 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrappa: Gradient-Only Communication for Scalable Graph Neural Network Training
Feb 02, 2026Cross-partition edges dominate the cost of distributed GNN training: fetching remote features and activations per iteration overwhelms the network as graphs deepen and partition counts grow. Grappa is a distributed GNN training framework that enforces gradient-only communication: during each iteration, partitions train in isolation and exchange only gradients for the global update. To recover accuracy lost to isolation, Grappa (i) periodically repartitions to expose new neighborhoods and (ii) applies a lightweight coverage-corrected gradient aggregation inspired by importance sampling. We prove the corrected estimator is asymptotically unbiased under standard support and boundedness assumptions, and we derive a batch-level variant for compatibility with common deep-learning packages that minimizes mean-squared deviation from the ideal node-level correction. We also introduce a shrinkage version that improves stability in practice. Empirical results on real and synthetic graphs show that Grappa trains GNNs 4 times faster on average (up to 13 times) than state-of-the-art systems, achieves better accuracy especially for deeper models, and sustains training at the trillion-edge scale on commodity hardware. Grappa is model-agnostic, supports full-graph and mini-batch training, and does not rely on high-bandwidth interconnects or caching.
Reconstructing Close Human Interaction with Appearance and Proxemics Reasoning
Jul 03, 2025Due to visual ambiguities and inter-person occlusions, existing human pose estimation methods cannot recover plausible close interactions from in-the-wild videos. Even state-of-the-art large foundation models~(\eg, SAM) cannot accurately distinguish human semantics in such challenging scenarios. In this work, we find that human appearance can provide a straightforward cue to address these obstacles. Based on this observation, we propose a dual-branch optimization framework to reconstruct accurate interactive motions with plausible body contacts constrained by human appearances, social proxemics, and physical laws. Specifically, we first train a diffusion model to learn the human proxemic behavior and pose prior knowledge. The trained network and two optimizable tensors are then incorporated into a dual-branch optimization framework to reconstruct human motions and appearances. Several constraints based on 3D Gaussians, 2D keypoints, and mesh penetrations are also designed to assist the optimization. With the proxemics prior and diverse constraints, our method is capable of estimating accurate interactions from in-the-wild videos captured in complex environments. We further build a dataset with pseudo ground-truth interaction annotations, which may promote future research on pose estimation and human behavior understanding. Experimental results on several benchmarks demonstrate that our method outperforms existing approaches. The code and data are available at https://www.buzhenhuang.com/works/CloseApp.html.
Adapting Human Mesh Recovery with Vision-Language Feedback
Feb 06, 2025



Human mesh recovery can be approached using either regression-based or optimization-based methods. Regression models achieve high pose accuracy but struggle with model-to-image alignment due to the lack of explicit 2D-3D correspondences. In contrast, optimization-based methods align 3D models to 2D observations but are prone to local minima and depth ambiguity. In this work, we leverage large vision-language models (VLMs) to generate interactive body part descriptions, which serve as implicit constraints to enhance 3D perception and limit the optimization space. Specifically, we formulate monocular human mesh recovery as a distribution adaptation task by integrating both 2D observations and language descriptions. To bridge the gap between text and 3D pose signals, we first train a text encoder and a pose VQ-VAE, aligning texts to body poses in a shared latent space using contrastive learning. Subsequently, we employ a diffusion-based framework to refine the initial parameters guided by gradients derived from both 2D observations and text descriptions. Finally, the model can produce poses with accurate 3D perception and image consistency. Experimental results on multiple benchmarks validate its effectiveness. The code will be made publicly available.
Closely Interactive Human Reconstruction with Proxemics and Physics-Guided Adaption
Apr 17, 2024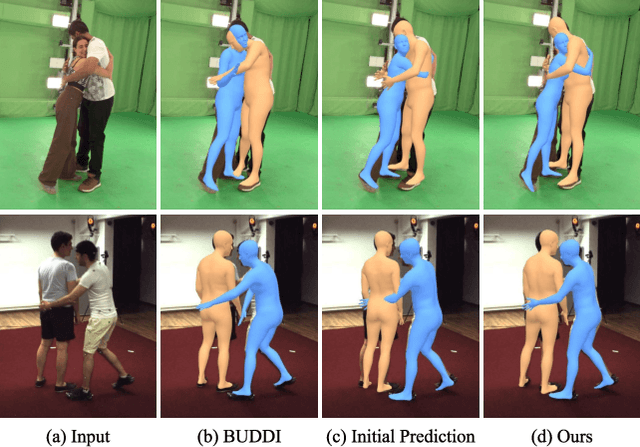
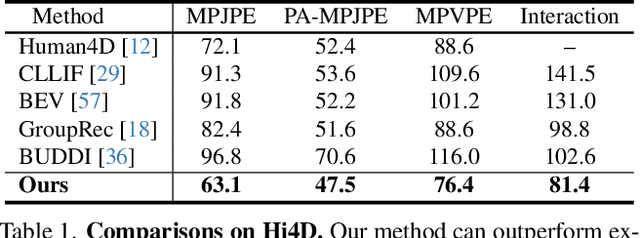
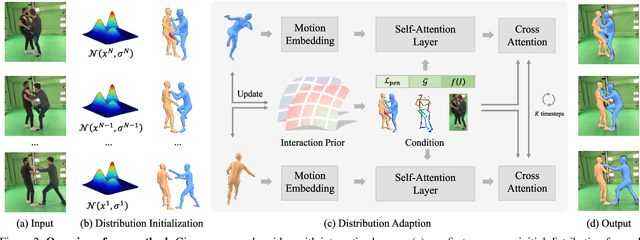
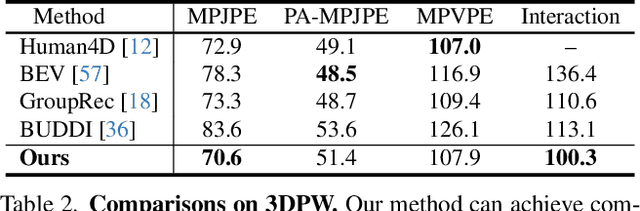
Existing multi-person human reconstruction approaches mainly focus on recovering accurate poses or avoiding penetration, but overlook the modeling of close interactions. In this work, we tackle the task of reconstructing closely interactive humans from a monocular video. The main challenge of this task comes from insufficient visual information caused by depth ambiguity and severe inter-person occlusion. In view of this, we propose to leverage knowledge from proxemic behavior and physics to compensate the lack of visual information. This is based on the observation that human interaction has specific patterns following the social proxemics. Specifically, we first design a latent representation based on Vector Quantised-Variational AutoEncoder (VQ-VAE) to model human interaction. A proxemics and physics guided diffusion model is then introduced to denoise the initial distribution. We design the diffusion model as dual branch with each branch representing one individual such that the interaction can be modeled via cross attention. With the learned priors of VQ-VAE and physical constraint as the additional information, our proposed approach is capable of estimating accurate poses that are also proxemics and physics plausible. Experimental results on Hi4D, 3DPW, and CHI3D demonstrate that our method outperforms existing approaches. The code is available at \url{https://github.com/boycehbz/HumanInteraction}.