 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImputation-free and Alignment-free: Incomplete Multi-view Clustering Driven by Consensus Semantic Learning
May 16, 2025In incomplete multi-view clustering (IMVC), missing data induce prototype shifts within views and semantic inconsistencies across views. A feasible solution is to explore cross-view consistency in paired complete observations, further imputing and aligning the similarity relationships inherently shared across views. Nevertheless, existing methods are constrained by two-tiered limitations: (1) Neither instance- nor cluster-level consistency learning construct a semantic space shared across views to learn consensus semantics. The former enforces cross-view instances alignment, and wrongly regards unpaired observations with semantic consistency as negative pairs; the latter focuses on cross-view cluster counterparts while coarsely handling fine-grained intra-cluster relationships within views. (2) Excessive reliance on consistency results in unreliable imputation and alignment without incorporating view-specific cluster information. Thus, we propose an IMVC framework, imputation- and alignment-free for consensus semantics learning (FreeCSL). To bridge semantic gaps across all observations, we learn consensus prototypes from available data to discover a shared space, where semantically similar observations are pulled closer for consensus semantics learning. To capture semantic relationships within specific views, we design a heuristic graph clustering based on modularity to recover cluster structure with intra-cluster compactness and inter-cluster separation for cluster semantics enhancement. Extensive experiments demonstrate, compared to state-of-the-art competitors, FreeCSL achieves more confident and robust assignments on IMVC task.
Single-cell Multi-view Clustering via Community Detection with Unknown Number of Clusters
Nov 28, 2023



Single-cell multi-view clustering enables the exploration of cellular heterogeneity within the same cell from different views. Despite the development of several multi-view clustering methods, two primary challenges persist. Firstly, most existing methods treat the information from both single-cell RNA (scRNA) and single-cell Assay of Transposase Accessible Chromatin (scATAC) views as equally significant, overlooking the substantial disparity in data richness between the two views. This oversight frequently leads to a degradation in overall performance. Additionally, the majority of clustering methods necessitate manual specification of the number of clusters by users. However, for biologists dealing with cell data, precisely determining the number of distinct cell types poses a formidable challenge. To this end, we introduce scUNC, an innovative multi-view clustering approach tailored for single-cell data, which seamlessly integrates information from different views without the need for a predefined number of clusters. The scUNC method comprises several steps: initially, it employs a cross-view fusion network to create an effective embedding, which is then utilized to generate initial clusters via community detection. Subsequently, the clusters are automatically merged and optimized until no further clusters can be merged. We conducted a comprehensive evaluation of scUNC using three distinct single-cell datasets. The results underscored that scUNC outperforms the other baseline methods.
Deep Incomplete Multi-view Clustering with Cross-view Partial Sample and Prototype Alignment
Mar 30, 2023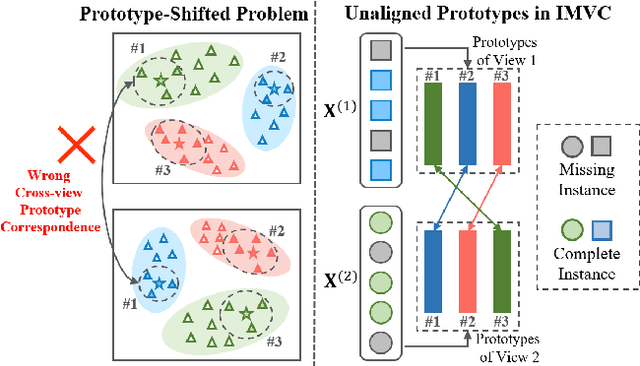
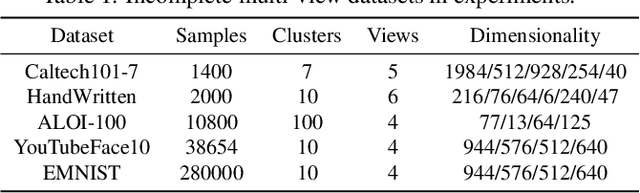
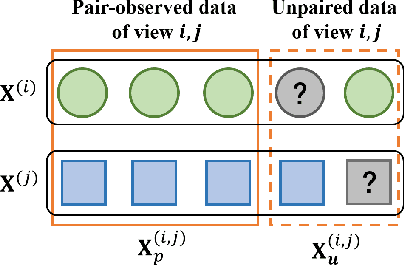
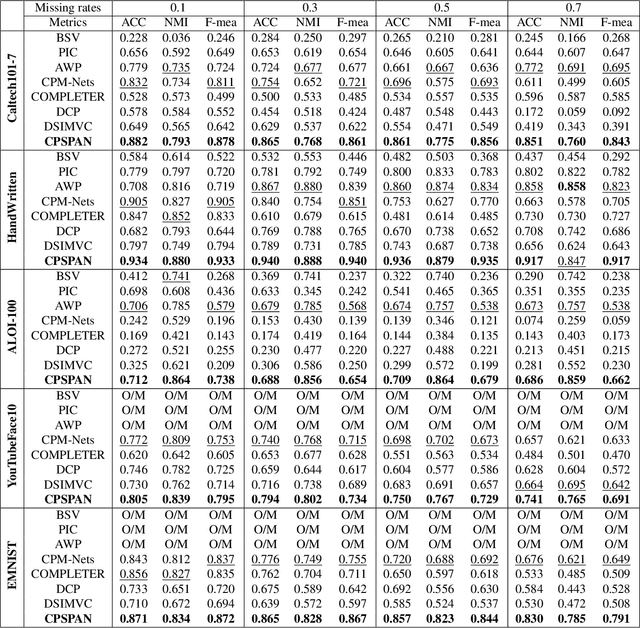
The success of existing multi-view clustering relies on the assumption of sample integrity across multiple views. However, in real-world scenarios, samples of multi-view are partially available due to data corruption or sensor failure, which leads to incomplete multi-view clustering study (IMVC). Although several attempts have been proposed to address IMVC, they suffer from the following drawbacks: i) Existing methods mainly adopt cross-view contrastive learning forcing the representations of each sample across views to be exactly the same, which might ignore view discrepancy and flexibility in representations; ii) Due to the absence of non-observed samples across multiple views, the obtained prototypes of clusters might be unaligned and biased, leading to incorrect fusion. To address the above issues, we propose a Cross-view Partial Sample and Prototype Alignment Network (CPSPAN) for Deep Incomplete Multi-view Clustering. Firstly, unlike existing contrastive-based methods, we adopt pair-observed data alignment as 'proxy supervised signals' to guide instance-to-instance correspondence construction among views. Then, regarding of the shifted prototypes in IMVC, we further propose a prototype alignment module to achieve incomplete distribution calibration across views. Extensive experimental results showcase the effectiveness of our proposed modules, attaining noteworthy performance improvements when compared to existing IMVC competitors on benchmark datasets.
Graph Anomaly Detection via Multi-Scale Contrastive Learning Networks with Augmented View
Dec 02, 2022



Graph anomaly detection (GAD) is a vital task in graph-based machine learning and has been widely applied in many real-world applications. The primary goal of GAD is to capture anomalous nodes from graph datasets, which evidently deviate from the majority of nodes. Recent methods have paid attention to various scales of contrastive strategies for GAD, i.e., node-subgraph and node-node contrasts. However, they neglect the subgraph-subgraph comparison information which the normal and abnormal subgraph pairs behave differently in terms of embeddings and structures in GAD, resulting in sub-optimal task performance. In this paper, we fulfill the above idea in the proposed multi-view multi-scale contrastive learning framework with subgraph-subgraph contrast for the first practice. To be specific, we regard the original input graph as the first view and generate the second view by graph augmentation with edge modifications. With the guidance of maximizing the similarity of the subgraph pairs, the proposed subgraph-subgraph contrast contributes to more robust subgraph embeddings despite of the structure variation. Moreover, the introduced subgraph-subgraph contrast cooperates well with the widely-adopted node-subgraph and node-node contrastive counterparts for mutual GAD performance promotions. Besides, we also conduct sufficient experiments to investigate the impact of different graph augmentation approaches on detection performance. The comprehensive experimental results well demonstrate the superiority of our method compared with the state-of-the-art approaches and the effectiveness of the multi-view subgraph pair contrastive strategy for the GAD task.