 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeLoc: A Unified End-to-End Framework for Precise Timestamp Localization in Long Videos
Mar 09, 2025
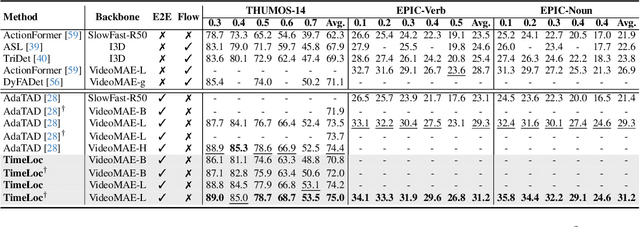
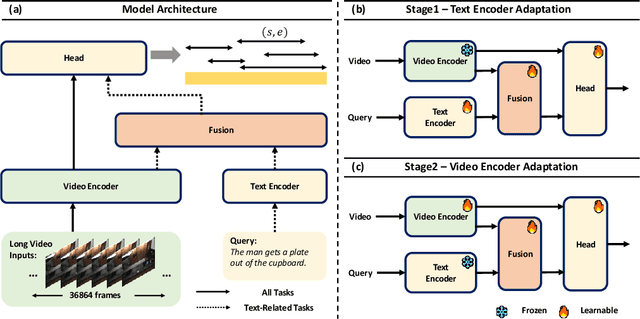
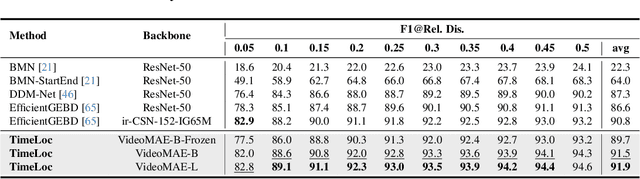
Temporal localization in untrimmed videos, which aims to identify specific timestamps, is crucial for video understanding but remains challenging. This task encompasses several subtasks, including temporal action localization, temporal video grounding, moment retrieval, and generic event boundary detection. Existing methods in each subfield are typically designed for specific tasks and lack generalizability across domains. In this paper, we propose TimeLoc, a unified end-to-end framework for timestamp localization that can handle multiple tasks. First, our approach employs a simple yet effective one-stage localization model that supports text queries as input and multiple actions as output. Second, we jointly train the video encoder and localization model in an end-to-end manner. To efficiently process long videos, we introduce temporal chunking, enabling the handling of videos with over 30k frames. Third, we find that fine-tuning pre-trained text encoders with a multi-stage training strategy further enhances text-conditioned localization. TimeLoc achieves state-of-the-art results across multiple benchmarks: +1.3% and +1.9% mAP over previous best methods on THUMOS14 and EPIC-Kitchens-100, +1.1% on Kinetics-GEBD, +2.94% mAP on QVHighlights, and significant improvements in temporal video grounding (+11.5% on TACoS and +6.7% on Charades-STA under R1@0.5). Our code and checkpoints will be released at https://github.com/sming256/TimeLoc.
Harnessing Temporal Causality for Advanced Temporal Action Detection
Jul 26, 2024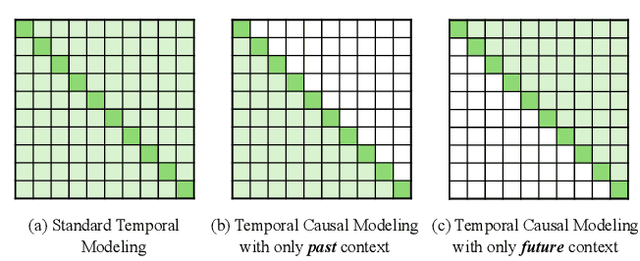

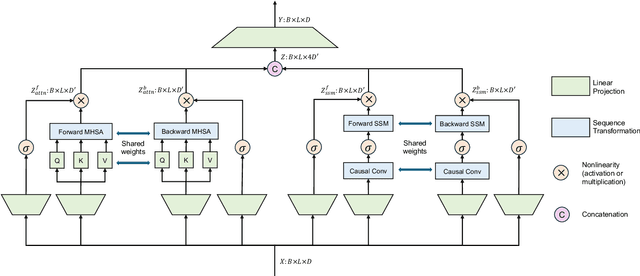

As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling for TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, we propose leveraging the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. We introduce CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. Notably, with CausalTAD, we ranked 1st in the Action Recognition, Action Detection, and Audio-Based Interaction Detection tracks at the EPIC-Kitchens Challenge 2024, as well as 1st in the Moment Queries track at the Ego4D Challenge 2024. Our code is available at https://github.com/sming256/OpenTAD/.
RecDiffusion: Rectangling for Image Stitching with Diffusion Models
Mar 28, 2024



Image stitching from different captures often results in non-rectangular boundaries, which is often considered unappealing. To solve non-rectangular boundaries, current solutions involve cropping, which discards image content, inpainting, which can introduce unrelated content, or warping, which can distort non-linear features and introduce artifacts. To overcome these issues, we introduce a novel diffusion-based learning framework, \textbf{RecDiffusion}, for image stitching rectangling. This framework combines Motion Diffusion Models (MDM) to generate motion fields, effectively transitioning from the stitched image's irregular borders to a geometrically corrected intermediary. Followed by Content Diffusion Models (CDM) for image detail refinement. Notably, our sampling process utilizes a weighted map to identify regions needing correction during each iteration of CDM. Our RecDiffusion ensures geometric accuracy and overall visual appeal, surpassing all previous methods in both quantitative and qualitative measures when evaluated on public benchmarks. Code is released at https://github.com/lhaippp/RecDiffusion.
End-to-End Temporal Action Detection with 1B Parameters Across 1000 Frames
Nov 28, 2023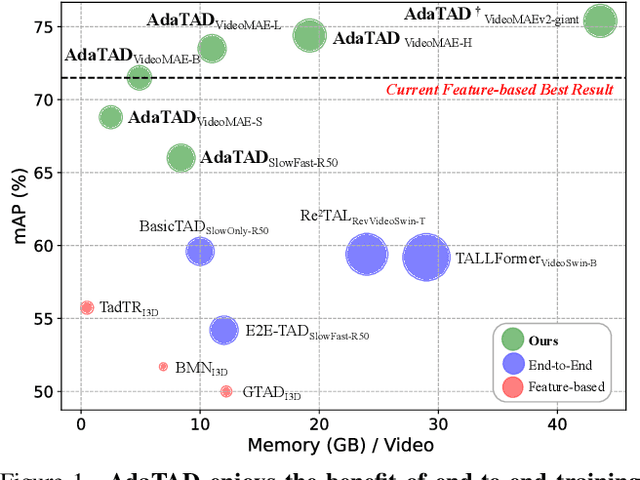



Recently, temporal action detection (TAD) has seen significant performance improvement with end-to-end training. However, due to the memory bottleneck, only models with limited scales and limited data volumes can afford end-to-end training, which inevitably restricts TAD performance. In this paper, we reduce the memory consumption for end-to-end training, and manage to scale up the TAD backbone to 1 billion parameters and the input video to 1,536 frames, leading to significant detection performance. The key to our approach lies in our proposed temporal-informative adapter (TIA), which is a novel lightweight module that reduces training memory. Using TIA, we free the humongous backbone from learning to adapt to the TAD task by only updating the parameters in TIA. TIA also leads to better TAD representation by temporally aggregating context from adjacent frames throughout the backbone. We evaluate our model across four representative datasets. Owing to our efficient design, we are able to train end-to-end on VideoMAEv2-giant and achieve 75.4% mAP on THUMOS14, being the first end-to-end model to outperform the best feature-based methods.
Minimum Efforts to Build an End-to-End Spatial-Temporal Action Detector
Jun 07, 2022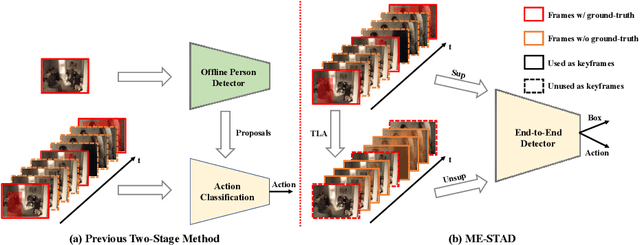
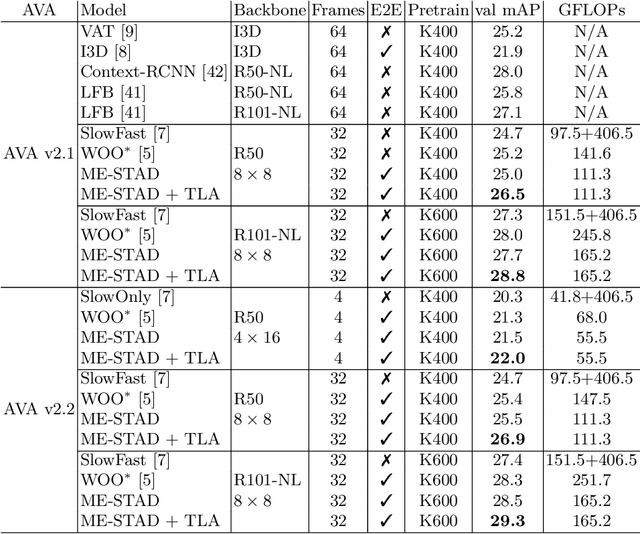
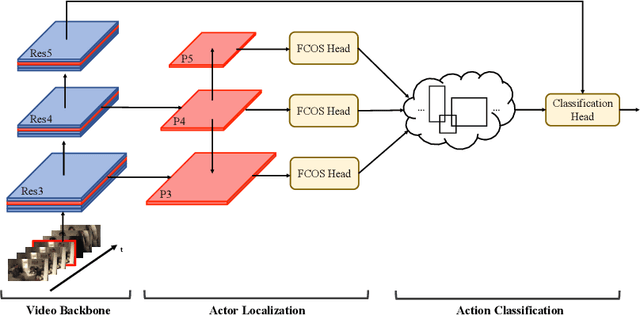
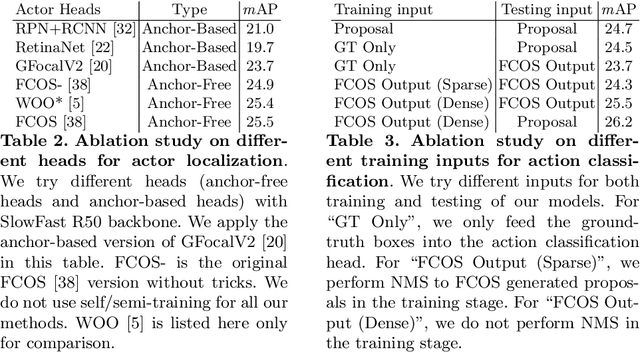
Spatial-temporal action detection is a vital part of video understanding. Current spatial-temporal action detection methods will first use an object detector to obtain person candidate proposals. Then, the model will classify the person candidates into different action categories. So-called two-stage methods are heavy and hard to apply in real-world applications. Some existing methods use a unified model structure, But they perform badly with the vanilla model and often need extra modules to boost the performance. In this paper, we explore the strategy to build an end-to-end spatial-temporal action detector with minimal modifications. To this end, we propose a new method named ME-STAD, which solves the spatial-temporal action detection problem in an end-to-end manner. Besides the model design, we propose a novel labeling strategy to deal with sparse annotations in spatial-temporal datasets. The proposed ME-STAD achieves better results (2.2% mAP boost) than original two-stage detectors and around 80% FLOPs reduction. Moreover, our proposed ME-STAD only has minimum modifications with previous methods and does not require extra components. Our code will be made public.
Weakly Supervised Foreground Learning for Weakly Supervised Localization and Detection
Aug 03, 2021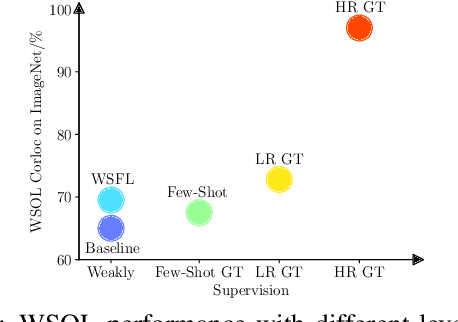

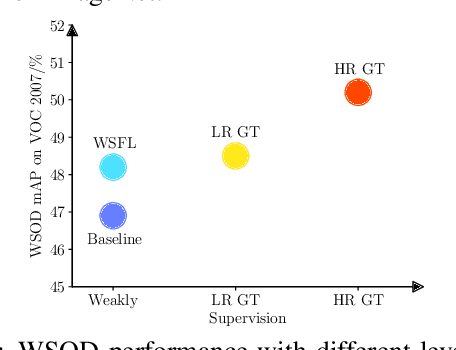
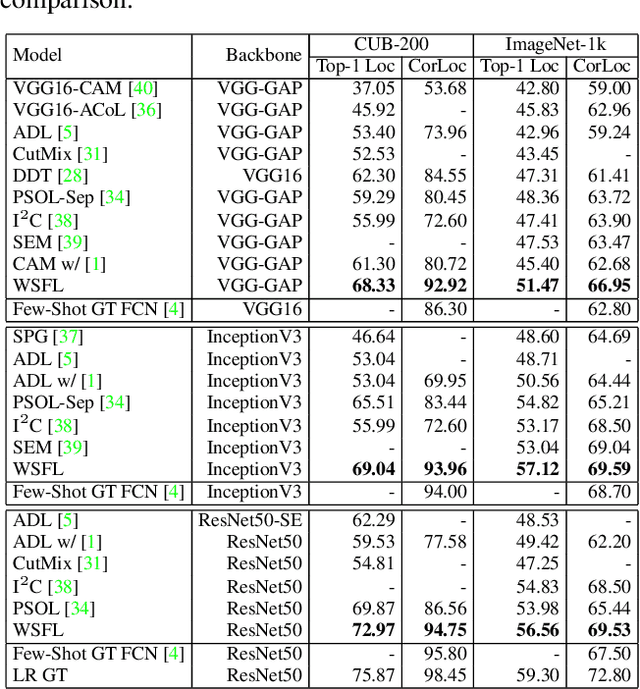
Modern deep learning models require large amounts of accurately annotated data, which is often difficult to satisfy. Hence, weakly supervised tasks, including weakly supervised object localization~(WSOL) and detection~(WSOD), have recently received attention in the computer vision community. In this paper, we motivate and propose the weakly supervised foreground learning (WSFL) task by showing that both WSOL and WSOD can be greatly improved if groundtruth foreground masks are available. More importantly, we propose a complete WSFL pipeline with low computational cost, which generates pseudo boxes, learns foreground masks, and does not need any localization annotations. With the help of foreground masks predicted by our WSFL model, we achieve 72.97% correct localization accuracy on CUB for WSOL, and 55.7% mean average precision on VOC07 for WSOD, thereby establish new state-of-the-art for both tasks. Our WSFL model also shows excellent transfer ability.
Salvage of Supervision in Weakly Supervised Detection
Jun 08, 2021
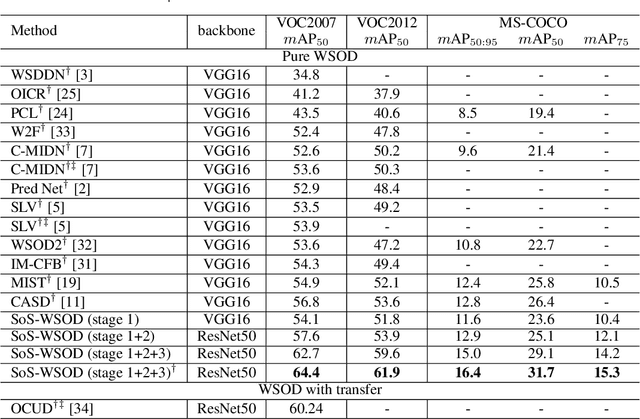


Weakly supervised object detection (WSOD) has recently attracted much attention. However, the method, performance and speed gaps between WSOD and fully supervised detection prevent WSOD from being applied in real-world tasks. To bridge the gaps, this paper proposes a new framework, Salvage of Supervision (SoS), with the key idea being to harness every potentially useful supervisory signal in WSOD: the weak image-level labels, the pseudo-labels, and the power of semi-supervised object detection. This paper shows that each type of supervisory signal brings in notable improvements, outperforms existing WSOD methods (which mainly use only the weak labels) by large margins. The proposed SoS-WSOD method achieves 64.4 $m\text{AP}_{50}$ on VOC2007, 61.9 $m\text{AP}_{50}$ on VOC2012 and 16.4 $m\text{AP}_{50:95}$ on MS-COCO, and also has fast inference speed. Ablations and visualization further verify the effectiveness of SoS.
Rethinking the Route Towards Weakly Supervised Object Localization
Mar 03, 2020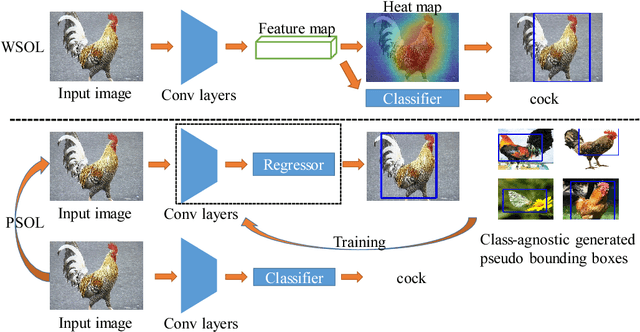
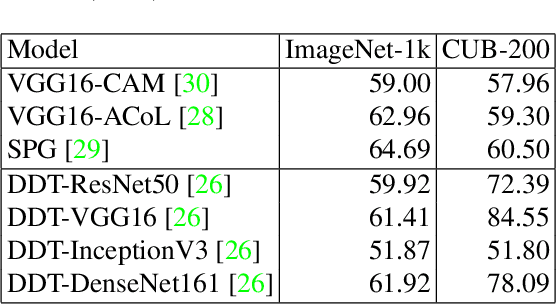
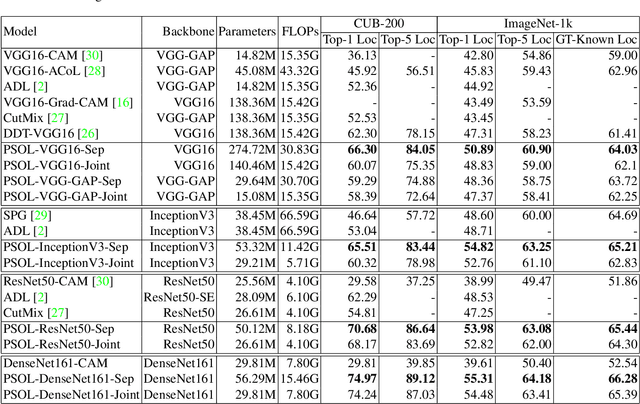

Weakly supervised object localization (WSOL) aims to localize objects with only image-level labels. Previous methods often try to utilize feature maps and classification weights to localize objects using image level annotations indirectly. In this paper, we demonstrate that weakly supervised object localization should be divided into two parts: class-agnostic object localization and object classification. For class-agnostic object localization, we should use class-agnostic methods to generate noisy pseudo annotations and then perform bounding box regression on them without class labels. We propose the pseudo supervised object localization (PSOL) method as a new way to solve WSOL. Our PSOL models have good transferability across different datasets without fine-tuning. With generated pseudo bounding boxes, we achieve 58.00% localization accuracy on ImageNet and 74.97% localization accuracy on CUB-200, which have a large edge over previous models.
Towards Real-Time Action Recognition on Mobile Devices Using Deep Models
Jun 17, 2019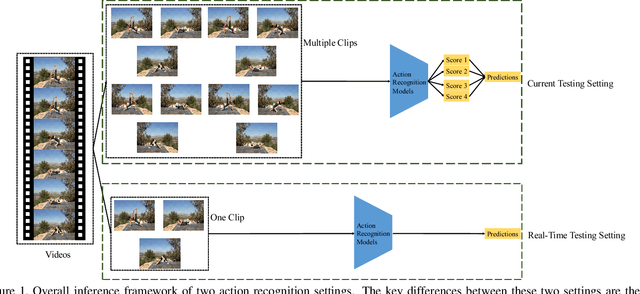
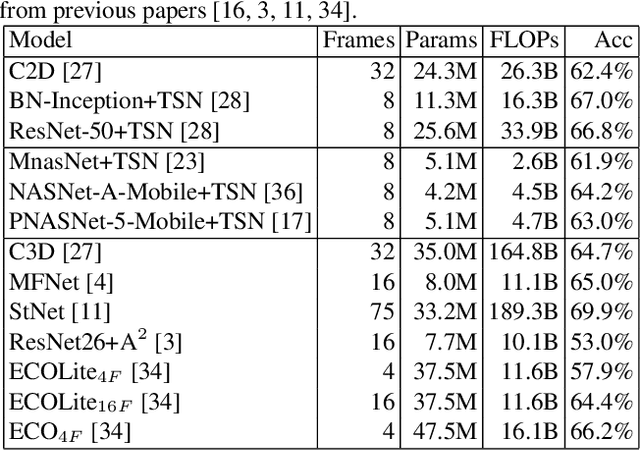
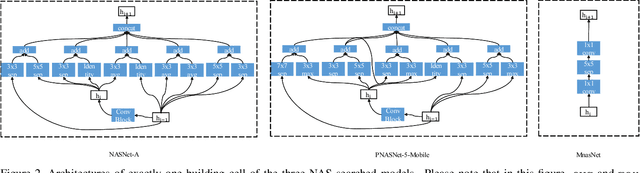
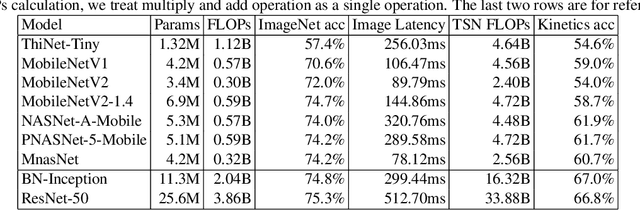
Action recognition is a vital task in computer vision, and many methods are developed to push it to the limit. However, current action recognition models have huge computational costs, which cannot be deployed to real-world tasks on mobile devices. In this paper, we first illustrate the setting of real-time action recognition, which is different from current action recognition inference settings. Under the new inference setting, we investigate state-of-the-art action recognition models on the Kinetics dataset empirically. Our results show that designing efficient real-time action recognition models is different from designing efficient ImageNet models, especially in weight initialization. We show that pre-trained weights on ImageNet improve the accuracy under the real-time action recognition setting. Finally, we use the hand gesture recognition task as a case study to evaluate our compact real-time action recognition models in real-world applications on mobile phones. Results show that our action recognition models, being 6x faster and with similar accuracy as state-of-the-art, can roughly meet the real-time requirements on mobile devices. To our best knowledge, this is the first paper that deploys current deep learning action recognition models on mobile devices.
Coarse-to-fine: A RNN-based hierarchical attention model for vehicle re-identification
Dec 11, 2018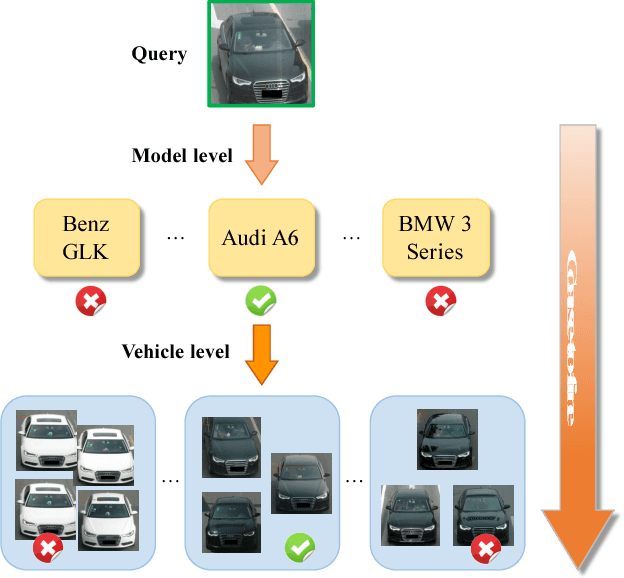
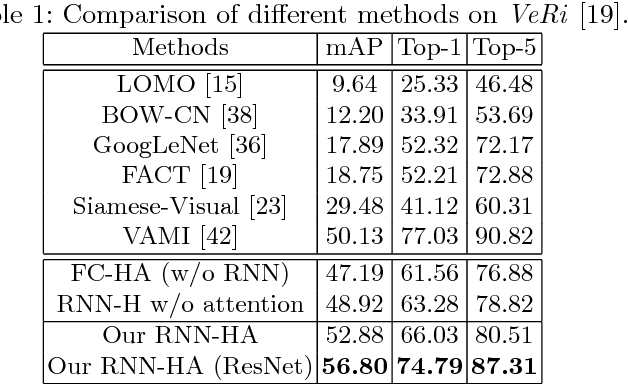
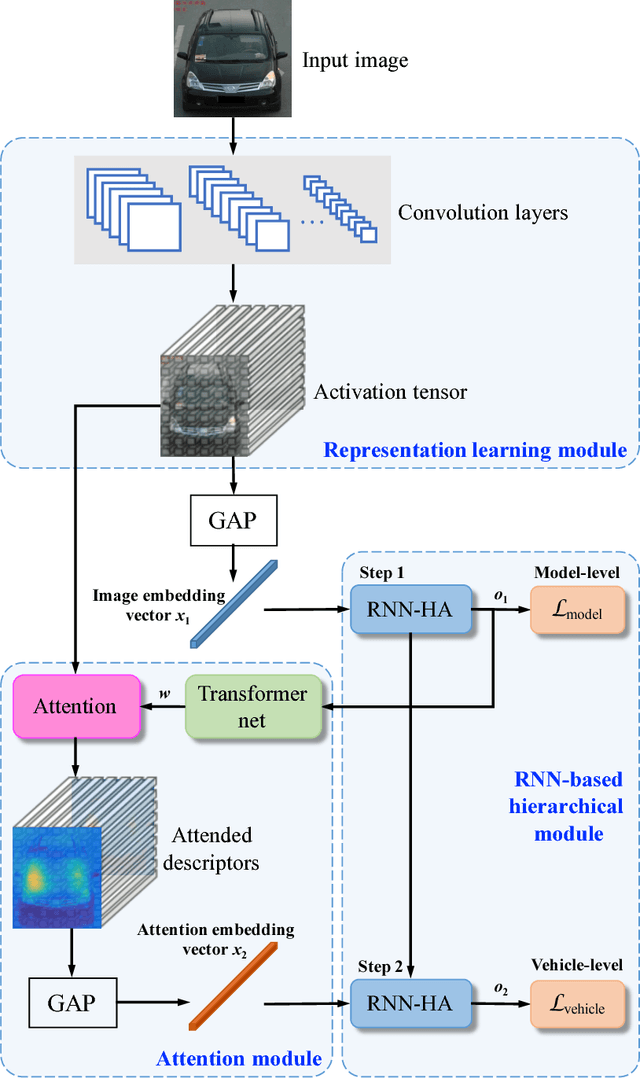
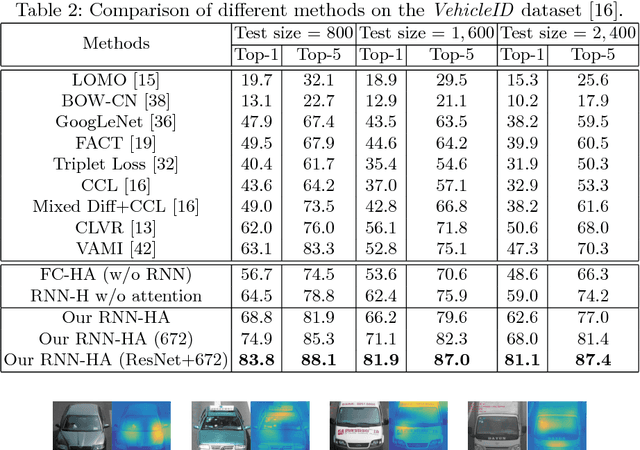
Vehicle re-identification is an important problem and becomes desirable with the rapid expansion of applications in video surveillance and intelligent transportation. By recalling the identification process of human vision, we are aware that there exists a native hierarchical dependency when humans identify different vehicles. Specifically, humans always firstly determine one vehicle's coarse-grained category, i.e., the car model/type. Then, under the branch of the predicted car model/type, they are going to identify specific vehicles by relying on subtle visual cues, e.g., customized paintings and windshield stickers, at the fine-grained level. Inspired by the coarse-to-fine hierarchical process, we propose an end-to-end RNN-based Hierarchical Attention (RNN-HA) classification model for vehicle re-identification. RNN-HA consists of three mutually coupled modules: the first module generates image representations for vehicle images, the second hierarchical module models the aforementioned hierarchical dependent relationship, and the last attention module focuses on capturing the subtle visual information distinguishing specific vehicles from each other. By conducting comprehensive experiments on two vehicle re-identification benchmark datasets VeRi and VehicleID, we demonstrate that the proposed model achieves superior performance over state-of-the-art methods.