 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioDER: A Deduplication-Enhanced Reasoning Dataset for Post-Training Large Audio-Language Models
Jun 12, 2026Large Audio-Language Models (LALMs) have shown strong performance on a wide range of audio understanding tasks, yet they still struggle with complex audio reasoning. A practical way to improve such capabilities is post-training, whose effectiveness critically depends on the quality and diversity of training data. However, existing audio-language datasets often contain substantial redundancy, where many samples are highly similar in acoustic content and thus provide overlapping supervisory signals. Such redundancy not only increases annotation cost, but also limits corpus diversity and reduces the effectiveness of post-training. To address this issue, we propose a redundancy-aware data construction pipeline for building reasoning-oriented supervision for LALMs. Specifically, we first perform acoustic similarity-based deduplication across raw audio datasets to improve corpus diversity. We then integrate existing audio captions and question-answer pairs into a unified multiple-choice format. Based on these unified annotations, we leverage Qwen3-30B to generate chain-of-thought (CoT) rationales for reasoning-oriented supervision. Based on this pipeline, we construct AudioDER, a reasoning-oriented post-training dataset containing approximately 191k samples spanning sound, speech, and music. Each sample consists of an audio clip, a multiple-choice question, four answer candidates, an audio caption, and a CoT rationale. Extensive experiments show that post-training on AudioDER consistently improves the performance of Qwen2-Audio-7B-Instruct on multiple audio reasoning benchmarks, including MMAU-mini, MMSU, and MMAR. We hope AudioDER can serve as a valuable resource for advancing audio reasoning research and the development of more capable LALMs.
The First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
One-step Multi-view Clustering with Diverse Representation
Jun 27, 2023
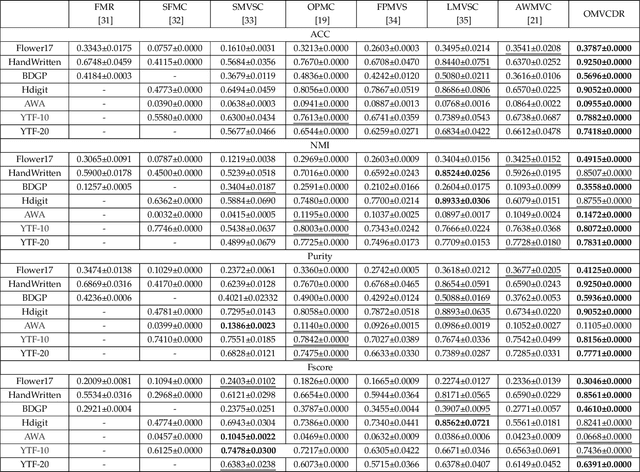

Multi-view clustering has attracted broad attention due to its capacity to utilize consistent and complementary information among views. Although tremendous progress has been made recently, most existing methods undergo high complexity, preventing them from being applied to large-scale tasks. Multi-view clustering via matrix factorization is a representative to address this issue. However, most of them map the data matrices into a fixed dimension, limiting the model's expressiveness. Moreover, a range of methods suffers from a two-step process, i.e., multimodal learning and the subsequent $k$-means, inevitably causing a sub-optimal clustering result. In light of this, we propose a one-step multi-view clustering with diverse representation method, which incorporates multi-view learning and $k$-means into a unified framework. Specifically, we first project original data matrices into various latent spaces to attain comprehensive information and auto-weight them in a self-supervised manner. Then we directly use the information matrices under diverse dimensions to obtain consensus discrete clustering labels. The unified work of representation learning and clustering boosts the quality of the final results. Furthermore, we develop an efficient optimization algorithm with proven convergence to solve the resultant problem. Comprehensive experiments on various datasets demonstrate the promising clustering performance of our proposed method.
Cheap-fake Detection with LLM using Prompt Engineering
Jun 05, 2023The misuse of real photographs with conflicting image captions in news items is an example of the out-of-context (OOC) misuse of media. In order to detect OOC media, individuals must determine the accuracy of the statement and evaluate whether the triplet (~\textit{i.e.}, the image and two captions) relates to the same event. This paper presents a novel learnable approach for detecting OOC media in ICME'23 Grand Challenge on Detecting Cheapfakes. The proposed method is based on the COSMOS structure, which assesses the coherence between an image and captions, as well as between two captions. We enhance the baseline algorithm by incorporating a Large Language Model (LLM), GPT3.5, as a feature extractor. Specifically, we propose an innovative approach to feature extraction utilizing prompt engineering to develop a robust and reliable feature extractor with GPT3.5 model. The proposed method captures the correlation between two captions and effectively integrates this module into the COSMOS baseline model, which allows for a deeper understanding of the relationship between captions. By incorporating this module, we demonstrate the potential for significant improvements in cheap-fakes detection performance. The proposed methodology holds promising implications for various applications such as natural language processing, image captioning, and text-to-image synthesis. Docker for submission is available at https://hub.docker.com/repository/docker/mulns/ acmmmcheapfakes.