 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Anchor-Based Framework for Scalable Fair Clustering
Nov 13, 2025Fair clustering is crucial for mitigating bias in unsupervised learning, yet existing algorithms often suffer from quadratic or super-quadratic computational complexity, rendering them impractical for large-scale datasets. To bridge this gap, we introduce the Anchor-based Fair Clustering Framework (AFCF), a novel, general, and plug-and-play framework that empowers arbitrary fair clustering algorithms with linear-time scalability. Our approach first selects a small but representative set of anchors using a novel fair sampling strategy. Then, any off-the-shelf fair clustering algorithm can be applied to this small anchor set. The core of our framework lies in a novel anchor graph construction module, where we formulate an optimization problem to propagate labels while preserving fairness. This is achieved through a carefully designed group-label joint constraint, which we prove theoretically ensures that the fairness of the final clustering on the entire dataset matches that of the anchor clustering. We solve this optimization efficiently using an ADMM-based algorithm. Extensive experiments on multiple large-scale benchmarks demonstrate that AFCF drastically accelerates state-of-the-art methods, which reduces computational time by orders of magnitude while maintaining strong clustering performance and fairness guarantees.
Parameter-Free Clustering via Self-Supervised Consensus Maximization (Extended Version)
Nov 13, 2025Clustering is a fundamental task in unsupervised learning, but most existing methods heavily rely on hyperparameters such as the number of clusters or other sensitive settings, limiting their applicability in real-world scenarios. To address this long-standing challenge, we propose a novel and fully parameter-free clustering framework via Self-supervised Consensus Maximization, named SCMax. Our framework performs hierarchical agglomerative clustering and cluster evaluation in a single, integrated process. At each step of agglomeration, it creates a new, structure-aware data representation through a self-supervised learning task guided by the current clustering structure. We then introduce a nearest neighbor consensus score, which measures the agreement between the nearest neighbor-based merge decisions suggested by the original representation and the self-supervised one. The moment at which consensus maximization occurs can serve as a criterion for determining the optimal number of clusters. Extensive experiments on multiple datasets demonstrate that the proposed framework outperforms existing clustering approaches designed for scenarios with an unknown number of clusters.
Intra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery
Jul 16, 2025In this paper, we address the problem of novel class discovery (NCD), which aims to cluster novel classes by leveraging knowledge from disjoint known classes. While recent advances have made significant progress in this area, existing NCD methods face two major limitations. First, they primarily focus on single-view data (e.g., images), overlooking the increasingly common multi-view data, such as multi-omics datasets used in disease diagnosis. Second, their reliance on pseudo-labels to supervise novel class clustering often results in unstable performance, as pseudo-label quality is highly sensitive to factors such as data noise and feature dimensionality. To address these challenges, we propose a novel framework named Intra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery (IICMVNCD), which is the first attempt to explore NCD in multi-view setting so far. Specifically, at the intra-view level, leveraging the distributional similarity between known and novel classes, we employ matrix factorization to decompose features into view-specific shared base matrices and factor matrices. The base matrices capture distributional consistency among the two datasets, while the factor matrices model pairwise relationships between samples. At the inter-view level, we utilize view relationships among known classes to guide the clustering of novel classes. This includes generating predicted labels through the weighted fusion of factor matrices and dynamically adjusting view weights of known classes based on the supervision loss, which are then transferred to novel class learning. Experimental results validate the effectiveness of our proposed approach.
Automatically Identify and Rectify: Robust Deep Contrastive Multi-view Clustering in Noisy Scenarios
May 27, 2025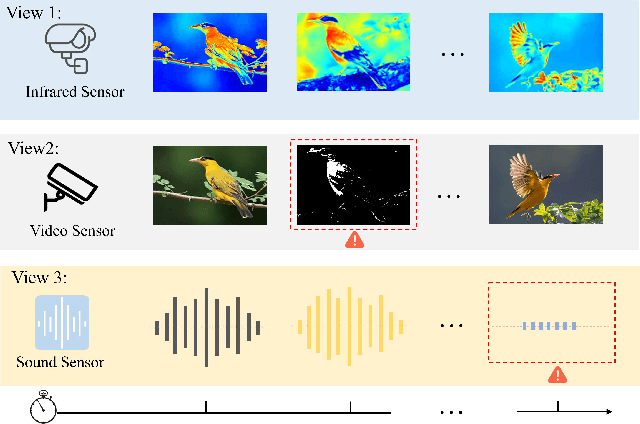
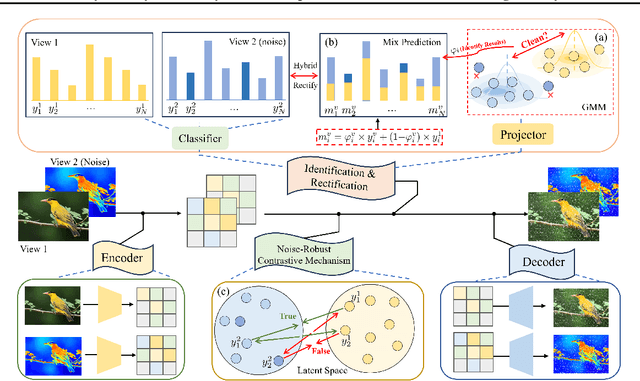

Leveraging the powerful representation learning capabilities, deep multi-view clustering methods have demonstrated reliable performance by effectively integrating multi-source information from diverse views in recent years. Most existing methods rely on the assumption of clean views. However, noise is pervasive in real-world scenarios, leading to a significant degradation in performance. To tackle this problem, we propose a novel multi-view clustering framework for the automatic identification and rectification of noisy data, termed AIRMVC. Specifically, we reformulate noisy identification as an anomaly identification problem using GMM. We then design a hybrid rectification strategy to mitigate the adverse effects of noisy data based on the identification results. Furthermore, we introduce a noise-robust contrastive mechanism to generate reliable representations. Additionally, we provide a theoretical proof demonstrating that these representations can discard noisy information, thereby improving the performance of downstream tasks. Extensive experiments on six benchmark datasets demonstrate that AIRMVC outperforms state-of-the-art algorithms in terms of robustness in noisy scenarios. The code of AIRMVC are available at https://github.com/xihongyang1999/AIRMVC on Github.
Pairwise Evaluation of Accent Similarity in Speech Synthesis
May 20, 2025Despite growing interest in generating high-fidelity accents, evaluating accent similarity in speech synthesis has been underexplored. We aim to enhance both subjective and objective evaluation methods for accent similarity. Subjectively, we refine the XAB listening test by adding components that achieve higher statistical significance with fewer listeners and lower costs. Our method involves providing listeners with transcriptions, having them highlight perceived accent differences, and implementing meticulous screening for reliability. Objectively, we utilise pronunciation-related metrics, based on distances between vowel formants and phonetic posteriorgrams, to evaluate accent generation. Comparative experiments reveal that these metrics, alongside accent similarity, speaker similarity, and Mel Cepstral Distortion, can be used. Moreover, our findings underscore significant limitations of common metrics like Word Error Rate in assessing underrepresented accents.
DealMVC: Dual Contrastive Calibration for Multi-view Clustering
Sep 02, 2023


Benefiting from the strong view-consistent information mining capacity, multi-view contrastive clustering has attracted plenty of attention in recent years. However, we observe the following drawback, which limits the clustering performance from further improvement. The existing multi-view models mainly focus on the consistency of the same samples in different views while ignoring the circumstance of similar but different samples in cross-view scenarios. To solve this problem, we propose a novel Dual contrastive calibration network for Multi-View Clustering (DealMVC). Specifically, we first design a fusion mechanism to obtain a global cross-view feature. Then, a global contrastive calibration loss is proposed by aligning the view feature similarity graph and the high-confidence pseudo-label graph. Moreover, to utilize the diversity of multi-view information, we propose a local contrastive calibration loss to constrain the consistency of pair-wise view features. The feature structure is regularized by reliable class information, thus guaranteeing similar samples have similar features in different views. During the training procedure, the interacted cross-view feature is jointly optimized at both local and global levels. In comparison with other state-of-the-art approaches, the comprehensive experimental results obtained from eight benchmark datasets provide substantial validation of the effectiveness and superiority of our algorithm. We release the code of DealMVC at https://github.com/xihongyang1999/DealMVC on GitHub.
Scalable Incomplete Multi-View Clustering with Structure Alignment
Aug 31, 2023



The success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.
Efficient Multi-View Graph Clustering with Local and Global Structure Preservation
Aug 31, 2023



Anchor-based multi-view graph clustering (AMVGC) has received abundant attention owing to its high efficiency and the capability to capture complementary structural information across multiple views. Intuitively, a high-quality anchor graph plays an essential role in the success of AMVGC. However, the existing AMVGC methods only consider single-structure information, i.e., local or global structure, which provides insufficient information for the learning task. To be specific, the over-scattered global structure leads to learned anchors failing to depict the cluster partition well. In contrast, the local structure with an improper similarity measure results in potentially inaccurate anchor assignment, ultimately leading to sub-optimal clustering performance. To tackle the issue, we propose a novel anchor-based multi-view graph clustering framework termed Efficient Multi-View Graph Clustering with Local and Global Structure Preservation (EMVGC-LG). Specifically, a unified framework with a theoretical guarantee is designed to capture local and global information. Besides, EMVGC-LG jointly optimizes anchor construction and graph learning to enhance the clustering quality. In addition, EMVGC-LG inherits the linear complexity of existing AMVGC methods respecting the sample number, which is time-economical and scales well with the data size. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method.
Align then Fusion: Generalized Large-scale Multi-view Clustering with Anchor Matching Correspondences
May 30, 2022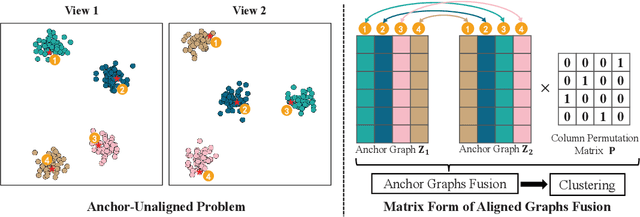
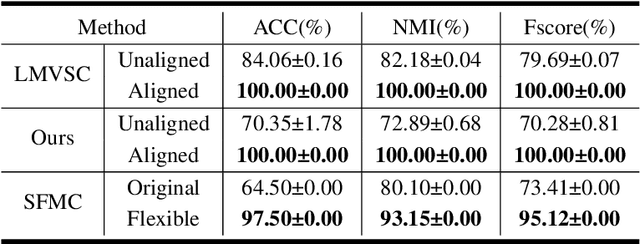
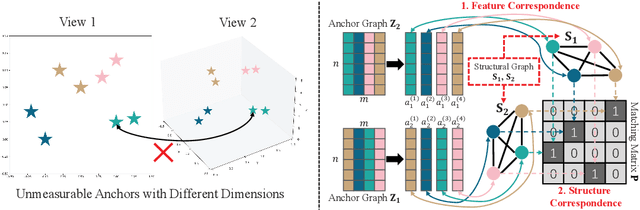
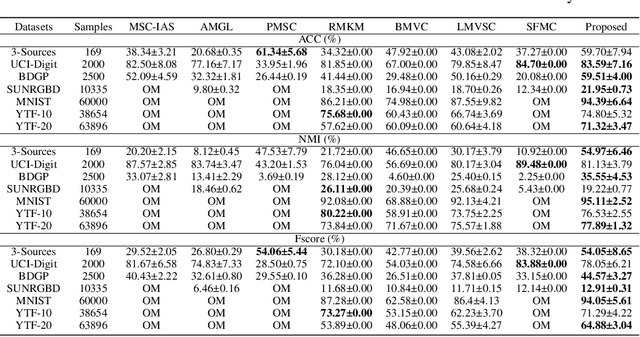
Multi-view anchor graph clustering selects representative anchors to avoid full pair-wise similarities and therefore reduce the complexity of graph methods. Although widely applied in large-scale applications, existing approaches do not pay sufficient attention to establishing correct correspondences between the anchor sets across views. To be specific, anchor graphs obtained from different views are not aligned column-wisely. Such an Anchor-Unaligned Problem (AUP) would cause inaccurate graph fusion and degrade the clustering performance. Under multi-view scenarios, generating correct correspondences could be extremely difficult since anchors are not consistent in feature dimensions. To solve this challenging issue, we propose the first study of a generalized and flexible anchor graph fusion framework termed Fast Multi-View Anchor-Correspondence Clustering (FMVACC). Specifically, we show how to find anchor correspondence with both feature and structure information, after which anchor graph fusion is performed column-wisely. Moreover, we theoretically show the connection between FMVACC and existing multi-view late fusion and partial view-aligned clustering, which further demonstrates our generality. Extensive experiments on seven benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Moreover, the proposed alignment module also shows significant performance improvement applying to existing multi-view anchor graph competitors indicating the importance of anchor alignment.
Meta-Path-Free Representation Learning on Heterogeneous Networks
Feb 16, 2021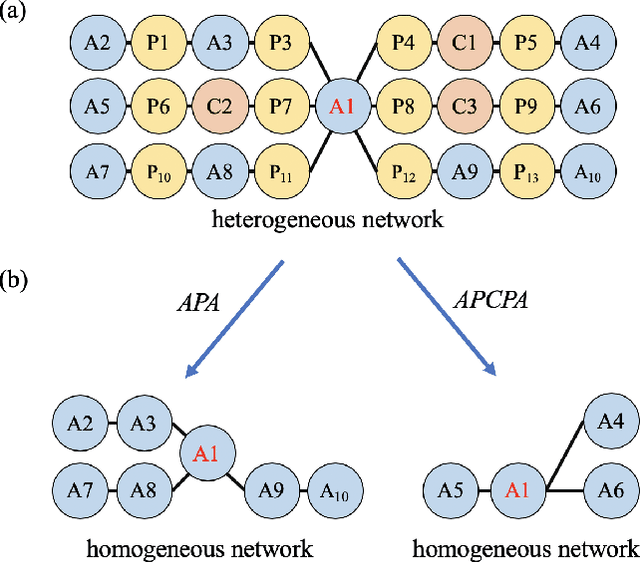
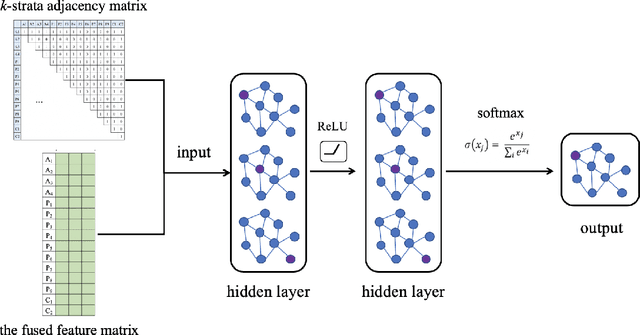
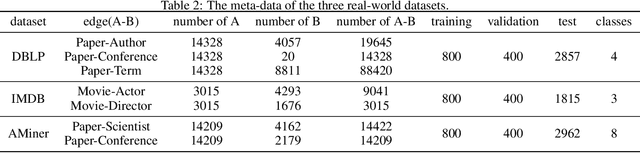
Real-world networks and knowledge graphs are usually heterogeneous networks. Representation learning on heterogeneous networks is not only a popular but a pragmatic research field. The main challenge comes from the heterogeneity -- the diverse types of nodes and edges. Besides, for a given node in a HIN, the significance of a neighborhood node depends not only on the structural distance but semantics. How to effectively capture both structural and semantic relations is another challenge. The current state-of-the-art methods are based on the algorithm of meta-path and therefore have a serious disadvantage -- the performance depends on the arbitrary choosing of meta-path(s). However, the selection of meta-path(s) is experience-based and time-consuming. In this work, we propose a novel meta-path-free representation learning on heterogeneous networks, namely Heterogeneous graph Convolutional Networks (HCN). The proposed method fuses the heterogeneity and develops a $k$-strata algorithm ($k$ is an integer) to capture the $k$-hop structural and semantic information in heterogeneous networks. To the best of our knowledge, this is the first attempt to break out of the confinement of meta-paths for representation learning on heterogeneous networks. We carry out extensive experiments on three real-world heterogeneous networks. The experimental results demonstrate that the proposed method significantly outperforms the current state-of-the-art methods in a variety of analytic tasks.