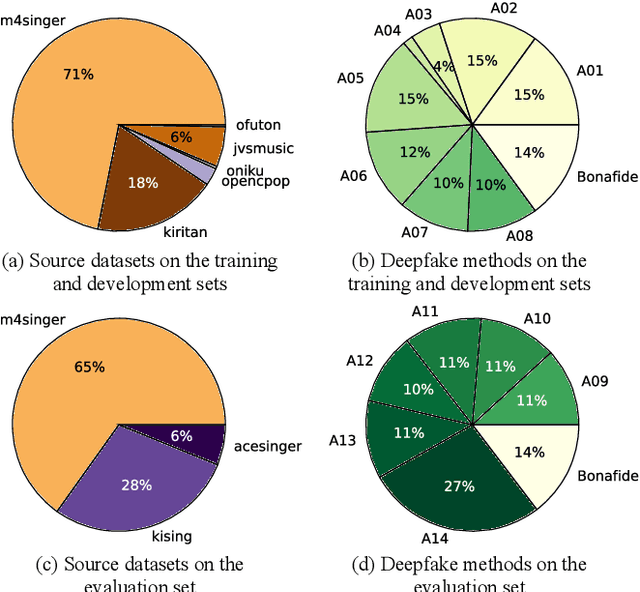

Recent singing voice synthesis and conversion advancements necessitate robust singing voice deepfake detection (SVDD) models. Current SVDD datasets face challenges due to limited controllability, diversity in deepfake methods, and licensing restrictions. Addressing these gaps, we introduce CtrSVDD, a large-scale, diverse collection of bonafide and deepfake singing vocals. These vocals are synthesized using state-of-the-art methods from publicly accessible singing voice datasets. CtrSVDD includes 47.64 hours of bonafide and 260.34 hours of deepfake singing vocals, spanning 14 deepfake methods and involving 164 singer identities. We also present a baseline system with flexible front-end features, evaluated against a structured train/dev/eval split. The experiments show the importance of feature selection and highlight a need for generalization towards deepfake methods that deviate further from training distribution. The CtrSVDD dataset and baselines are publicly accessible.
Experimental investigation of trans-scale displacement responses of wrinkle defects in fiber reinforced composite laminates
May 21, 2024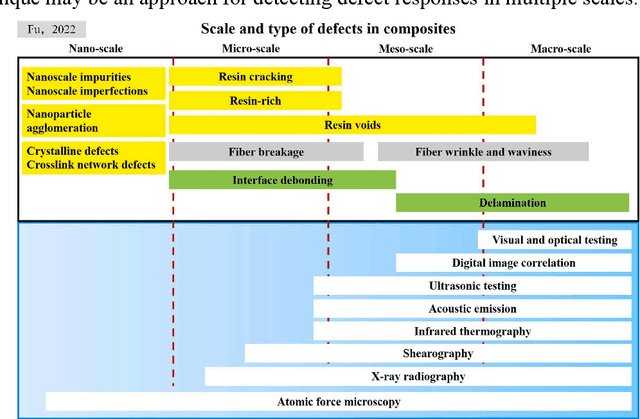
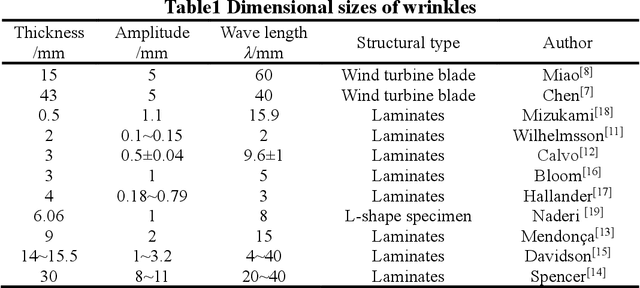

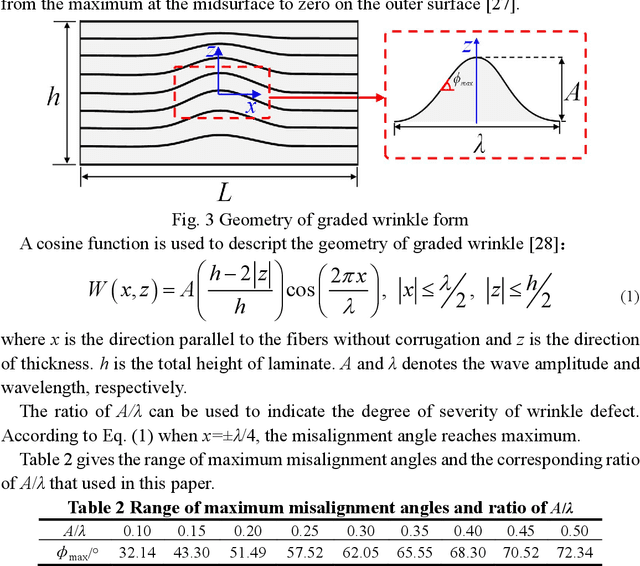
Wrinkle defects were found widely exist in the field of industrial products, i.e. wind turbine blades and filament-wound composite pressure vessels. The magnitude of wrinkle wavelength varies from several millimeters to over one hundred millimeters. Locating the wrinkle defects and measuring their responses are very important to the assessment of the structures that containing wrinkle defects. A meso-mechanical modeling is presented based on the homogenization method to obtain the effective stiffness of a graded wrinkle. The finite element simulation predicts the trans-scale response of out-of-plane displacement of wrinkled laminates, where the maximum displacement ranges from nanoscale to millimeter scale. Such trans-scale effect requires different measurement approaches to observe the displacement responses. Here we employed Shearography (Speckle Pattern Shearing Interferometry) and fringe projection profilometry (FPP) method respectively according to the different magnitude of displacement. In FPP method, a displacement extraction algorithm was presented to obtain the out-of-plane displacement. The measurement sensitivity and accuracy of Shearography and FPP are compared, which provides a quantitative reference for industrial non-destructive test.
Advanced Unstructured Data Processing for ESG Reports: A Methodology for Structured Transformation and Enhanced Analysis
Jan 04, 2024In the evolving field of corporate sustainability, analyzing unstructured Environmental, Social, and Governance (ESG) reports is a complex challenge due to their varied formats and intricate content. This study introduces an innovative methodology utilizing the "Unstructured Core Library", specifically tailored to address these challenges by transforming ESG reports into structured, analyzable formats. Our approach significantly advances the existing research by offering high-precision text cleaning, adept identification and extraction of text from images, and standardization of tables within these reports. Emphasizing its capability to handle diverse data types, including text, images, and tables, the method adeptly manages the nuances of differing page layouts and report styles across industries. This research marks a substantial contribution to the fields of industrial ecology and corporate sustainability assessment, paving the way for the application of advanced NLP technologies and large language models in the analysis of corporate governance and sustainability. Our code is available at https://github.com/linancn/TianGong-AI-Unstructure.git.
Empowering Working Memory for Large Language Model Agents
Dec 22, 2023Large language models (LLMs) have achieved impressive linguistic capabilities. However, a key limitation persists in their lack of human-like memory faculties. LLMs exhibit constrained memory retention across sequential interactions, hindering complex reasoning. This paper explores the potential of applying cognitive psychology's working memory frameworks, to enhance LLM architecture. The limitations of traditional LLM memory designs are analyzed, including their isolation of distinct dialog episodes and lack of persistent memory links. To address this, an innovative model is proposed incorporating a centralized Working Memory Hub and Episodic Buffer access to retain memories across episodes. This architecture aims to provide greater continuity for nuanced contextual reasoning during intricate tasks and collaborative scenarios. While promising, further research is required into optimizing episodic memory encoding, storage, prioritization, retrieval, and security. Overall, this paper provides a strategic blueprint for developing LLM agents with more sophisticated, human-like memory capabilities, highlighting memory mechanisms as a vital frontier in artificial general intelligence.