 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Expectation of Label Distribution for Facial Age and Attractiveness Estimation
Jul 03, 2020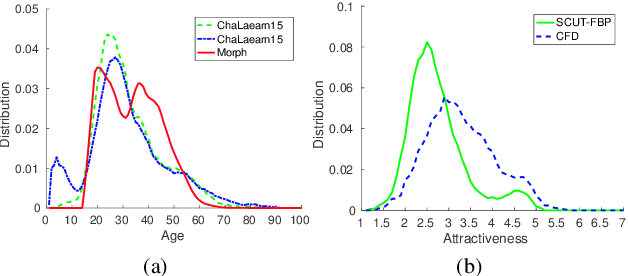
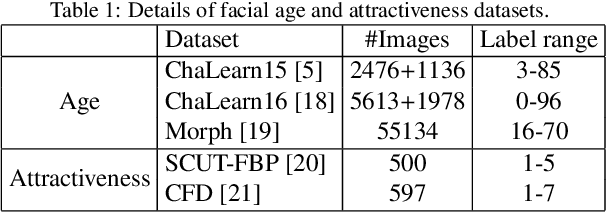
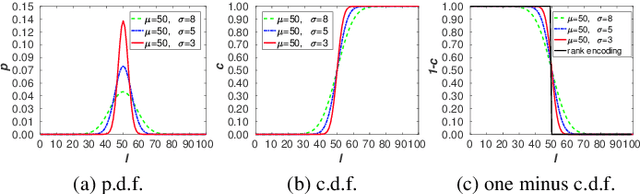
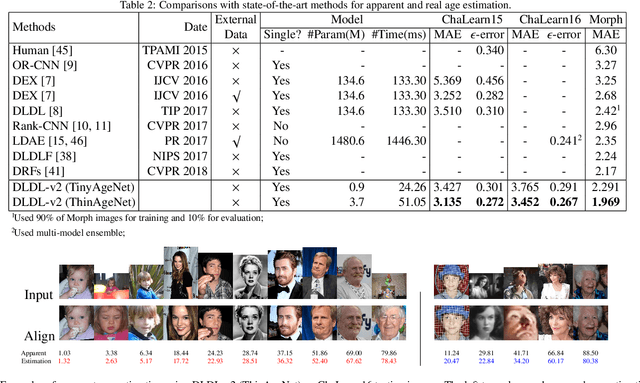
Facial attributes (e.g., age and attractiveness) estimation performance has been greatly improved by using convolutional neural networks. However, existing methods have an inconsistency between the training objectives and the evaluation metric, so they may be suboptimal. In addition, these methods always adopt image classification or face recognition models with a large amount of parameters, which carry expensive computation cost and storage overhead. In this paper, we firstly analyze the essential relationship between two state-of-the-art methods (Ranking-CNN and DLDL) and show that the Ranking method is in fact learning label distribution implicitly. This result thus firstly unifies two existing popular state-of-the-art methods into the DLDL framework. Second, in order to alleviate the inconsistency and reduce resource consumption, we design a lightweight network architecture and propose a unified framework which can jointly learn facial attribute distribution and regress attribute value. The effectiveness of our approach has been demonstrated on both facial age and attractiveness estimation tasks. Our method achieves new state-of-the-art results using the single model with 36$\times$(6$\times$) fewer parameters and 2.6$\times$(2.1$\times$) faster inference speed on facial age (attractiveness) estimation. Moreover, our method can achieve comparable results as the state-of-the-art even though the number of parameters is further reduced to 0.9M (3.8MB disk storage).
Towards Real-Time Action Recognition on Mobile Devices Using Deep Models
Jun 17, 2019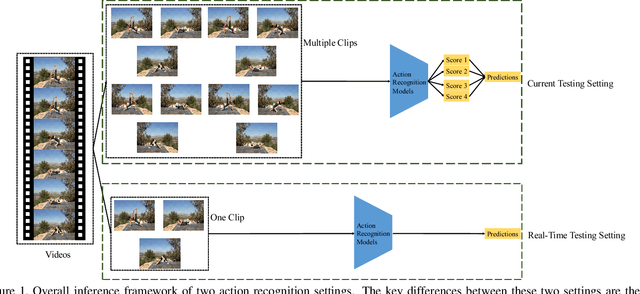
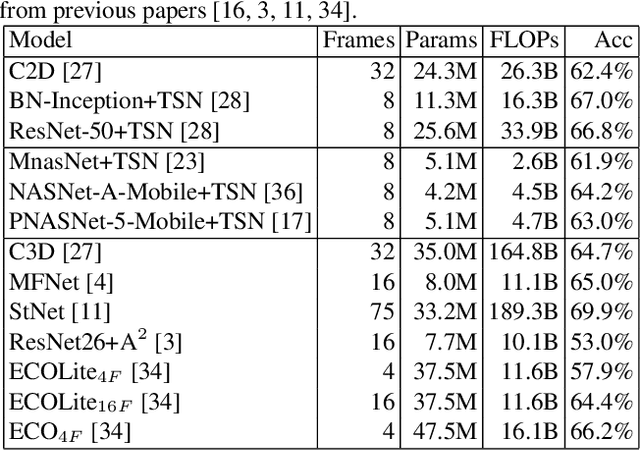
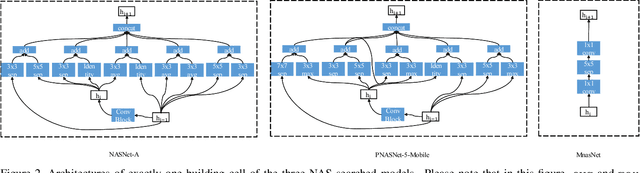
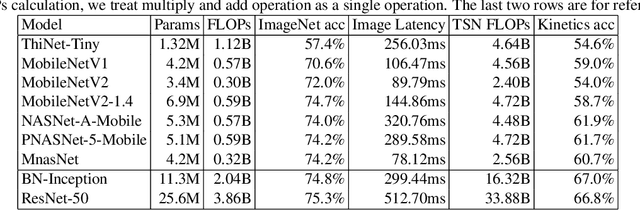
Action recognition is a vital task in computer vision, and many methods are developed to push it to the limit. However, current action recognition models have huge computational costs, which cannot be deployed to real-world tasks on mobile devices. In this paper, we first illustrate the setting of real-time action recognition, which is different from current action recognition inference settings. Under the new inference setting, we investigate state-of-the-art action recognition models on the Kinetics dataset empirically. Our results show that designing efficient real-time action recognition models is different from designing efficient ImageNet models, especially in weight initialization. We show that pre-trained weights on ImageNet improve the accuracy under the real-time action recognition setting. Finally, we use the hand gesture recognition task as a case study to evaluate our compact real-time action recognition models in real-world applications on mobile phones. Results show that our action recognition models, being 6x faster and with similar accuracy as state-of-the-art, can roughly meet the real-time requirements on mobile devices. To our best knowledge, this is the first paper that deploys current deep learning action recognition models on mobile devices.