 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT: Influence Modeling for Open-Set Time Series Anomaly Detection
Mar 31, 2026Open-set anomaly detection (OSAD) is an emerging paradigm designed to utilize limited labeled data from anomaly classes seen in training to identify both seen and unseen anomalies during testing. Current approaches rely on simple augmentation methods to generate pseudo anomalies that replicate unseen anomalies. Despite being promising in image data, these methods are found to be ineffective in time series data due to the failure to preserve its sequential nature, resulting in trivial or unrealistic anomaly patterns. They are further plagued when the training data is contaminated with unlabeled anomalies. This work introduces $\textbf{IMPACT}$, a novel framework that leverages $\underline{\textbf{i}}$nfluence $\underline{\textbf{m}}$odeling for o$\underline{\textbf{p}}$en-set time series $\underline{\textbf{a}}$nomaly dete$\underline{\textbf{ct}}$ion, to tackle these challenges. The key insight is to $\textbf{i)}$ learn an influence function that can accurately estimate the impact of individual training samples on the modeling, and then $\textbf{ii)}$ leverage these influence scores to generate semantically divergent yet realistic unseen anomalies for time series while repurposing high-influential samples as supervised anomalies for anomaly decontamination. Extensive experiments show that IMPACT significantly outperforms existing state-of-the-art methods, showing superior accuracy under varying OSAD settings and contamination rates.
Enhancing Kernel Power K-means: Scalable and Robust Clustering with Random Fourier Features and Possibilistic Method
Nov 13, 2025Kernel power $k$-means (KPKM) leverages a family of means to mitigate local minima issues in kernel $k$-means. However, KPKM faces two key limitations: (1) the computational burden of the full kernel matrix restricts its use on extensive data, and (2) the lack of authentic centroid-sample assignment learning reduces its noise robustness. To overcome these challenges, we propose RFF-KPKM, introducing the first approximation theory for applying random Fourier features (RFF) to KPKM. RFF-KPKM employs RFF to generate efficient, low-dimensional feature maps, bypassing the need for the whole kernel matrix. Crucially, we are the first to establish strong theoretical guarantees for this combination: (1) an excess risk bound of $\mathcal{O}(\sqrt{k^3/n})$, (2) strong consistency with membership values, and (3) a $(1+\varepsilon)$ relative error bound achievable using the RFF of dimension $\mathrm{poly}(\varepsilon^{-1}\log k)$. Furthermore, to improve robustness and the ability to learn multiple kernels, we propose IP-RFF-MKPKM, an improved possibilistic RFF-based multiple kernel power $k$-means. IP-RFF-MKPKM ensures the scalability of MKPKM via RFF and refines cluster assignments by combining the merits of the possibilistic membership and fuzzy membership. Experiments on large-scale datasets demonstrate the superior efficiency and clustering accuracy of the proposed methods compared to the state-of-the-art alternatives.
Scalable Incomplete Multi-View Clustering with Structure Alignment
Aug 31, 2023



The success of existing multi-view clustering (MVC) relies on the assumption that all views are complete. However, samples are usually partially available due to data corruption or sensor malfunction, which raises the research of incomplete multi-view clustering (IMVC). Although several anchor-based IMVC methods have been proposed to process the large-scale incomplete data, they still suffer from the following drawbacks: i) Most existing approaches neglect the inter-view discrepancy and enforce cross-view representation to be consistent, which would corrupt the representation capability of the model; ii) Due to the samples disparity between different views, the learned anchor might be misaligned, which we referred as the Anchor-Unaligned Problem for Incomplete data (AUP-ID). Such the AUP-ID would cause inaccurate graph fusion and degrades clustering performance. To tackle these issues, we propose a novel incomplete anchor graph learning framework termed Scalable Incomplete Multi-View Clustering with Structure Alignment (SIMVC-SA). Specially, we construct the view-specific anchor graph to capture the complementary information from different views. In order to solve the AUP-ID, we propose a novel structure alignment module to refine the cross-view anchor correspondence. Meanwhile, the anchor graph construction and alignment are jointly optimized in our unified framework to enhance clustering quality. Through anchor graph construction instead of full graphs, the time and space complexity of the proposed SIMVC-SA is proven to be linearly correlated with the number of samples. Extensive experiments on seven incomplete benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Our code is publicly available at https://github.com/wy1019/SIMVC-SA.
Unpaired Multi-View Graph Clustering with Cross-View Structure Matching
Jul 07, 2023Multi-view clustering (MVC), which effectively fuses information from multiple views for better performance, has received increasing attention. Most existing MVC methods assume that multi-view data are fully paired, which means that the mappings of all corresponding samples between views are pre-defined or given in advance. However, the data correspondence is often incomplete in real-world applications due to data corruption or sensor differences, referred as the data-unpaired problem (DUP) in multi-view literature. Although several attempts have been made to address the DUP issue, they suffer from the following drawbacks: 1) Most methods focus on the feature representation while ignoring the structural information of multi-view data, which is essential for clustering tasks; 2) Existing methods for partially unpaired problems rely on pre-given cross-view alignment information, resulting in their inability to handle fully unpaired problems; 3) Their inevitable parameters degrade the efficiency and applicability of the models. To tackle these issues, we propose a novel parameter-free graph clustering framework termed Unpaired Multi-view Graph Clustering framework with Cross-View Structure Matching (UPMGC-SM). Specifically, unlike the existing methods, UPMGC-SM effectively utilizes the structural information from each view to refine cross-view correspondences. Besides, our UPMGC-SM is a unified framework for both the fully and partially unpaired multi-view graph clustering. Moreover, existing graph clustering methods can adopt our UPMGC-SM to enhance their ability for unpaired scenarios. Extensive experiments demonstrate the effectiveness and generalization of our proposed framework for both paired and unpaired datasets.
Fast Continual Multi-View Clustering with Incomplete Views
Jun 04, 2023



Multi-view clustering (MVC) has gained broad attention owing to its capacity to exploit consistent and complementary information across views. This paper focuses on a challenging issue in MVC called the incomplete continual data problem (ICDP). In specific, most existing algorithms assume that views are available in advance and overlook the scenarios where data observations of views are accumulated over time. Due to privacy considerations or memory limitations, previous views cannot be stored in these situations. Some works are proposed to handle it, but all fail to address incomplete views. Such an incomplete continual data problem (ICDP) in MVC is tough to solve since incomplete information with continual data increases the difficulty of extracting consistent and complementary knowledge among views. We propose Fast Continual Multi-View Clustering with Incomplete Views (FCMVC-IV) to address it. Specifically, it maintains a consensus coefficient matrix and updates knowledge with the incoming incomplete view rather than storing and recomputing all the data matrices. Considering that the views are incomplete, the newly collected view might contain samples that have yet to appear; two indicator matrices and a rotation matrix are developed to match matrices with different dimensions. Besides, we design a three-step iterative algorithm to solve the resultant problem in linear complexity with proven convergence. Comprehensive experiments on various datasets show the superiority of FCMVC-IV.
Multi-View Spectral Clustering with High-Order Optimal Neighborhood Laplacian Matrix
Aug 31, 2020
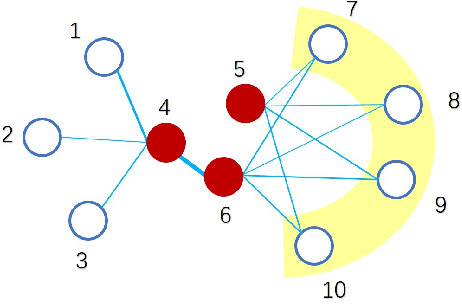
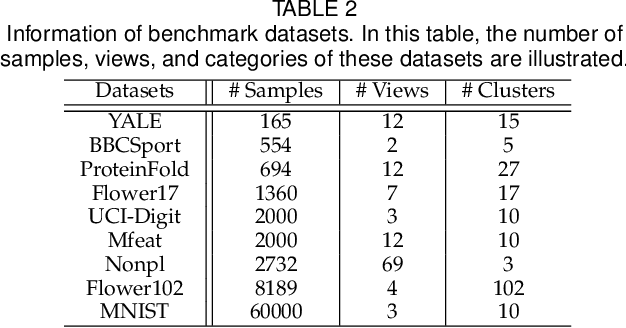
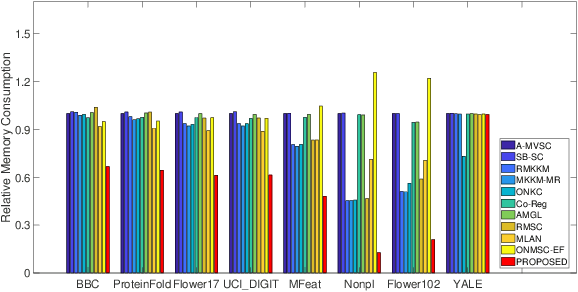
Multi-view spectral clustering can effectively reveal the intrinsic cluster structure among data by performing clustering on the learned optimal embedding across views. Though demonstrating promising performance in various applications, most of existing methods usually linearly combine a group of pre-specified first-order Laplacian matrices to construct the optimal Laplacian matrix, which may result in limited representation capability and insufficient information exploitation. Also, storing and implementing complex operations on the $n\times n$ Laplacian matrices incurs intensive storage and computation complexity. To address these issues, this paper first proposes a multi-view spectral clustering algorithm that learns a high-order optimal neighborhood Laplacian matrix, and then extends it to the late fusion version for accurate and efficient multi-view clustering. Specifically, our proposed algorithm generates the optimal Laplacian matrix by searching the neighborhood of the linear combination of both the first-order and high-order base Laplacian matrices simultaneously. By this way, the representative capacity of the learned optimal Laplacian matrix is enhanced, which is helpful to better utilize the hidden high-order connection information among data, leading to improved clustering performance. We design an efficient algorithm with proved convergence to solve the resultant optimization problem. Extensive experimental results on nine datasets demonstrate the superiority of our algorithm against state-of-the-art methods, which verifies the effectiveness and advantages of the proposed algorithm.