 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Discrete Speech Representation Tokens for Accent Generation
Jan 27, 2026Discrete Speech Representation Tokens (DSRTs) have become a foundational component in speech generation. While prior work has extensively studied phonetic and speaker information in DSRTs, how accent information is encoded in DSRTs remains largely unexplored. In this paper, we present the first systematic investigation of accent information in DSRTs. We propose a unified evaluation framework that measures both accessibility of accent information via a novel Accent ABX task and recoverability via cross-accent Voice Conversion (VC) resynthesis. Using this framework, we analyse DSRTs derived from a variety of speech encoders. Our results reveal that accent information is substantially reduced when ASR supervision is used to fine-tune the encoder, but cannot be effectively disentangled from phonetic and speaker information through naive codebook size reduction. Based on these findings, we propose new content-only and content-accent DSRTs that significantly outperform existing designs in controllable accent generation. Our work highlights the importance of accent-aware evaluation and provides practical guidance for designing DSRTs for accent-controlled speech generation.
Pairwise Evaluation of Accent Similarity in Speech Synthesis
May 20, 2025



Despite growing interest in generating high-fidelity accents, evaluating accent similarity in speech synthesis has been underexplored. We aim to enhance both subjective and objective evaluation methods for accent similarity. Subjectively, we refine the XAB listening test by adding components that achieve higher statistical significance with fewer listeners and lower costs. Our method involves providing listeners with transcriptions, having them highlight perceived accent differences, and implementing meticulous screening for reliability. Objectively, we utilise pronunciation-related metrics, based on distances between vowel formants and phonetic posteriorgrams, to evaluate accent generation. Comparative experiments reveal that these metrics, alongside accent similarity, speaker similarity, and Mel Cepstral Distortion, can be used. Moreover, our findings underscore significant limitations of common metrics like Word Error Rate in assessing underrepresented accents.
AccentBox: Towards High-Fidelity Zero-Shot Accent Generation
Sep 13, 2024

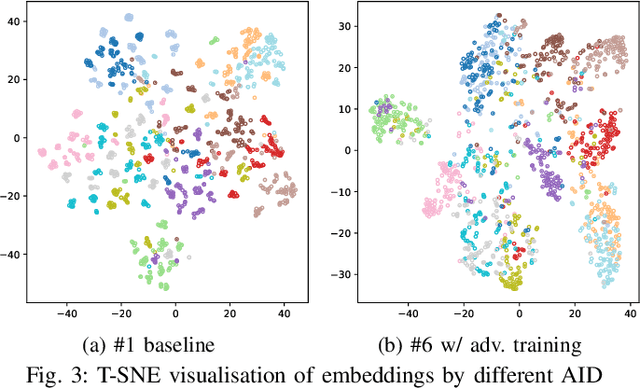

While recent Zero-Shot Text-to-Speech (ZS-TTS) models have achieved high naturalness and speaker similarity, they fall short in accent fidelity and control. To address this issue, we propose zero-shot accent generation that unifies Foreign Accent Conversion (FAC), accented TTS, and ZS-TTS, with a novel two-stage pipeline. In the first stage, we achieve state-of-the-art (SOTA) on Accent Identification (AID) with 0.56 f1 score on unseen speakers. In the second stage, we condition ZS-TTS system on the pretrained speaker-agnostic accent embeddings extracted by the AID model. The proposed system achieves higher accent fidelity on inherent/cross accent generation, and enables unseen accent generation.
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
Apr 14, 2024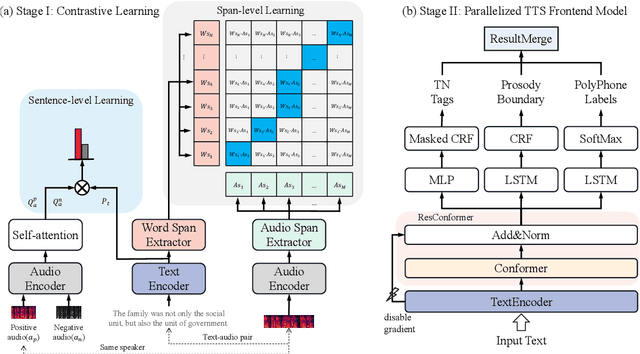
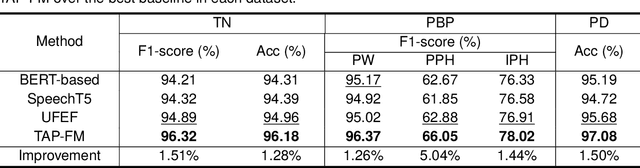

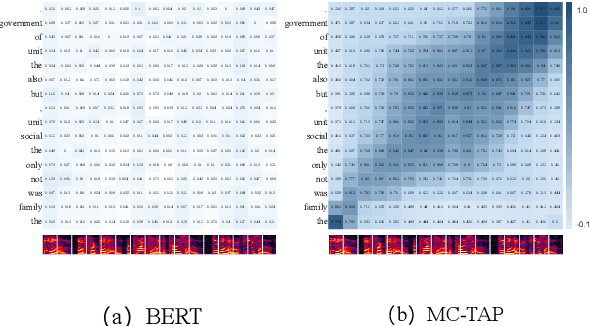
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
Multi-Modal Automatic Prosody Annotation with Contrastive Pretraining of SSWP
Sep 11, 2023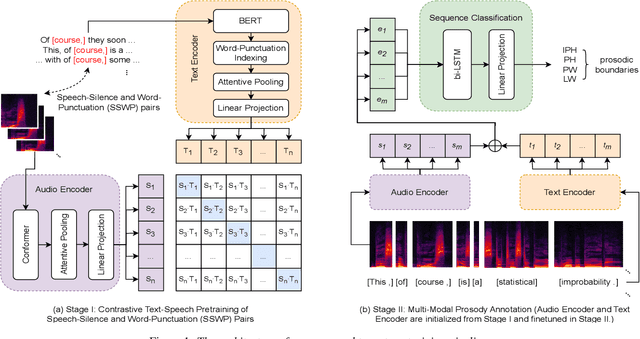

In the realm of expressive Text-to-Speech (TTS), explicit prosodic boundaries significantly advance the naturalness and controllability of synthesized speech. While human prosody annotation contributes a lot to the performance, it is a labor-intensive and time-consuming process, often resulting in inconsistent outcomes. Despite the availability of extensive supervised data, the current benchmark model still faces performance setbacks. To address this issue, a two-stage automatic annotation pipeline is novelly proposed in this paper. Specifically, in the first stage, we propose contrastive text-speech pretraining of Speech-Silence and Word-Punctuation (SSWP) pairs. The pretraining procedure hammers at enhancing the prosodic space extracted from joint text-speech space. In the second stage, we build a multi-modal prosody annotator, which consists of pretrained encoders, a straightforward yet effective text-speech feature fusion scheme, and a sequence classifier. Extensive experiments conclusively demonstrate that our proposed method excels at automatically generating prosody annotation and achieves state-of-the-art (SOTA) performance. Furthermore, our novel model has exhibited remarkable resilience when tested with varying amounts of data.