 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster, Cheaper, More Accurate: Specialised Knowledge Tracing Models Outperform LLMs
Mar 03, 2026Predicting future student responses to questions is particularly valuable for educational learning platforms where it enables effective interventions. One of the key approaches to do this has been through the use of knowledge tracing (KT) models. These are small, domain-specific, temporal models trained on student question-response data. KT models are optimised for high accuracy on specific educational domains and have fast inference and scalable deployments. The rise of Large Language Models (LLMs) motivates us to ask the following questions: (1) How well can LLMs perform at predicting students' future responses to questions? (2) Are LLMs scalable for this domain? (3) How do LLMs compare to KT models on this domain-specific task? In this paper, we compare multiple LLMs and KT models across predictive performance, deployment cost, and inference speed to answer the above questions. We show that KT models outperform LLMs with respect to accuracy and F1 scores on this domain-specific task. Further, we demonstrate that LLMs are orders of magnitude slower than KT models and cost orders of magnitude more to deploy. This highlights the importance of domain-specific models for education prediction tasks and the fact that current closed source LLMs should not be used as a universal solution for all tasks.
Misconception Diagnosis From Student-Tutor Dialogue: Generate, Retrieve, Rerank
Feb 02, 2026Timely and accurate identification of student misconceptions is key to improving learning outcomes and pre-empting the compounding of student errors. However, this task is highly dependent on the effort and intuition of the teacher. In this work, we present a novel approach for detecting misconceptions from student-tutor dialogues using large language models (LLMs). First, we use a fine-tuned LLM to generate plausible misconceptions, and then retrieve the most promising candidates among these using embedding similarity with the input dialogue. These candidates are then assessed and re-ranked by another fine-tuned LLM to improve misconception relevance. Empirically, we evaluate our system on real dialogues from an educational tutoring platform. We consider multiple base LLM models including LLaMA, Qwen and Claude on zero-shot and fine-tuned settings. We find that our approach improves predictive performance over baseline models and that fine-tuning improves both generated misconception quality and can outperform larger closed-source models. Finally, we conduct ablation studies to both validate the importance of our generation and reranking steps on misconception generation quality.
Helios 2.0: A Robust, Ultra-Low Power Gesture Recognition System Optimised for Event-Sensor based Wearables
Mar 10, 2025


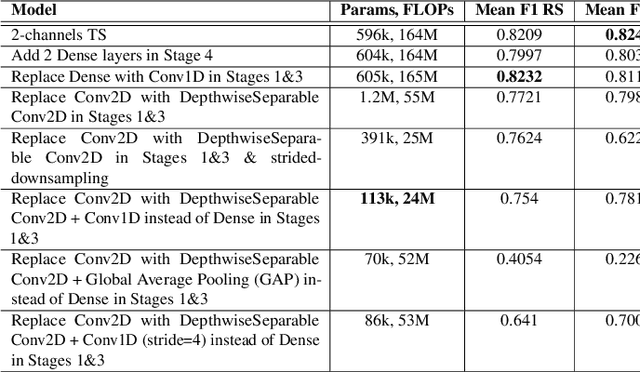
We present an advance in wearable technology: a mobile-optimized, real-time, ultra-low-power event camera system that enables natural hand gesture control for smart glasses, dramatically improving user experience. While hand gesture recognition in computer vision has advanced significantly, critical challenges remain in creating systems that are intuitive, adaptable across diverse users and environments, and energy-efficient enough for practical wearable applications. Our approach tackles these challenges through carefully selected microgestures: lateral thumb swipes across the index finger (in both directions) and a double pinch between thumb and index fingertips. These human-centered interactions leverage natural hand movements, ensuring intuitive usability without requiring users to learn complex command sequences. To overcome variability in users and environments, we developed a novel simulation methodology that enables comprehensive domain sampling without extensive real-world data collection. Our power-optimised architecture maintains exceptional performance, achieving F1 scores above 80\% on benchmark datasets featuring diverse users and environments. The resulting models operate at just 6-8 mW when exploiting the Qualcomm Snapdragon Hexagon DSP, with our 2-channel implementation exceeding 70\% F1 accuracy and our 6-channel model surpassing 80\% F1 accuracy across all gesture classes in user studies. These results were achieved using only synthetic training data. This improves on the state-of-the-art for F1 accuracy by 20\% with a power reduction 25x when using DSP. This advancement brings deploying ultra-low-power vision systems in wearable devices closer and opens new possibilities for seamless human-computer interaction.
Helios: An extremely low power event-based gesture recognition for always-on smart eyewear
Jul 11, 2024



This paper introduces Helios, the first extremely low-power, real-time, event-based hand gesture recognition system designed for all-day on smart eyewear. As augmented reality (AR) evolves, current smart glasses like the Meta Ray-Bans prioritize visual and wearable comfort at the expense of functionality. Existing human-machine interfaces (HMIs) in these devices, such as capacitive touch and voice controls, present limitations in ergonomics, privacy and power consumption. Helios addresses these challenges by leveraging natural hand interactions for a more intuitive and comfortable user experience. Our system utilizes a extremely low-power and compact 3mmx4mm/20mW event camera to perform natural hand-based gesture recognition for always-on smart eyewear. The camera's output is processed by a convolutional neural network (CNN) running on a NXP Nano UltraLite compute platform, consuming less than 350mW. Helios can recognize seven classes of gestures, including subtle microgestures like swipes and pinches, with 91% accuracy. We also demonstrate real-time performance across 20 users at a remarkably low latency of 60ms. Our user testing results align with the positive feedback we received during our recent successful demo at AWE-USA-2024.
Bessel Equivariant Networks for Inversion of Transmission Effects in Multi-Mode Optical Fibres
Jul 26, 2022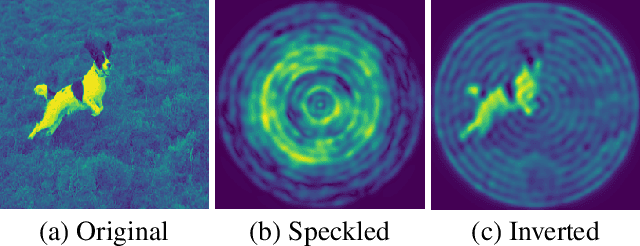
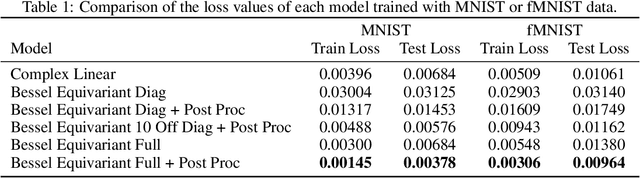


We develop a new type of model for solving the task of inverting the transmission effects of multi-mode optical fibres through the construction of an $\mathrm{SO}^{+}(2,1)$-equivariant neural network. This model takes advantage of the of the azimuthal correlations known to exist in fibre speckle patterns and naturally accounts for the difference in spatial arrangement between input and speckle patterns. In addition, we use a second post-processing network to remove circular artifacts, fill gaps, and sharpen the images, which is required due to the nature of optical fibre transmission. This two stage approach allows for the inspection of the predicted images produced by the more robust physically motivated equivariant model, which could be useful in a safety-critical application, or by the output of both models, which produces high quality images. Further, this model can scale to previously unachievable resolutions of imaging with multi-mode optical fibres and is demonstrated on $256 \times 256$ pixel images. This is a result of improving the trainable parameter requirement from $\mathcal{O}(N^4)$ to $\mathcal{O}(m)$, where $N$ is pixel size and $m$ is number of fibre modes. Finally, this model generalises to new images, outside of the set of training data classes, better than previous models.
Rotation Equivariant 3D Hand Mesh Generation from a Single RGB Image
Nov 25, 2021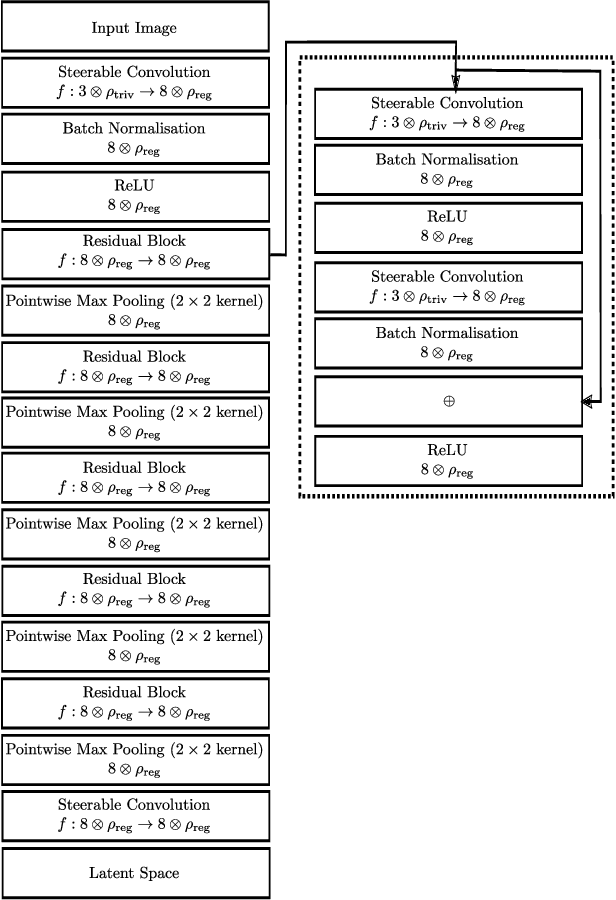
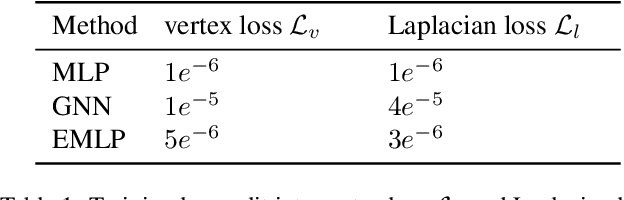
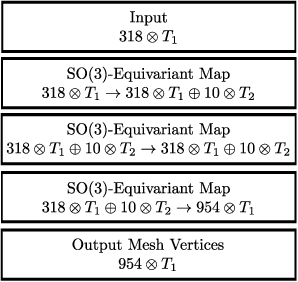
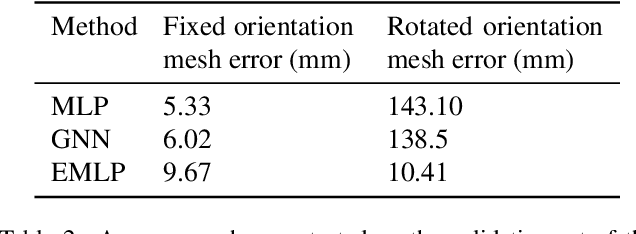
We develop a rotation equivariant model for generating 3D hand meshes from 2D RGB images. This guarantees that as the input image of a hand is rotated the generated mesh undergoes a corresponding rotation. Furthermore, this removes undesirable deformations in the meshes often generated by methods without rotation equivariance. By building a rotation equivariant model, through considering symmetries in the problem, we reduce the need for training on very large datasets to achieve good mesh reconstruction. The encoder takes images defined on $\mathbb{Z}^{2}$ and maps these to latent functions defined on the group $C_{8}$. We introduce a novel vector mapping function to map the function defined on $C_{8}$ to a latent point cloud space defined on the group $\mathrm{SO}(2)$. Further, we introduce a 3D projection function that learns a 3D function from the $\mathrm{SO}(2)$ latent space. Finally, we use an $\mathrm{SO}(3)$ equivariant decoder to ensure rotation equivariance. Our rotation equivariant model outperforms state-of-the-art methods on a real-world dataset and we demonstrate that it accurately captures the shape and pose in the generated meshes under rotation of the input hand.
Local Permutation Equivariance For Graph Neural Networks
Nov 23, 2021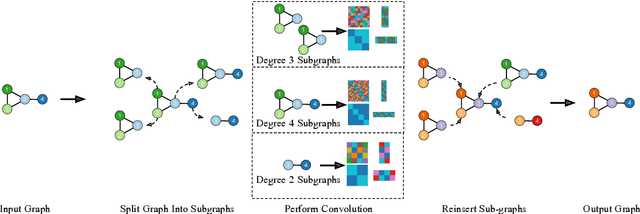
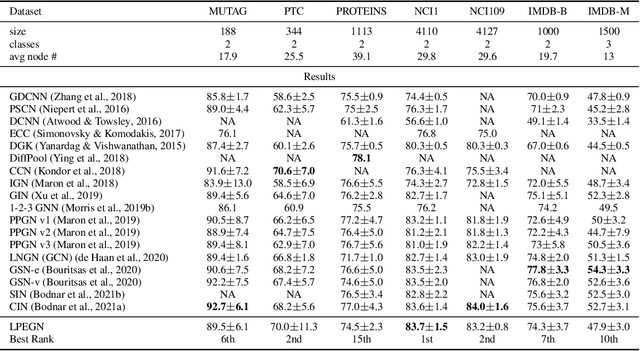

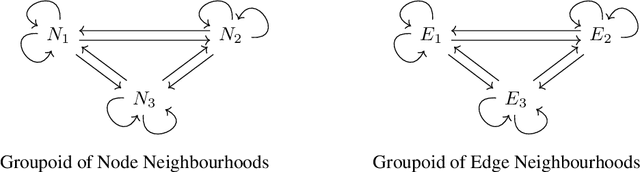
In this work we develop a new method, named locally permutation-equivariant graph neural networks, which provides a framework for building graph neural networks that operate on local node neighbourhoods, through sub-graphs, while using permutation equivariant update functions. Message passing neural networks have been shown to be limited in their expressive power and recent approaches to over come this either lack scalability or require structural information to be encoded into the feature space. The general framework presented here overcomes the scalability issues associated with global permutation equivariance by operating on sub-graphs through restricted representations. In addition, we prove that there is no loss of expressivity by using restricted representations. Furthermore, the proposed framework only requires a choice of $k$-hops for creating sub-graphs and a choice of representation space to be used for each layer, which makes the method easily applicable across a range of graph based domains. We experimentally validate the method on a range of graph benchmark classification tasks, demonstrating either state-of-the-art results or very competitive results on all benchmarks. Further, we demonstrate that the use of local update functions offers a significant improvement in GPU memory over global methods.
CpT: Convolutional Point Transformer for 3D Point Cloud Processing
Nov 21, 2021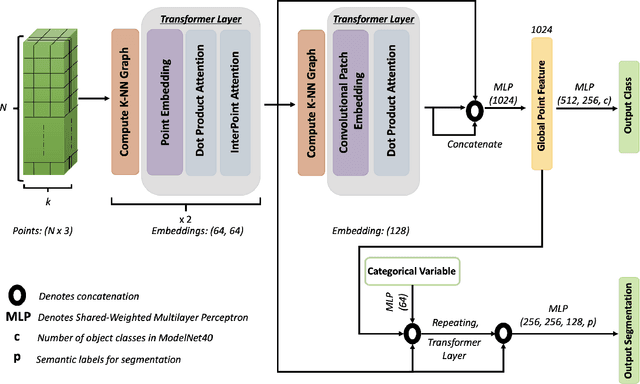
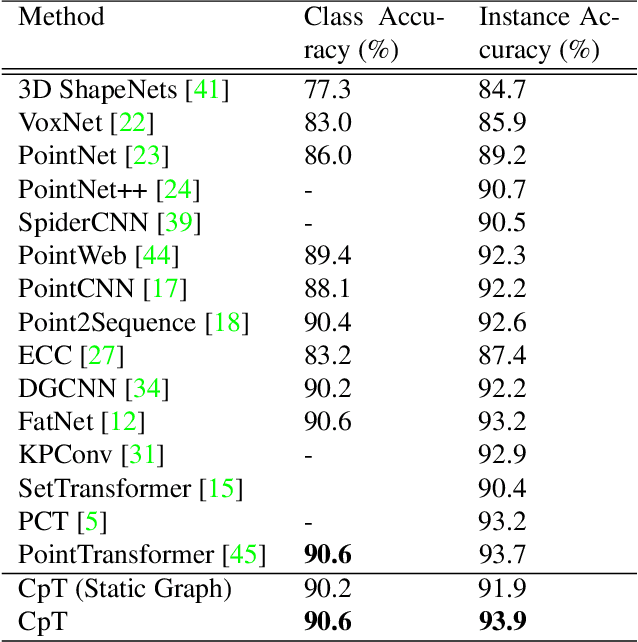
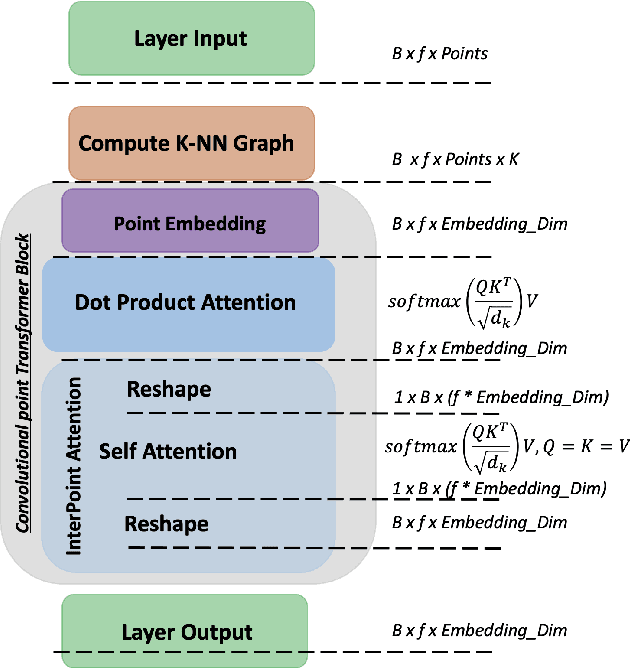

We present CpT: Convolutional point Transformer - a novel deep learning architecture for dealing with the unstructured nature of 3D point cloud data. CpT is an improvement over existing attention-based Convolutions Neural Networks as well as previous 3D point cloud processing transformers. It achieves this feat due to its effectiveness in creating a novel and robust attention-based point set embedding through a convolutional projection layer crafted for processing dynamically local point set neighbourhoods. The resultant point set embedding is robust to the permutations of the input points. Our novel CpT block builds over local neighbourhoods of points obtained via a dynamic graph computation at each layer of the networks' structure. It is fully differentiable and can be stacked just like convolutional layers to learn global properties of the points. We evaluate our model on standard benchmark datasets such as ModelNet40, ShapeNet Part Segmentation, and the S3DIS 3D indoor scene semantic segmentation dataset to show that our model can serve as an effective backbone for various point cloud processing tasks when compared to the existing state-of-the-art approaches.
Rotation Equivariant Deforestation Segmentation and Driver Classification
Oct 25, 2021


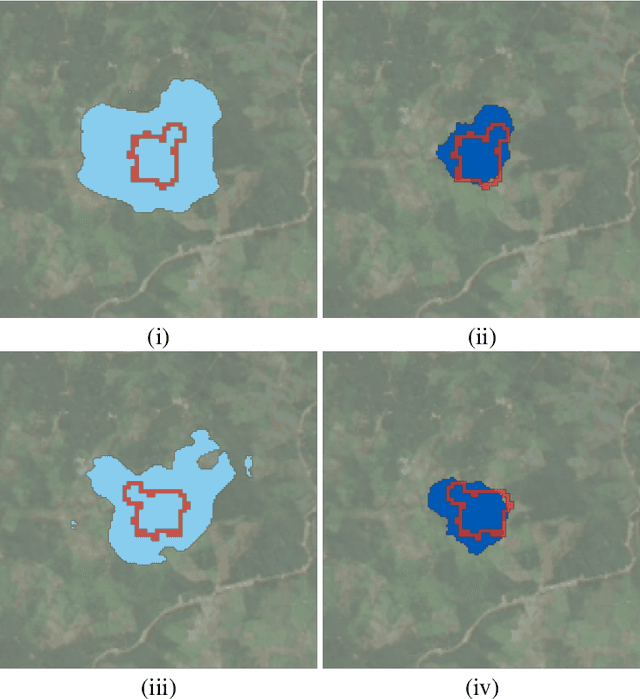
Deforestation has become a significant contributing factor to climate change and, due to this, both classifying the drivers and predicting segmentation maps of deforestation has attracted significant interest. In this work, we develop a rotation equivariant convolutional neural network model to predict the drivers and generate segmentation maps of deforestation events from Landsat 8 satellite images. This outperforms previous methods in classifying the drivers and predicting the segmentation map of deforestation, offering a 9% improvement in classification accuracy and a 7% improvement in segmentation map accuracy. In addition, this method predicts stable segmentation maps under rotation of the input image, which ensures that predicted regions of deforestation are not dependent upon the rotational orientation of the satellite.
A Graph VAE and Graph Transformer Approach to Generating Molecular Graphs
Apr 09, 2021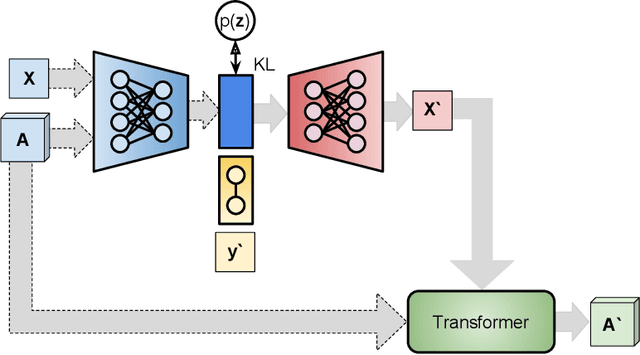
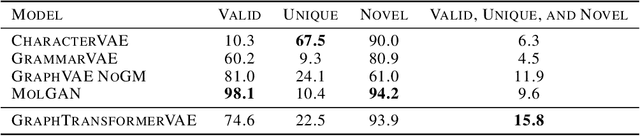
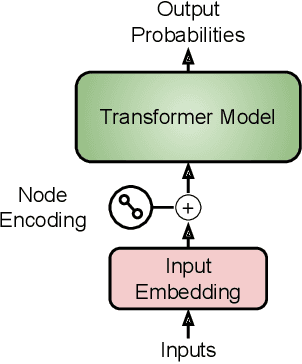

We propose a combination of a variational autoencoder and a transformer based model which fully utilises graph convolutional and graph pooling layers to operate directly on graphs. The transformer model implements a novel node encoding layer, replacing the position encoding typically used in transformers, to create a transformer with no position information that operates on graphs, encoding adjacent node properties into the edge generation process. The proposed model builds on graph generative work operating on graphs with edge features, creating a model that offers improved scalability with the number of nodes in a graph. In addition, our model is capable of learning a disentangled, interpretable latent space that represents graph properties through a mapping between latent variables and graph properties. In experiments we chose a benchmark task of molecular generation, given the importance of both generated node and edge features. Using the QM9 dataset we demonstrate that our model performs strongly across the task of generating valid, unique and novel molecules. Finally, we demonstrate that the model is interpretable by generating molecules controlled by molecular properties, and we then analyse and visualise the learned latent representation.