 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperVoxelGPT: Adaptive and Ordered 3D Tokenization for Autoregressive Shape Generation
May 28, 2026Autoregressive multimodal large language models (MLLMs) enable 3D generation but struggle to scale to high-resolution shapes due to inadequate 3D tokenizations. Compact set-based representations discard deterministic spatial ordering, leading to ambiguous sequence prediction, while uniform or octree-based voxel grids preserve ordering at the cost of severe redundancy and excessively long sequences. This structural trade-off limits stable and efficient autoregressive 3D generation. We present SuperVoxelGPT, a representation-first framework that resolves this tension through adaptive and deterministically ordered supervoxel tokenization. Given a prompt, we first predict a coarse geometric saliency distribution and construct a shape-adaptive supervoxel partition using saliency-guided centroidal Voronoi tessellation, allocating fine-grained cells to complex regions and larger cells to smooth regions. Conditioned on the text and ordered supervoxel layout, we introduce a SuperVoxelVAE and fine-tune a pretrained MLLM to autoregressively generate supervoxel tokens. Experiments on Trellis-500K show that SuperVoxelGPT reduces token sequence length to 12.8% of uniform voxel tokenization while achieving state-of-the-art generation quality and an average 10$\times$ speedup over prior methods.
NeuVAS: Neural Implicit Surfaces for Variational Shape Modeling
Jun 16, 2025Neural implicit shape representation has drawn significant attention in recent years due to its smoothness, differentiability, and topological flexibility. However, directly modeling the shape of a neural implicit surface, especially as the zero-level set of a neural signed distance function (SDF), with sparse geometric control is still a challenging task. Sparse input shape control typically includes 3D curve networks or, more generally, 3D curve sketches, which are unstructured and cannot be connected to form a curve network, and therefore more difficult to deal with. While 3D curve networks or curve sketches provide intuitive shape control, their sparsity and varied topology pose challenges in generating high-quality surfaces to meet such curve constraints. In this paper, we propose NeuVAS, a variational approach to shape modeling using neural implicit surfaces constrained under sparse input shape control, including unstructured 3D curve sketches as well as connected 3D curve networks. Specifically, we introduce a smoothness term based on a functional of surface curvatures to minimize shape variation of the zero-level set surface of a neural SDF. We also develop a new technique to faithfully model G0 sharp feature curves as specified in the input curve sketches. Comprehensive comparisons with the state-of-the-art methods demonstrate the significant advantages of our method.
Facial Surgery Preview Based on the Orthognathic Treatment Prediction
Dec 15, 2024



Orthognathic surgery consultation is essential to help patients understand the changes to their facial appearance after surgery. However, current visualization methods are often inefficient and inaccurate due to limited pre- and post-treatment data and the complexity of the treatment. To overcome these challenges, this study aims to develop a fully automated pipeline that generates accurate and efficient 3D previews of postsurgical facial appearances for patients with orthognathic treatment without requiring additional medical images. The study introduces novel aesthetic losses, such as mouth-convexity and asymmetry losses, to improve the accuracy of facial surgery prediction. Additionally, it proposes a specialized parametric model for 3D reconstruction of the patient, medical-related losses to guide latent code prediction network optimization, and a data augmentation scheme to address insufficient data. The study additionally employs FLAME, a parametric model, to enhance the quality of facial appearance previews by extracting facial latent codes and establishing dense correspondences between pre- and post-surgery geometries. Quantitative comparisons showed the algorithm's effectiveness, and qualitative results highlighted accurate facial contour and detail predictions. A user study confirmed that doctors and the public could not distinguish between machine learning predictions and actual postoperative results. This study aims to offer a practical, effective solution for orthognathic surgery consultations, benefiting doctors and patients.
NESI: Shape Representation via Neural Explicit Surface Intersection
Sep 09, 2024



Compressed representations of 3D shapes that are compact, accurate, and can be processed efficiently directly in compressed form, are extremely useful for digital media applications. Recent approaches in this space focus on learned implicit or parametric representations. While implicits are well suited for tasks such as in-out queries, they lack natural 2D parameterization, complicating tasks such as texture or normal mapping. Conversely, parametric representations support the latter tasks but are ill-suited for occupancy queries. We propose a novel learned alternative to these approaches, based on intersections of localized explicit, or height-field, surfaces. Since explicits can be trivially expressed both implicitly and parametrically, NESI directly supports a wider range of processing operations than implicit alternatives, including occupancy queries and parametric access. We represent input shapes using a collection of differently oriented height-field bounded half-spaces combined using volumetric Boolean intersections. We first tightly bound each input using a pair of oppositely oriented height-fields, forming a Double Height-Field (DHF) Hull. We refine this hull by intersecting it with additional localized height-fields (HFs) that capture surface regions in its interior. We minimize the number of HFs necessary to accurately capture each input and compactly encode both the DHF hull and the local HFs as neural functions defined over subdomains of R^2. This reduced dimensionality encoding delivers high-quality compact approximations. Given similar parameter count, or storage capacity, NESI significantly reduces approximation error compared to the state of the art, especially at lower parameter counts.
Skull-to-Face: Anatomy-Guided 3D Facial Reconstruction and Editing
Mar 24, 2024Deducing the 3D face from a skull is an essential but challenging task in forensic science and archaeology. Existing methods for automated facial reconstruction yield inaccurate results, suffering from the non-determinative nature of the problem that a skull with a sparse set of tissue depth cannot fully determine the skinned face. Additionally, their texture-less results require further post-processing stages to achieve a photo-realistic appearance. This paper proposes an end-to-end 3D face reconstruction and exploration tool, providing textured 3D faces for reference. With the help of state-of-the-art text-to-image diffusion models and image-based facial reconstruction techniques, we generate an initial reference 3D face, whose biological profile aligns with the given skull. We then adapt these initial faces to meet the statistical expectations of extruded anatomical landmarks on the skull through an optimization process. The joint statistical distribution of tissue depths is learned on a small set of anatomical landmarks on the skull. To support further adjustment, we propose an efficient face adaptation tool to assist users in tuning tissue depths, either globally or at local regions, while observing plausible visual feedback. Experiments conducted on a real skull-face dataset demonstrated the effectiveness of our proposed pipeline in terms of reconstruction accuracy, diversity, and stability.
On Optimal Sampling for Learning SDF Using MLPs Equipped with Positional Encoding
Jan 02, 2024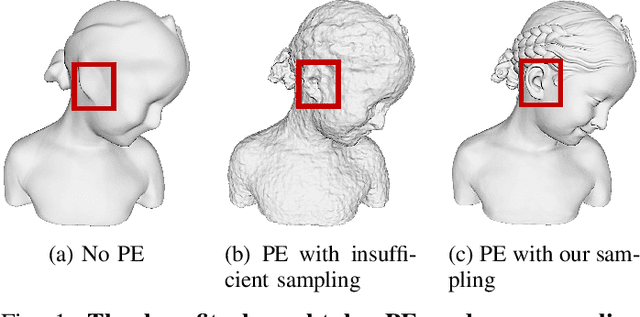
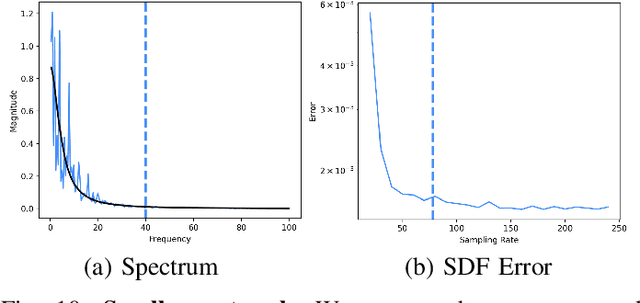
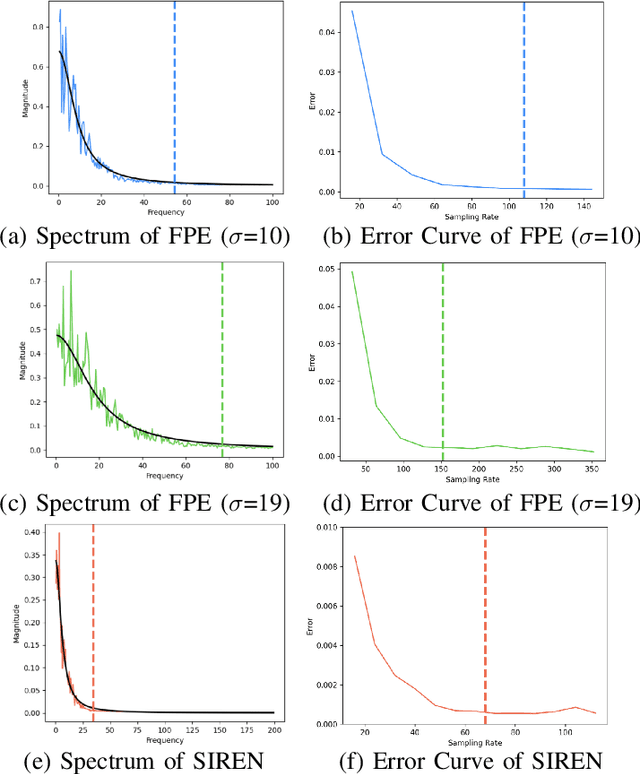
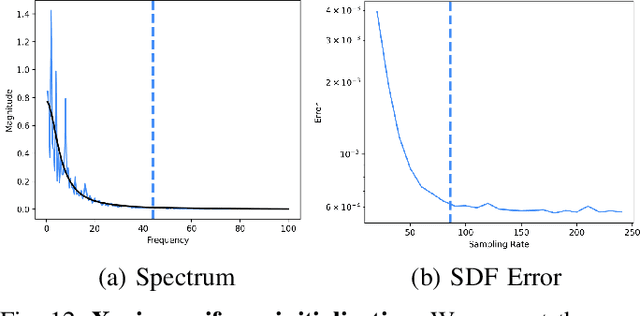
Neural implicit fields, such as the neural signed distance field (SDF) of a shape, have emerged as a powerful representation for many applications, e.g., encoding a 3D shape and performing collision detection. Typically, implicit fields are encoded by Multi-layer Perceptrons (MLP) with positional encoding (PE) to capture high-frequency geometric details. However, a notable side effect of such PE-equipped MLPs is the noisy artifacts present in the learned implicit fields. While increasing the sampling rate could in general mitigate these artifacts, in this paper we aim to explain this adverse phenomenon through the lens of Fourier analysis. We devise a tool to determine the appropriate sampling rate for learning an accurate neural implicit field without undesirable side effects. Specifically, we propose a simple yet effective method to estimate the intrinsic frequency of a given network with randomized weights based on the Fourier analysis of the network's responses. It is observed that a PE-equipped MLP has an intrinsic frequency much higher than the highest frequency component in the PE layer. Sampling against this intrinsic frequency following the Nyquist-Sannon sampling theorem allows us to determine an appropriate training sampling rate. We empirically show in the setting of SDF fitting that this recommended sampling rate is sufficient to secure accurate fitting results, while further increasing the sampling rate would not further noticeably reduce the fitting error. Training PE-equipped MLPs simply with our sampling strategy leads to performances superior to the existing methods.
An Implicit Parametric Morphable Dental Model
Nov 21, 2022



3D Morphable models of the human body capture variations among subjects and are useful in reconstruction and editing applications. Current dental models use an explicit mesh scene representation and model only the teeth, ignoring the gum. In this work, we present the first parametric 3D morphable dental model for both teeth and gum. Our model uses an implicit scene representation and is learned from rigidly aligned scans. It is based on a component-wise representation for each tooth and the gum, together with a learnable latent code for each of such components. It also learns a template shape thus enabling several applications such as segmentation, interpolation, and tooth replacement. Our reconstruction quality is on par with the most advanced global implicit representations while enabling novel applications. Project page: https://vcai.mpi-inf.mpg.de/projects/DMM/
FIRES: Fast Imaging and 3D Reconstruction of Archaeological Sherds
Nov 13, 2022Sherds, as the most common artifacts uncovered during archaeological excavations, carry rich information about past human societies so need to be accurately reconstructed and recorded digitally for analysis and preservation. Often hundreds of fragments are uncovered in a day at an archaeological excavation site, far beyond the scanning capacity of existing imaging systems. Hence, there is high demand for a desirable image acquisition system capable of imaging hundreds of fragments per day. In response to this demand, we developed a new system, dubbed FIRES, for Fast Imaging and 3D REconstruction of Sherds. The FIRES system consists of two main components. The first is an optimally designed fast image acquisition device capable of capturing over 700 sherds per day (in 8 working hours) in actual tests at an excavation site, which is one order-of-magnitude faster than existing systems. The second component is an automatic pipeline for 3D reconstruction of the sherds from the images captured by the imaging acquisition system, achieving reconstruction accuracy of 0.16 milimeters. The pipeline includes a novel batch matching algorithm that matches partial 3D scans of the front and back sides of the sherds and a new ICP-type method that registers the front and back sides sharing very narrow overlapping regions. Extensive validation in labs and testing in excavation sites demonstrated that our FIRES system provides the first fast, accurate, portal, and cost-effective solution for the task of imaging and 3D reconstruction of sherds in archaeological excavations.