 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTR-PTS: Task-Relevant Parameter and Token Selection for Efficient Tuning
Jul 30, 2025Large pre-trained models achieve remarkable performance in vision tasks but are impractical for fine-tuning due to high computational and storage costs. Parameter-Efficient Fine-Tuning (PEFT) methods mitigate this issue by updating only a subset of parameters; however, most existing approaches are task-agnostic, failing to fully exploit task-specific adaptations, which leads to suboptimal efficiency and performance. To address this limitation, we propose Task-Relevant Parameter and Token Selection (TR-PTS), a task-driven framework that enhances both computational efficiency and accuracy. Specifically, we introduce Task-Relevant Parameter Selection, which utilizes the Fisher Information Matrix (FIM) to identify and fine-tune only the most informative parameters in a layer-wise manner, while keeping the remaining parameters frozen. Simultaneously, Task-Relevant Token Selection dynamically preserves the most informative tokens and merges redundant ones, reducing computational overhead. By jointly optimizing parameters and tokens, TR-PTS enables the model to concentrate on task-discriminative information. We evaluate TR-PTS on benchmark, including FGVC and VTAB-1k, where it achieves state-of-the-art performance, surpassing full fine-tuning by 3.40% and 10.35%, respectively. The code are available at https://github.com/synbol/TR-PTS.
Face2QR: A Unified Framework for Aesthetic, Face-Preserving, and Scannable QR Code Generation
Nov 28, 2024

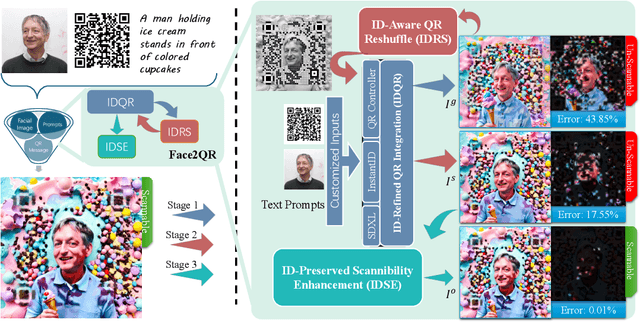

Existing methods to generate aesthetic QR codes, such as image and style transfer techniques, tend to compromise either the visual appeal or the scannability of QR codes when they incorporate human face identity. Addressing these imperfections, we present Face2QR-a novel pipeline specifically designed for generating personalized QR codes that harmoniously blend aesthetics, face identity, and scannability. Our pipeline introduces three innovative components. First, the ID-refined QR integration (IDQR) seamlessly intertwines the background styling with face ID, utilizing a unified Stable Diffusion (SD)-based framework with control networks. Second, the ID-aware QR ReShuffle (IDRS) effectively rectifies the conflicts between face IDs and QR patterns, rearranging QR modules to maintain the integrity of facial features without compromising scannability. Lastly, the ID-preserved Scannability Enhancement (IDSE) markedly boosts scanning robustness through latent code optimization, striking a delicate balance between face ID, aesthetic quality and QR functionality. In comprehensive experiments, Face2QR demonstrates remarkable performance, outperforming existing approaches, particularly in preserving facial recognition features within custom QR code designs. Codes are available at $\href{https://github.com/cavosamir/Face2QR}{\text{this URL link}}$.
Perception-Oriented Video Frame Interpolation via Asymmetric Blending
Apr 10, 2024



Previous methods for Video Frame Interpolation (VFI) have encountered challenges, notably the manifestation of blur and ghosting effects. These issues can be traced back to two pivotal factors: unavoidable motion errors and misalignment in supervision. In practice, motion estimates often prove to be error-prone, resulting in misaligned features. Furthermore, the reconstruction loss tends to bring blurry results, particularly in misaligned regions. To mitigate these challenges, we propose a new paradigm called PerVFI (Perception-oriented Video Frame Interpolation). Our approach incorporates an Asymmetric Synergistic Blending module (ASB) that utilizes features from both sides to synergistically blend intermediate features. One reference frame emphasizes primary content, while the other contributes complementary information. To impose a stringent constraint on the blending process, we introduce a self-learned sparse quasi-binary mask which effectively mitigates ghosting and blur artifacts in the output. Additionally, we employ a normalizing flow-based generator and utilize the negative log-likelihood loss to learn the conditional distribution of the output, which further facilitates the generation of clear and fine details. Experimental results validate the superiority of PerVFI, demonstrating significant improvements in perceptual quality compared to existing methods. Codes are available at \url{https://github.com/mulns/PerVFI}
Text2QR: Harmonizing Aesthetic Customization and Scanning Robustness for Text-Guided QR Code Generation
Mar 13, 2024



In the digital era, QR codes serve as a linchpin connecting virtual and physical realms. Their pervasive integration across various applications highlights the demand for aesthetically pleasing codes without compromised scannability. However, prevailing methods grapple with the intrinsic challenge of balancing customization and scannability. Notably, stable-diffusion models have ushered in an epoch of high-quality, customizable content generation. This paper introduces Text2QR, a pioneering approach leveraging these advancements to address a fundamental challenge: concurrently achieving user-defined aesthetics and scanning robustness. To ensure stable generation of aesthetic QR codes, we introduce the QR Aesthetic Blueprint (QAB) module, generating a blueprint image exerting control over the entire generation process. Subsequently, the Scannability Enhancing Latent Refinement (SELR) process refines the output iteratively in the latent space, enhancing scanning robustness. This approach harnesses the potent generation capabilities of stable-diffusion models, navigating the trade-off between image aesthetics and QR code scannability. Our experiments demonstrate the seamless fusion of visual appeal with the practical utility of aesthetic QR codes, markedly outperforming prior methods. Codes are available at \url{https://github.com/mulns/Text2QR}
AccFlow: Backward Accumulation for Long-Range Optical Flow
Aug 25, 2023
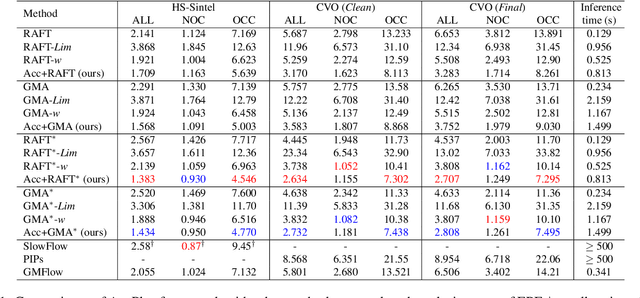
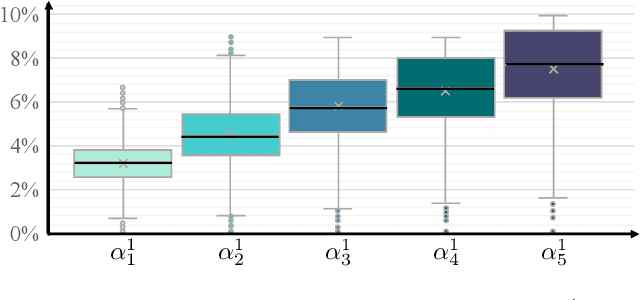
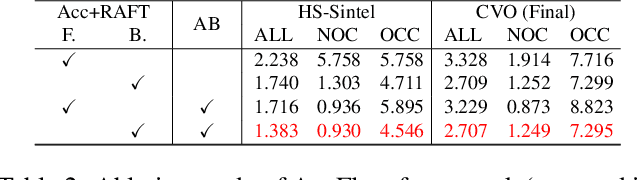
Recent deep learning-based optical flow estimators have exhibited impressive performance in generating local flows between consecutive frames. However, the estimation of long-range flows between distant frames, particularly under complex object deformation and large motion occlusion, remains a challenging task. One promising solution is to accumulate local flows explicitly or implicitly to obtain the desired long-range flow. Nevertheless, the accumulation errors and flow misalignment can hinder the effectiveness of this approach. This paper proposes a novel recurrent framework called AccFlow, which recursively backward accumulates local flows using a deformable module called as AccPlus. In addition, an adaptive blending module is designed along with AccPlus to alleviate the occlusion effect by backward accumulation and rectify the accumulation error. Notably, we demonstrate the superiority of backward accumulation over conventional forward accumulation, which to the best of our knowledge has not been explicitly established before. To train and evaluate the proposed AccFlow, we have constructed a large-scale high-quality dataset named CVO, which provides ground-truth optical flow labels between adjacent and distant frames. Extensive experiments validate the effectiveness of AccFlow in handling long-range optical flow estimation. Codes are available at https://github.com/mulns/AccFlow .
FastLLVE: Real-Time Low-Light Video Enhancement with Intensity-Aware Lookup Table
Aug 13, 2023Low-Light Video Enhancement (LLVE) has received considerable attention in recent years. One of the critical requirements of LLVE is inter-frame brightness consistency, which is essential for maintaining the temporal coherence of the enhanced video. However, most existing single-image-based methods fail to address this issue, resulting in flickering effect that degrades the overall quality after enhancement. Moreover, 3D Convolution Neural Network (CNN)-based methods, which are designed for video to maintain inter-frame consistency, are computationally expensive, making them impractical for real-time applications. To address these issues, we propose an efficient pipeline named FastLLVE that leverages the Look-Up-Table (LUT) technique to maintain inter-frame brightness consistency effectively. Specifically, we design a learnable Intensity-Aware LUT (IA-LUT) module for adaptive enhancement, which addresses the low-dynamic problem in low-light scenarios. This enables FastLLVE to perform low-latency and low-complexity enhancement operations while maintaining high-quality results. Experimental results on benchmark datasets demonstrate that our method achieves the State-Of-The-Art (SOTA) performance in terms of both image quality and inter-frame brightness consistency. More importantly, our FastLLVE can process 1,080p videos at $\mathit{50+}$ Frames Per Second (FPS), which is $\mathit{2 \times}$ faster than SOTA CNN-based methods in inference time, making it a promising solution for real-time applications. The code is available at https://github.com/Wenhao-Li-777/FastLLVE.
Cheap-fake Detection with LLM using Prompt Engineering
Jun 05, 2023The misuse of real photographs with conflicting image captions in news items is an example of the out-of-context (OOC) misuse of media. In order to detect OOC media, individuals must determine the accuracy of the statement and evaluate whether the triplet (~\textit{i.e.}, the image and two captions) relates to the same event. This paper presents a novel learnable approach for detecting OOC media in ICME'23 Grand Challenge on Detecting Cheapfakes. The proposed method is based on the COSMOS structure, which assesses the coherence between an image and captions, as well as between two captions. We enhance the baseline algorithm by incorporating a Large Language Model (LLM), GPT3.5, as a feature extractor. Specifically, we propose an innovative approach to feature extraction utilizing prompt engineering to develop a robust and reliable feature extractor with GPT3.5 model. The proposed method captures the correlation between two captions and effectively integrates this module into the COSMOS baseline model, which allows for a deeper understanding of the relationship between captions. By incorporating this module, we demonstrate the potential for significant improvements in cheap-fakes detection performance. The proposed methodology holds promising implications for various applications such as natural language processing, image captioning, and text-to-image synthesis. Docker for submission is available at https://hub.docker.com/repository/docker/mulns/ acmmmcheapfakes.
H-VFI: Hierarchical Frame Interpolation for Videos with Large Motions
Nov 21, 2022
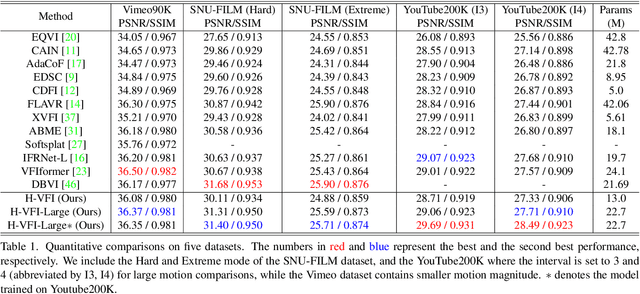
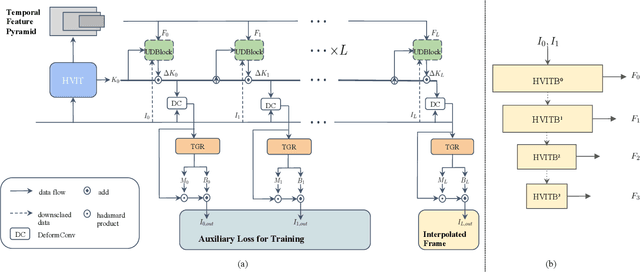
Capitalizing on the rapid development of neural networks, recent video frame interpolation (VFI) methods have achieved notable improvements. However, they still fall short for real-world videos containing large motions. Complex deformation and/or occlusion caused by large motions make it an extremely difficult problem in video frame interpolation. In this paper, we propose a simple yet effective solution, H-VFI, to deal with large motions in video frame interpolation. H-VFI contributes a hierarchical video interpolation transformer (HVIT) to learn a deformable kernel in a coarse-to-fine strategy in multiple scales. The learnt deformable kernel is then utilized in convolving the input frames for predicting the interpolated frame. Starting from the smallest scale, H-VFI updates the deformable kernel by a residual in succession based on former predicted kernels, intermediate interpolated results and hierarchical features from transformer. Bias and masks to refine the final outputs are then predicted by a transformer block based on interpolated results. The advantage of such a progressive approximation is that the large motion frame interpolation problem can be decomposed into several relatively simpler sub-tasks, which enables a very accurate prediction in the final results. Another noteworthy contribution of our paper consists of a large-scale high-quality dataset, YouTube200K, which contains videos depicting a great variety of scenarios captured at high resolution and high frame rate. Extensive experiments on multiple frame interpolation benchmarks validate that H-VFI outperforms existing state-of-the-art methods especially for videos with large motions.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020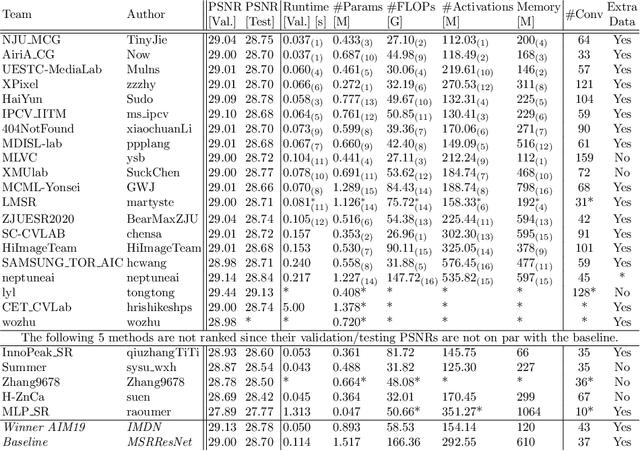
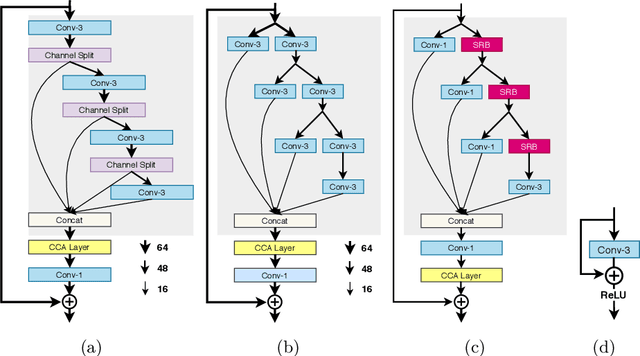
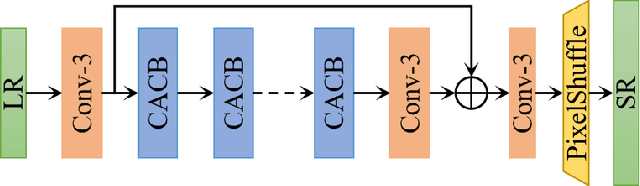
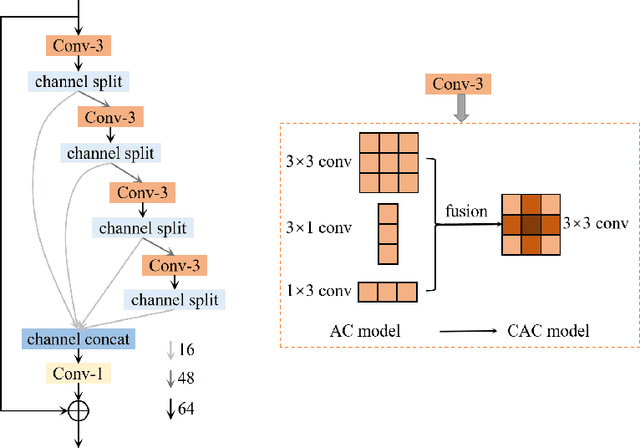
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.