 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Explain Transformers by Illuminating Important Information
Paper and Code
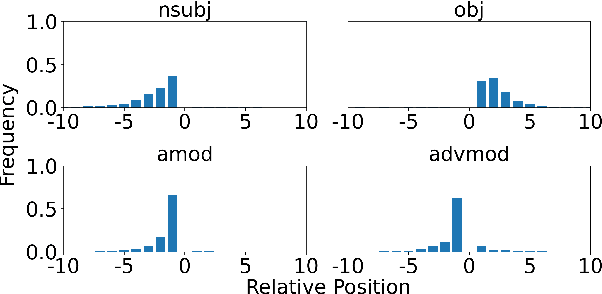
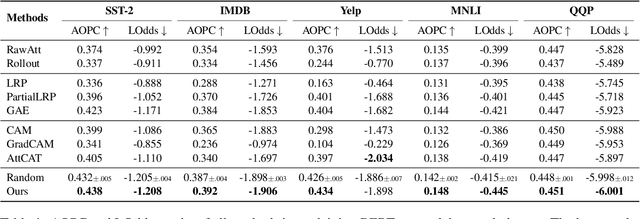
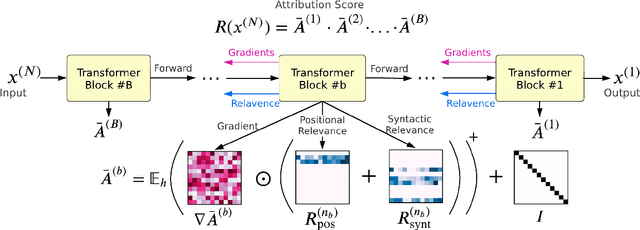
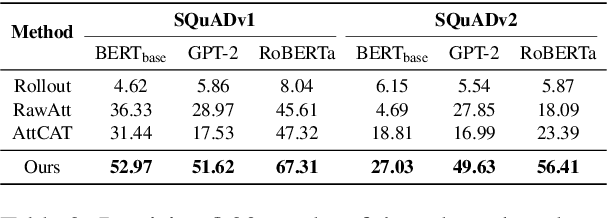
Transformer-based models excel in various natural language processing (NLP) tasks, attracting countless efforts to explain their inner workings. Prior methods explain Transformers by focusing on the raw gradient and attention as token attribution scores, where non-relevant information is often considered during explanation computation, resulting in confusing results. In this work, we propose highlighting the important information and eliminating irrelevant information by a refined information flow on top of the layer-wise relevance propagation (LRP) method. Specifically, we consider identifying syntactic and positional heads as important attention heads and focus on the relevance obtained from these important heads. Experimental results demonstrate that irrelevant information does distort output attribution scores and then should be masked during explanation computation. Compared to eight baselines on both classification and question-answering datasets, our method consistently outperforms with over 3\% to 33\% improvement on explanation metrics, providing superior explanation performance. Our anonymous code repository is available at: https://github.com/LinxinS97/Mask-LRP