 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback
Dec 26, 2025Symbolic world models (e.g., PDDL domains or executable simulators) are central to model-based planning, but training LLMs to generate such world models is limited by the lack of large-scale verifiable supervision. Current approaches rely primarily on static validation methods that fail to catch behavior-level errors arising from interactive execution. In this paper, we propose Agent2World, a tool-augmented multi-agent framework that achieves strong inference-time world-model generation and also serves as a data engine for supervised fine-tuning, by grounding generation in multi-agent feedback. Agent2World follows a three-stage pipeline: (i) A Deep Researcher agent performs knowledge synthesis by web searching to address specification gaps; (ii) A Model Developer agent implements executable world models; And (iii) a specialized Testing Team conducts adaptive unit testing and simulation-based validation. Agent2World demonstrates superior inference-time performance across three benchmarks spanning both Planning Domain Definition Language (PDDL) and executable code representations, achieving consistent state-of-the-art results. Beyond inference, Testing Team serves as an interactive environment for the Model Developer, providing behavior-aware adaptive feedback that yields multi-turn training trajectories. The model fine-tuned on these trajectories substantially improves world-model generation, yielding an average relative gain of 30.95% over the same model before training. Project page: https://agent2world.github.io.
Attributed Synthetic Data Generation for Zero-shot Domain-specific Image Classification
Apr 06, 2025Zero-shot domain-specific image classification is challenging in classifying real images without ground-truth in-domain training examples. Recent research involved knowledge from texts with a text-to-image model to generate in-domain training images in zero-shot scenarios. However, existing methods heavily rely on simple prompt strategies, limiting the diversity of synthetic training images, thus leading to inferior performance compared to real images. In this paper, we propose AttrSyn, which leverages large language models to generate attributed prompts. These prompts allow for the generation of more diverse attributed synthetic images. Experiments for zero-shot domain-specific image classification on two fine-grained datasets show that training with synthetic images generated by AttrSyn significantly outperforms CLIP's zero-shot classification under most situations and consistently surpasses simple prompt strategies.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Template Matters: Understanding the Role of Instruction Templates in Multimodal Language Model Evaluation and Training
Dec 11, 2024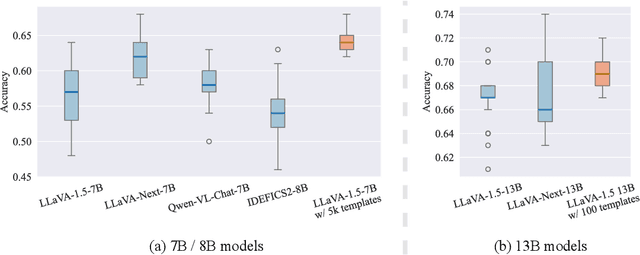
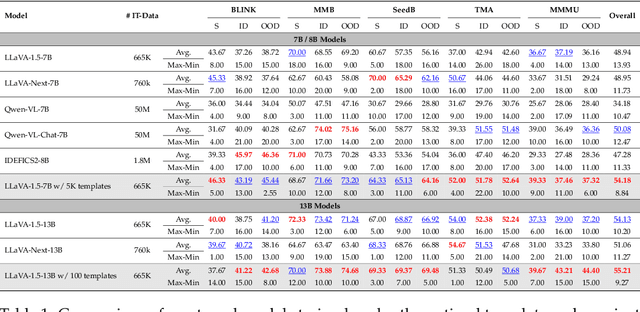

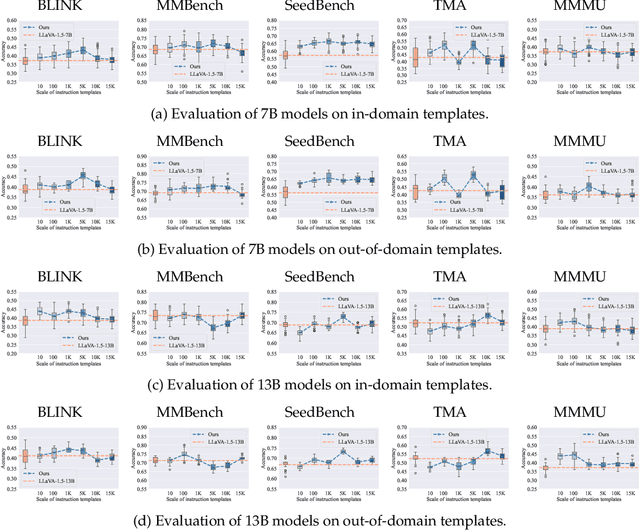
Current multimodal language models (MLMs) evaluation and training approaches overlook the influence of instruction format, presenting an elephant-in-the-room problem. Previous research deals with this problem by manually crafting instructions, failing to yield significant insights due to limitations in diversity and scalability. In this work, we propose a programmatic instruction template generator capable of producing over 39B unique template combinations by filling randomly sampled positional synonyms into weighted sampled meta templates, enabling us to comprehensively examine the MLM's performance across diverse instruction templates. Our experiments across eight common MLMs on five benchmark datasets reveal that MLMs have high template sensitivities with at most 29% performance gaps between different templates. We further augment the instruction tuning dataset of LLaVA-1.5 with our template generator and perform instruction tuning on LLaVA-1.5-7B and LLaVA-1.5-13B. Models tuned on our augmented dataset achieve the best overall performance when compared with the same scale MLMs tuned on at most 75 times the scale of our augmented dataset, highlighting the importance of instruction templates in MLM training. The code is available at https://github.com/shijian2001/TemplateMatters .
MMM: Multilingual Mutual Reinforcement Effect Mix Datasets & Test with Open-domain Information Extraction Large Language Models
Jul 15, 2024



The Mutual Reinforcement Effect (MRE) represents a promising avenue in information extraction and multitasking research. Nevertheless, its applicability has been constrained due to the exclusive availability of MRE mix datasets in Japanese, thereby limiting comprehensive exploration by the global research community. To address this limitation, we introduce a Multilingual MRE mix dataset (MMM) that encompasses 21 sub-datasets in English, Japanese, and Chinese. In this paper, we also propose a method for dataset translation assisted by Large Language Models (LLMs), which significantly reduces the manual annotation time required for dataset construction by leveraging LLMs to translate the original Japanese datasets. Additionally, we have enriched the dataset by incorporating open-domain Named Entity Recognition (NER) and sentence classification tasks. Utilizing this expanded dataset, we developed a unified input-output framework to train an Open-domain Information Extraction Large Language Model (OIELLM). The OIELLM model demonstrates the capability to effectively process novel MMM datasets, exhibiting significant improvements in performance.
Adaptive In-conversation Team Building for Language Model Agents
May 29, 2024
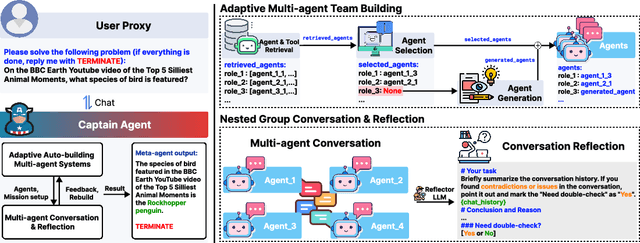

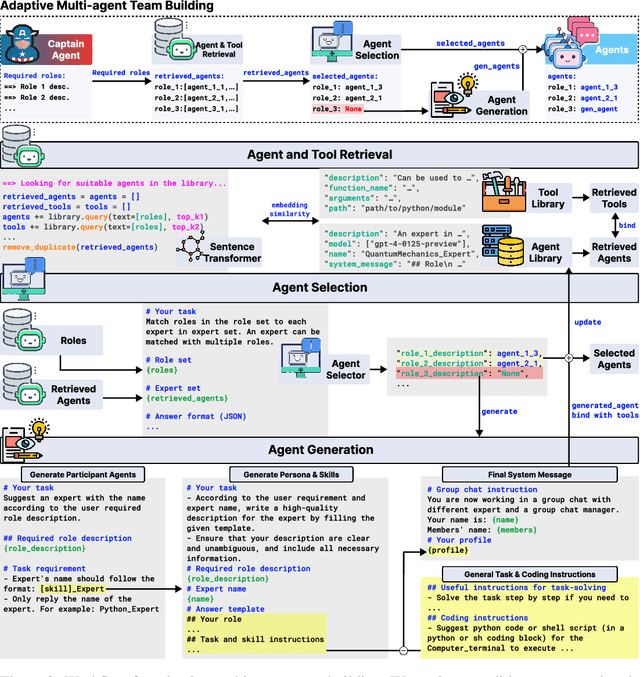
Leveraging multiple large language model (LLM) agents has shown to be a promising approach for tackling complex tasks, while the effective design of multiple agents for a particular application remains an art. It is thus intriguing to answer a critical question: Given a task, how can we build a team of LLM agents to solve it effectively? Our new adaptive team-building paradigm offers a flexible solution, realized through a novel agent design named Captain Agent. It dynamically forms and manages teams for each step of a task-solving process, utilizing nested group conversations and reflection to ensure diverse expertise and prevent stereotypical outputs. It allows for a flexible yet structured approach to problem-solving and can help reduce redundancy and enhance output diversity. A comprehensive evaluation across six real-world scenarios demonstrates that Captain Agent significantly outperforms existing multi-agent methods with 21.94% improvement in average accuracy, providing outstanding performance without requiring task-specific prompt engineering.