 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-VFI: Hierarchical Frame Interpolation for Videos with Large Motions
Paper and Code
Nov 21, 2022
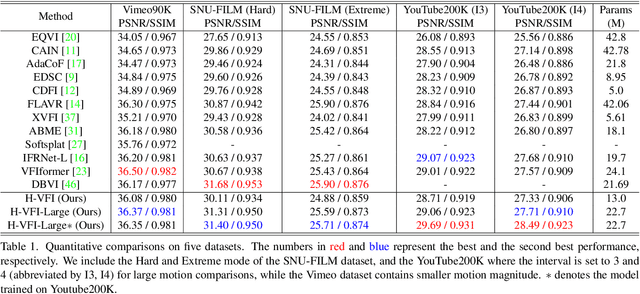
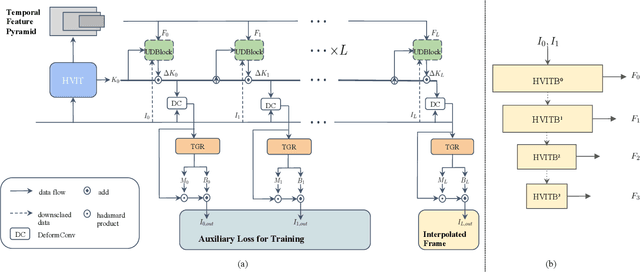
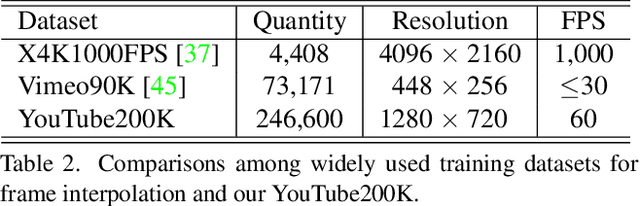
Capitalizing on the rapid development of neural networks, recent video frame interpolation (VFI) methods have achieved notable improvements. However, they still fall short for real-world videos containing large motions. Complex deformation and/or occlusion caused by large motions make it an extremely difficult problem in video frame interpolation. In this paper, we propose a simple yet effective solution, H-VFI, to deal with large motions in video frame interpolation. H-VFI contributes a hierarchical video interpolation transformer (HVIT) to learn a deformable kernel in a coarse-to-fine strategy in multiple scales. The learnt deformable kernel is then utilized in convolving the input frames for predicting the interpolated frame. Starting from the smallest scale, H-VFI updates the deformable kernel by a residual in succession based on former predicted kernels, intermediate interpolated results and hierarchical features from transformer. Bias and masks to refine the final outputs are then predicted by a transformer block based on interpolated results. The advantage of such a progressive approximation is that the large motion frame interpolation problem can be decomposed into several relatively simpler sub-tasks, which enables a very accurate prediction in the final results. Another noteworthy contribution of our paper consists of a large-scale high-quality dataset, YouTube200K, which contains videos depicting a great variety of scenarios captured at high resolution and high frame rate. Extensive experiments on multiple frame interpolation benchmarks validate that H-VFI outperforms existing state-of-the-art methods especially for videos with large motions.