 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Deep Multi-view Clustering via Causal Learning with Partially Aligned Cross-view Correspondence
Sep 19, 2025Multi-view clustering (MVC) aims to explore the common clustering structure across multiple views. Many existing MVC methods heavily rely on the assumption of view consistency, where alignments for corresponding samples across different views are ordered in advance. However, real-world scenarios often present a challenge as only partial data is consistently aligned across different views, restricting the overall clustering performance. In this work, we consider the model performance decreasing phenomenon caused by data order shift (i.e., from fully to partially aligned) as a generalized multi-view clustering problem. To tackle this problem, we design a causal multi-view clustering network, termed CauMVC. We adopt a causal modeling approach to understand multi-view clustering procedure. To be specific, we formulate the partially aligned data as an intervention and multi-view clustering with partially aligned data as an post-intervention inference. However, obtaining invariant features directly can be challenging. Thus, we design a Variational Auto-Encoder for causal learning by incorporating an encoder from existing information to estimate the invariant features. Moreover, a decoder is designed to perform the post-intervention inference. Lastly, we design a contrastive regularizer to capture sample correlations. To the best of our knowledge, this paper is the first work to deal generalized multi-view clustering via causal learning. Empirical experiments on both fully and partially aligned data illustrate the strong generalization and effectiveness of CauMVC.
Automatically Identify and Rectify: Robust Deep Contrastive Multi-view Clustering in Noisy Scenarios
May 27, 2025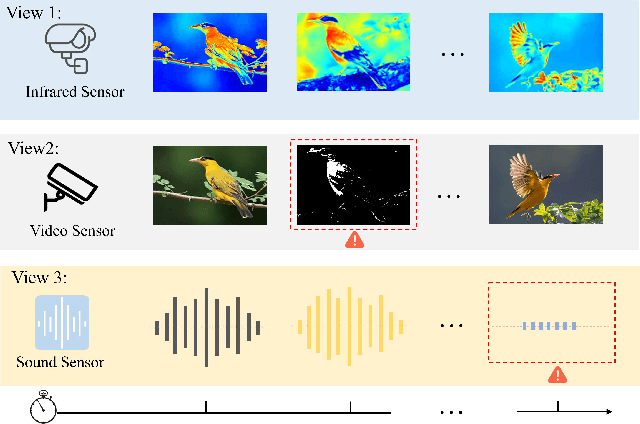
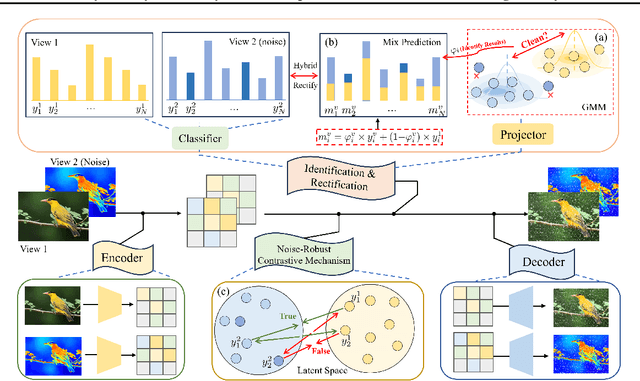

Leveraging the powerful representation learning capabilities, deep multi-view clustering methods have demonstrated reliable performance by effectively integrating multi-source information from diverse views in recent years. Most existing methods rely on the assumption of clean views. However, noise is pervasive in real-world scenarios, leading to a significant degradation in performance. To tackle this problem, we propose a novel multi-view clustering framework for the automatic identification and rectification of noisy data, termed AIRMVC. Specifically, we reformulate noisy identification as an anomaly identification problem using GMM. We then design a hybrid rectification strategy to mitigate the adverse effects of noisy data based on the identification results. Furthermore, we introduce a noise-robust contrastive mechanism to generate reliable representations. Additionally, we provide a theoretical proof demonstrating that these representations can discard noisy information, thereby improving the performance of downstream tasks. Extensive experiments on six benchmark datasets demonstrate that AIRMVC outperforms state-of-the-art algorithms in terms of robustness in noisy scenarios. The code of AIRMVC are available at https://github.com/xihongyang1999/AIRMVC on Github.
Imputation-free and Alignment-free: Incomplete Multi-view Clustering Driven by Consensus Semantic Learning
May 16, 2025In incomplete multi-view clustering (IMVC), missing data induce prototype shifts within views and semantic inconsistencies across views. A feasible solution is to explore cross-view consistency in paired complete observations, further imputing and aligning the similarity relationships inherently shared across views. Nevertheless, existing methods are constrained by two-tiered limitations: (1) Neither instance- nor cluster-level consistency learning construct a semantic space shared across views to learn consensus semantics. The former enforces cross-view instances alignment, and wrongly regards unpaired observations with semantic consistency as negative pairs; the latter focuses on cross-view cluster counterparts while coarsely handling fine-grained intra-cluster relationships within views. (2) Excessive reliance on consistency results in unreliable imputation and alignment without incorporating view-specific cluster information. Thus, we propose an IMVC framework, imputation- and alignment-free for consensus semantics learning (FreeCSL). To bridge semantic gaps across all observations, we learn consensus prototypes from available data to discover a shared space, where semantically similar observations are pulled closer for consensus semantics learning. To capture semantic relationships within specific views, we design a heuristic graph clustering based on modularity to recover cluster structure with intra-cluster compactness and inter-cluster separation for cluster semantics enhancement. Extensive experiments demonstrate, compared to state-of-the-art competitors, FreeCSL achieves more confident and robust assignments on IMVC task.
DealMVC: Dual Contrastive Calibration for Multi-view Clustering
Sep 02, 2023


Benefiting from the strong view-consistent information mining capacity, multi-view contrastive clustering has attracted plenty of attention in recent years. However, we observe the following drawback, which limits the clustering performance from further improvement. The existing multi-view models mainly focus on the consistency of the same samples in different views while ignoring the circumstance of similar but different samples in cross-view scenarios. To solve this problem, we propose a novel Dual contrastive calibration network for Multi-View Clustering (DealMVC). Specifically, we first design a fusion mechanism to obtain a global cross-view feature. Then, a global contrastive calibration loss is proposed by aligning the view feature similarity graph and the high-confidence pseudo-label graph. Moreover, to utilize the diversity of multi-view information, we propose a local contrastive calibration loss to constrain the consistency of pair-wise view features. The feature structure is regularized by reliable class information, thus guaranteeing similar samples have similar features in different views. During the training procedure, the interacted cross-view feature is jointly optimized at both local and global levels. In comparison with other state-of-the-art approaches, the comprehensive experimental results obtained from eight benchmark datasets provide substantial validation of the effectiveness and superiority of our algorithm. We release the code of DealMVC at https://github.com/xihongyang1999/DealMVC on GitHub.
Deep Incomplete Multi-view Clustering with Cross-view Partial Sample and Prototype Alignment
Mar 30, 2023The success of existing multi-view clustering relies on the assumption of sample integrity across multiple views. However, in real-world scenarios, samples of multi-view are partially available due to data corruption or sensor failure, which leads to incomplete multi-view clustering study (IMVC). Although several attempts have been proposed to address IMVC, they suffer from the following drawbacks: i) Existing methods mainly adopt cross-view contrastive learning forcing the representations of each sample across views to be exactly the same, which might ignore view discrepancy and flexibility in representations; ii) Due to the absence of non-observed samples across multiple views, the obtained prototypes of clusters might be unaligned and biased, leading to incorrect fusion. To address the above issues, we propose a Cross-view Partial Sample and Prototype Alignment Network (CPSPAN) for Deep Incomplete Multi-view Clustering. Firstly, unlike existing contrastive-based methods, we adopt pair-observed data alignment as 'proxy supervised signals' to guide instance-to-instance correspondence construction among views. Then, regarding of the shifted prototypes in IMVC, we further propose a prototype alignment module to achieve incomplete distribution calibration across views. Extensive experimental results showcase the effectiveness of our proposed modules, attaining noteworthy performance improvements when compared to existing IMVC competitors on benchmark datasets.
Align then Fusion: Generalized Large-scale Multi-view Clustering with Anchor Matching Correspondences
May 30, 2022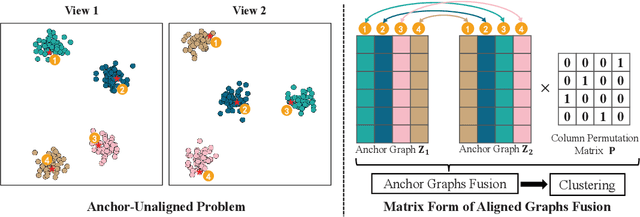
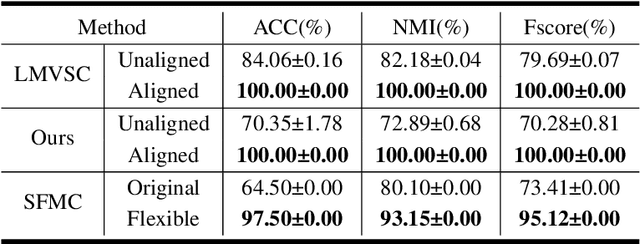
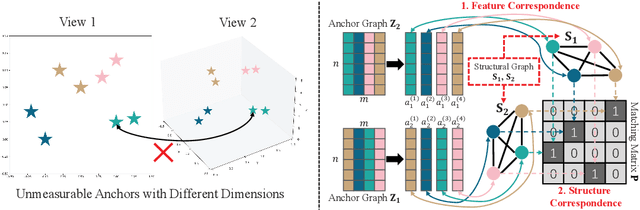
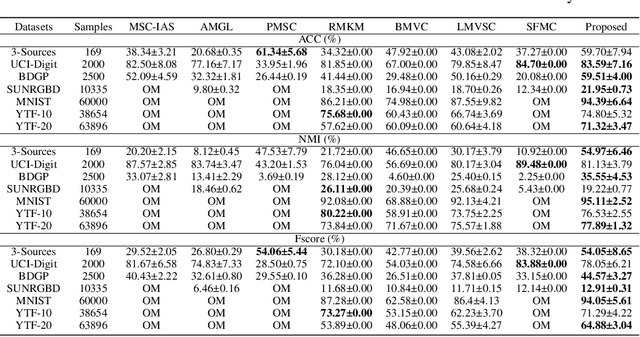
Multi-view anchor graph clustering selects representative anchors to avoid full pair-wise similarities and therefore reduce the complexity of graph methods. Although widely applied in large-scale applications, existing approaches do not pay sufficient attention to establishing correct correspondences between the anchor sets across views. To be specific, anchor graphs obtained from different views are not aligned column-wisely. Such an Anchor-Unaligned Problem (AUP) would cause inaccurate graph fusion and degrade the clustering performance. Under multi-view scenarios, generating correct correspondences could be extremely difficult since anchors are not consistent in feature dimensions. To solve this challenging issue, we propose the first study of a generalized and flexible anchor graph fusion framework termed Fast Multi-View Anchor-Correspondence Clustering (FMVACC). Specifically, we show how to find anchor correspondence with both feature and structure information, after which anchor graph fusion is performed column-wisely. Moreover, we theoretically show the connection between FMVACC and existing multi-view late fusion and partial view-aligned clustering, which further demonstrates our generality. Extensive experiments on seven benchmark datasets demonstrate the effectiveness and efficiency of our proposed method. Moreover, the proposed alignment module also shows significant performance improvement applying to existing multi-view anchor graph competitors indicating the importance of anchor alignment.
Asymptotically Unbiased Estimation for Delayed Feedback Modeling via Label Correction
Feb 15, 2022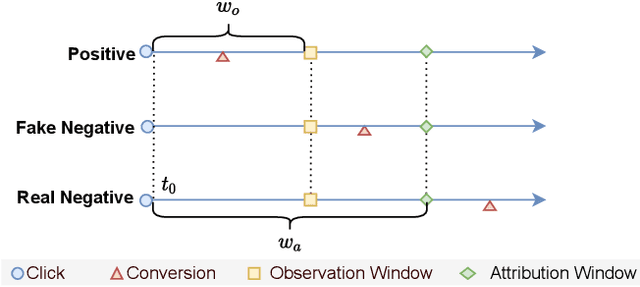
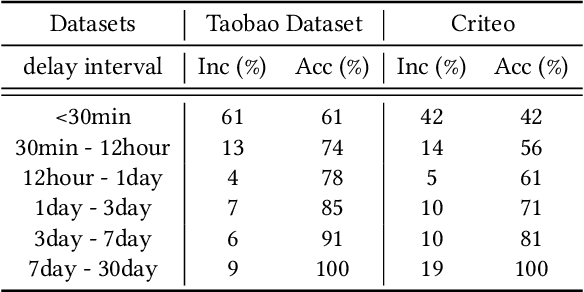

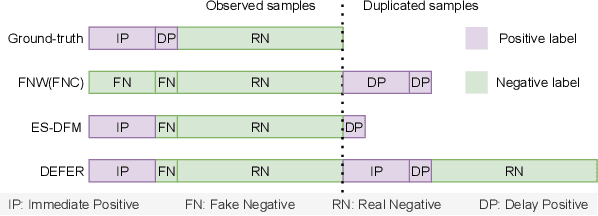
Alleviating the delayed feedback problem is of crucial importance for the conversion rate(CVR) prediction in online advertising. Previous delayed feedback modeling methods using an observation window to balance the trade-off between waiting for accurate labels and consuming fresh feedback. Moreover, to estimate CVR upon the freshly observed but biased distribution with fake negatives, the importance sampling is widely used to reduce the distribution bias. While effective, we argue that previous approaches falsely treat fake negative samples as real negative during the importance weighting and have not fully utilized the observed positive samples, leading to suboptimal performance. In this work, we propose a new method, DElayed Feedback modeling with UnbiaSed Estimation, (DEFUSE), which aim to respectively correct the importance weights of the immediate positive, the fake negative, the real negative, and the delay positive samples at finer granularity. Specifically, we propose a two-step optimization approach that first infers the probability of fake negatives among observed negatives before applying importance sampling. To fully exploit the ground-truth immediate positives from the observed distribution, we further develop a bi-distribution modeling framework to jointly model the unbiased immediate positives and the biased delay conversions. Experimental results on both public and our industrial datasets validate the superiority of DEFUSE. Codes are available at https://github.com/ychen216/DEFUSE.git.