 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery
Jul 16, 2025In this paper, we address the problem of novel class discovery (NCD), which aims to cluster novel classes by leveraging knowledge from disjoint known classes. While recent advances have made significant progress in this area, existing NCD methods face two major limitations. First, they primarily focus on single-view data (e.g., images), overlooking the increasingly common multi-view data, such as multi-omics datasets used in disease diagnosis. Second, their reliance on pseudo-labels to supervise novel class clustering often results in unstable performance, as pseudo-label quality is highly sensitive to factors such as data noise and feature dimensionality. To address these challenges, we propose a novel framework named Intra-view and Inter-view Correlation Guided Multi-view Novel Class Discovery (IICMVNCD), which is the first attempt to explore NCD in multi-view setting so far. Specifically, at the intra-view level, leveraging the distributional similarity between known and novel classes, we employ matrix factorization to decompose features into view-specific shared base matrices and factor matrices. The base matrices capture distributional consistency among the two datasets, while the factor matrices model pairwise relationships between samples. At the inter-view level, we utilize view relationships among known classes to guide the clustering of novel classes. This includes generating predicted labels through the weighted fusion of factor matrices and dynamically adjusting view weights of known classes based on the supervision loss, which are then transferred to novel class learning. Experimental results validate the effectiveness of our proposed approach.
Active-Passive Federated Learning for Vertically Partitioned Multi-view Data
Sep 06, 2024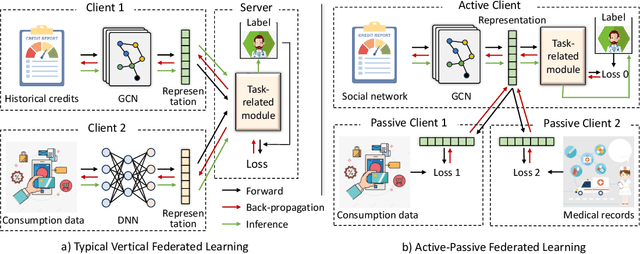


Vertical federated learning is a natural and elegant approach to integrate multi-view data vertically partitioned across devices (clients) while preserving their privacies. Apart from the model training, existing methods requires the collaboration of all clients in the model inference. However, the model inference is probably maintained for service in a long time, while the collaboration, especially when the clients belong to different organizations, is unpredictable in real-world scenarios, such as concellation of contract, network unavailablity, etc., resulting in the failure of them. To address this issue, we, at the first attempt, propose a flexible Active-Passive Federated learning (APFed) framework. Specifically, the active client is the initiator of a learning task and responsible to build the complete model, while the passive clients only serve as assistants. Once the model built, the active client can make inference independently. In addition, we instance the APFed framework into two classification methods with employing the reconstruction loss and the contrastive loss on passive clients, respectively. Meanwhile, the two methods are tested in a set of experiments and achieves desired results, validating their effectiveness.
Contrastive Continual Multi-view Clustering with Filtered Structural Fusion
Sep 26, 2023
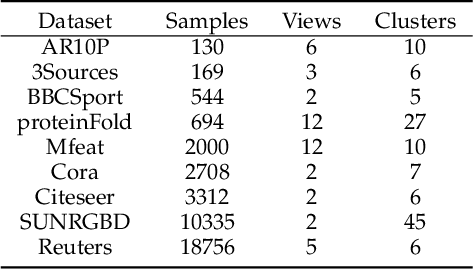
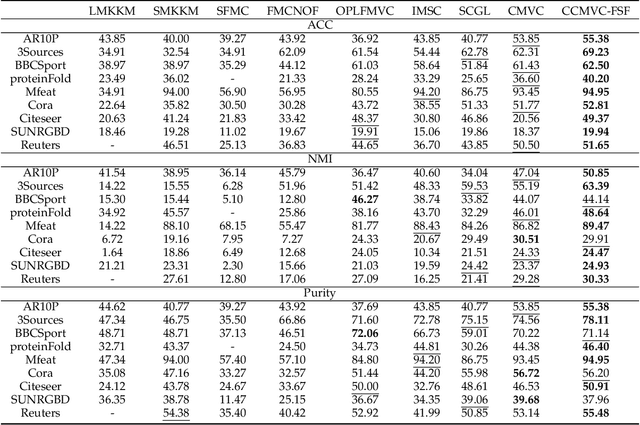

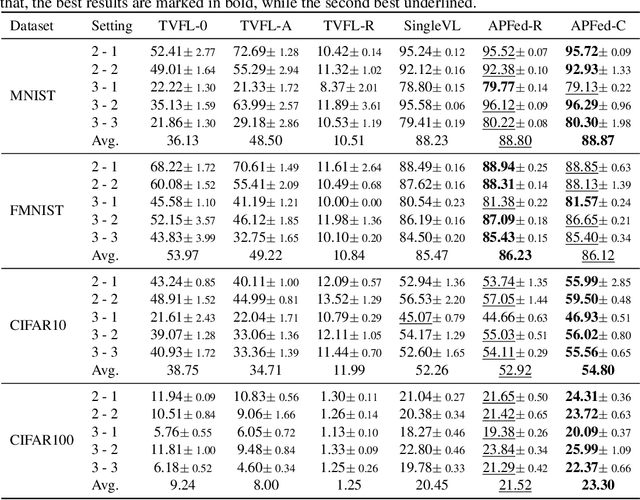
Multi-view clustering thrives in applications where views are collected in advance by extracting consistent and complementary information among views. However, it overlooks scenarios where data views are collected sequentially, i.e., real-time data. Due to privacy issues or memory burden, previous views are not available with time in these situations. Some methods are proposed to handle it but are trapped in a stability-plasticity dilemma. In specific, these methods undergo a catastrophic forgetting of prior knowledge when a new view is attained. Such a catastrophic forgetting problem (CFP) would cause the consistent and complementary information hard to get and affect the clustering performance. To tackle this, we propose a novel method termed Contrastive Continual Multi-view Clustering with Filtered Structural Fusion (CCMVC-FSF). Precisely, considering that data correlations play a vital role in clustering and prior knowledge ought to guide the clustering process of a new view, we develop a data buffer with fixed size to store filtered structural information and utilize it to guide the generation of a robust partition matrix via contrastive learning. Furthermore, we theoretically connect CCMVC-FSF with semi-supervised learning and knowledge distillation. Extensive experiments exhibit the excellence of the proposed method.
Scalable Incomplete Multi-View Clustering with Structure Alignment
Aug 31, 2023



The success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.
Efficient Multi-View Graph Clustering with Local and Global Structure Preservation
Aug 31, 2023



Anchor-based multi-view graph clustering (AMVGC) has received abundant attention owing to its high efficiency and the capability to capture complementary structural information across multiple views. Intuitively, a high-quality anchor graph plays an essential role in the success of AMVGC. However, the existing AMVGC methods only consider single-structure information, i.e., local or global structure, which provides insufficient information for the learning task. To be specific, the over-scattered global structure leads to learned anchors failing to depict the cluster partition well. In contrast, the local structure with an improper similarity measure results in potentially inaccurate anchor assignment, ultimately leading to sub-optimal clustering performance. To tackle the issue, we propose a novel anchor-based multi-view graph clustering framework termed Efficient Multi-View Graph Clustering with Local and Global Structure Preservation (EMVGC-LG). Specifically, a unified framework with a theoretical guarantee is designed to capture local and global information. Besides, EMVGC-LG jointly optimizes anchor construction and graph learning to enhance the clustering quality. In addition, EMVGC-LG inherits the linear complexity of existing AMVGC methods respecting the sample number, which is time-economical and scales well with the data size. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method.
Unpaired Multi-View Graph Clustering with Cross-View Structure Matching
Jul 07, 2023Multi-view clustering (MVC), which effectively fuses information from multiple views for better performance, has received increasing attention. Most existing MVC methods assume that multi-view data are fully paired, which means that the mappings of all corresponding samples between views are pre-defined or given in advance. However, the data correspondence is often incomplete in real-world applications due to data corruption or sensor differences, referred as the data-unpaired problem (DUP) in multi-view literature. Although several attempts have been made to address the DUP issue, they suffer from the following drawbacks: 1) Most methods focus on the feature representation while ignoring the structural information of multi-view data, which is essential for clustering tasks; 2) Existing methods for partially unpaired problems rely on pre-given cross-view alignment information, resulting in their inability to handle fully unpaired problems; 3) Their inevitable parameters degrade the efficiency and applicability of the models. To tackle these issues, we propose a novel parameter-free graph clustering framework termed Unpaired Multi-view Graph Clustering framework with Cross-View Structure Matching (UPMGC-SM). Specifically, unlike the existing methods, UPMGC-SM effectively utilizes the structural information from each view to refine cross-view correspondences. Besides, our UPMGC-SM is a unified framework for both the fully and partially unpaired multi-view graph clustering. Moreover, existing graph clustering methods can adopt our UPMGC-SM to enhance their ability for unpaired scenarios. Extensive experiments demonstrate the effectiveness and generalization of our proposed framework for both paired and unpaired datasets.
One-step Multi-view Clustering with Diverse Representation
Jun 27, 2023
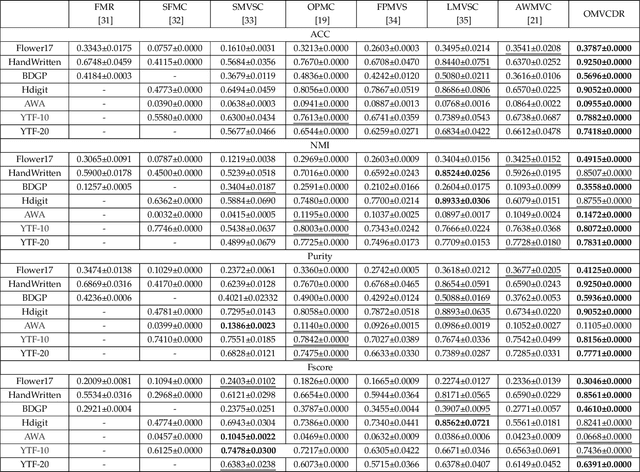

Multi-view clustering has attracted broad attention due to its capacity to utilize consistent and complementary information among views. Although tremendous progress has been made recently, most existing methods undergo high complexity, preventing them from being applied to large-scale tasks. Multi-view clustering via matrix factorization is a representative to address this issue. However, most of them map the data matrices into a fixed dimension, limiting the model's expressiveness. Moreover, a range of methods suffers from a two-step process, i.e., multimodal learning and the subsequent $k$-means, inevitably causing a sub-optimal clustering result. In light of this, we propose a one-step multi-view clustering with diverse representation method, which incorporates multi-view learning and $k$-means into a unified framework. Specifically, we first project original data matrices into various latent spaces to attain comprehensive information and auto-weight them in a self-supervised manner. Then we directly use the information matrices under diverse dimensions to obtain consensus discrete clustering labels. The unified work of representation learning and clustering boosts the quality of the final results. Furthermore, we develop an efficient optimization algorithm with proven convergence to solve the resultant problem. Comprehensive experiments on various datasets demonstrate the promising clustering performance of our proposed method.
Fast Continual Multi-View Clustering with Incomplete Views
Jun 04, 2023



Multi-view clustering (MVC) has gained broad attention owing to its capacity to exploit consistent and complementary information across views. This paper focuses on a challenging issue in MVC called the incomplete continual data problem (ICDP). In specific, most existing algorithms assume that views are available in advance and overlook the scenarios where data observations of views are accumulated over time. Due to privacy considerations or memory limitations, previous views cannot be stored in these situations. Some works are proposed to handle it, but all fail to address incomplete views. Such an incomplete continual data problem (ICDP) in MVC is tough to solve since incomplete information with continual data increases the difficulty of extracting consistent and complementary knowledge among views. We propose Fast Continual Multi-View Clustering with Incomplete Views (FCMVC-IV) to address it. Specifically, it maintains a consensus coefficient matrix and updates knowledge with the incoming incomplete view rather than storing and recomputing all the data matrices. Considering that the views are incomplete, the newly collected view might contain samples that have yet to appear; two indicator matrices and a rotation matrix are developed to match matrices with different dimensions. Besides, we design a three-step iterative algorithm to solve the resultant problem in linear complexity with proven convergence. Comprehensive experiments on various datasets show the superiority of FCMVC-IV.