 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch2Arti: Sketch-based Articulation Modeling of CAD Objects
Apr 28, 2026Articulation modeling aims to infer movable parts and their motion parameters for a 3D object, enabling interactive animation, simulation, and shape editing. In this paper, we present Sketch2Arti, the first sketch-based articulation modeling system for CAD objects. Our key observation is that designers naturally communicate articulation intent through lightweight sketches (e.g., arrows and strokes) that indicate how parts should move, yet translating such sketches into articulated 3D models remains largely manual. Sketch2Arti bridges this gap by enabling users to specify articulation through simple 2D sketches drawn from a chosen viewpoint. Given a CAD model and user sketches, our approach automatically discovers the corresponding movable parts and predicts their motion parameters, allowing iterative modeling of multiple articulations on complex objects with fine-grained control. Importantly, Sketch2Arti is trained in a category-agnostic manner without requiring object category information, leading to strong generalization to diverse objects beyond existing articulation datasets. Moreover, for shell models lacking interior structures, Sketch2Arti supports controllable internal completion guided by user sketches, generating plausible internal components consistent with the existing geometry and predicted motion constraints. Comprehensive experiments and user evaluations demonstrate the effectiveness, controllability, and generalization of Sketch2Arti. The code, dataset, and the prototype system are at https://arlo-yang.github.io/Sketch2Arti.
NeuVAS: Neural Implicit Surfaces for Variational Shape Modeling
Jun 16, 2025Neural implicit shape representation has drawn significant attention in recent years due to its smoothness, differentiability, and topological flexibility. However, directly modeling the shape of a neural implicit surface, especially as the zero-level set of a neural signed distance function (SDF), with sparse geometric control is still a challenging task. Sparse input shape control typically includes 3D curve networks or, more generally, 3D curve sketches, which are unstructured and cannot be connected to form a curve network, and therefore more difficult to deal with. While 3D curve networks or curve sketches provide intuitive shape control, their sparsity and varied topology pose challenges in generating high-quality surfaces to meet such curve constraints. In this paper, we propose NeuVAS, a variational approach to shape modeling using neural implicit surfaces constrained under sparse input shape control, including unstructured 3D curve sketches as well as connected 3D curve networks. Specifically, we introduce a smoothness term based on a functional of surface curvatures to minimize shape variation of the zero-level set surface of a neural SDF. We also develop a new technique to faithfully model G0 sharp feature curves as specified in the input curve sketches. Comprehensive comparisons with the state-of-the-art methods demonstrate the significant advantages of our method.
CMD: Controllable Multiview Diffusion for 3D Editing and Progressive Generation
May 11, 2025Recently, 3D generation methods have shown their powerful ability to automate 3D model creation. However, most 3D generation methods only rely on an input image or a text prompt to generate a 3D model, which lacks the control of each component of the generated 3D model. Any modifications of the input image lead to an entire regeneration of the 3D models. In this paper, we introduce a new method called CMD that generates a 3D model from an input image while enabling flexible local editing of each component of the 3D model. In CMD, we formulate the 3D generation as a conditional multiview diffusion model, which takes the existing or known parts as conditions and generates the edited or added components. This conditional multiview diffusion model not only allows the generation of 3D models part by part but also enables local editing of 3D models according to the local revision of the input image without changing other 3D parts. Extensive experiments are conducted to demonstrate that CMD decomposes a complex 3D generation task into multiple components, improving the generation quality. Meanwhile, CMD enables efficient and flexible local editing of a 3D model by just editing one rendered image.
DreamTexture: Shape from Virtual Texture with Analysis by Augmentation
Mar 20, 2025DreamFusion established a new paradigm for unsupervised 3D reconstruction from virtual views by combining advances in generative models and differentiable rendering. However, the underlying multi-view rendering, along with supervision from large-scale generative models, is computationally expensive and under-constrained. We propose DreamTexture, a novel Shape-from-Virtual-Texture approach that leverages monocular depth cues to reconstruct 3D objects. Our method textures an input image by aligning a virtual texture with the real depth cues in the input, exploiting the inherent understanding of monocular geometry encoded in modern diffusion models. We then reconstruct depth from the virtual texture deformation with a new conformal map optimization, which alleviates memory-intensive volumetric representations. Our experiments reveal that generative models possess an understanding of monocular shape cues, which can be extracted by augmenting and aligning texture cues -- a novel monocular reconstruction paradigm that we call Analysis by Augmentation.
NESI: Shape Representation via Neural Explicit Surface Intersection
Sep 09, 2024



Compressed representations of 3D shapes that are compact, accurate, and can be processed efficiently directly in compressed form, are extremely useful for digital media applications. Recent approaches in this space focus on learned implicit or parametric representations. While implicits are well suited for tasks such as in-out queries, they lack natural 2D parameterization, complicating tasks such as texture or normal mapping. Conversely, parametric representations support the latter tasks but are ill-suited for occupancy queries. We propose a novel learned alternative to these approaches, based on intersections of localized explicit, or height-field, surfaces. Since explicits can be trivially expressed both implicitly and parametrically, NESI directly supports a wider range of processing operations than implicit alternatives, including occupancy queries and parametric access. We represent input shapes using a collection of differently oriented height-field bounded half-spaces combined using volumetric Boolean intersections. We first tightly bound each input using a pair of oppositely oriented height-fields, forming a Double Height-Field (DHF) Hull. We refine this hull by intersecting it with additional localized height-fields (HFs) that capture surface regions in its interior. We minimize the number of HFs necessary to accurately capture each input and compactly encode both the DHF hull and the local HFs as neural functions defined over subdomains of R^2. This reduced dimensionality encoding delivers high-quality compact approximations. Given similar parameter count, or storage capacity, NESI significantly reduces approximation error compared to the state of the art, especially at lower parameter counts.
Front2Back: Single View 3D Shape Reconstruction via Front to Back Prediction
Jan 31, 2020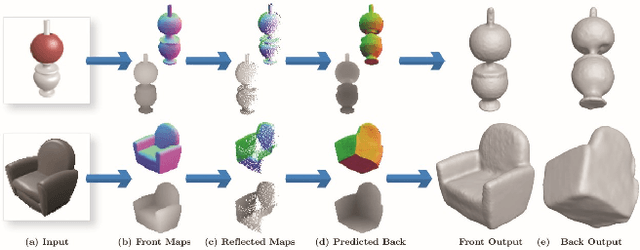



Reconstruction of a 3D shape from a single 2D image is a classical computer vision problem, whose difficulty stems from the inherent ambiguity of recovering occluded or only partially observed surfaces. Recent methods address this challenge through the use of largely unstructured neural networks that effectively distill conditional mapping and priors over 3D shape. In this work, we induce structure and geometric constraints by leveraging three core observations: (1) the surface of most everyday objects is often almost entirely exposed from pairs of typical opposite views; (2) everyday objects often exhibit global reflective symmetries which can be accurately predicted from single views; (3) opposite orthographic views of a 3D shape share consistent silhouettes. Following these observations, we first predict orthographic 2.5D visible surface maps (depth, normal and silhouette) from perspective 2D images, and detect global reflective symmetries in this data; second, we predict the back facing depth and normal maps using as input the front maps and, when available, the symmetric reflections of these maps; and finally, we reconstruct a 3D mesh from the union of these maps using a surface reconstruction method best suited for this data. Our experiments demonstrate that our framework outperforms state-of-the art approaches for 3D shape reconstructions from 2D and 2.5D data in terms of input fidelity and details preservation. Specifically, we achieve 12% better performance on average in ShapeNet benchmark dataset, and up to 19% for certain classes of objects (e.g., chairs and vessels).