 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCpT: Convolutional Point Transformer for 3D Point Cloud Processing
Paper and Code
Nov 21, 2021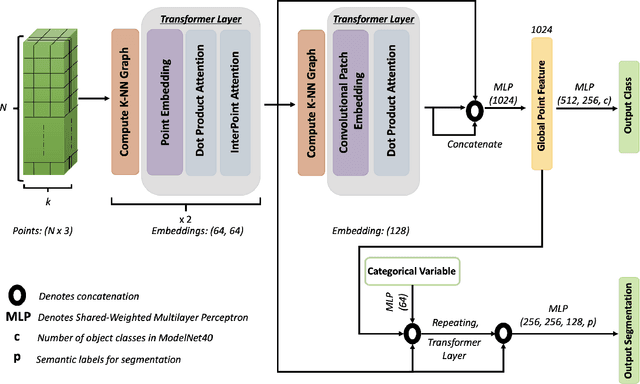
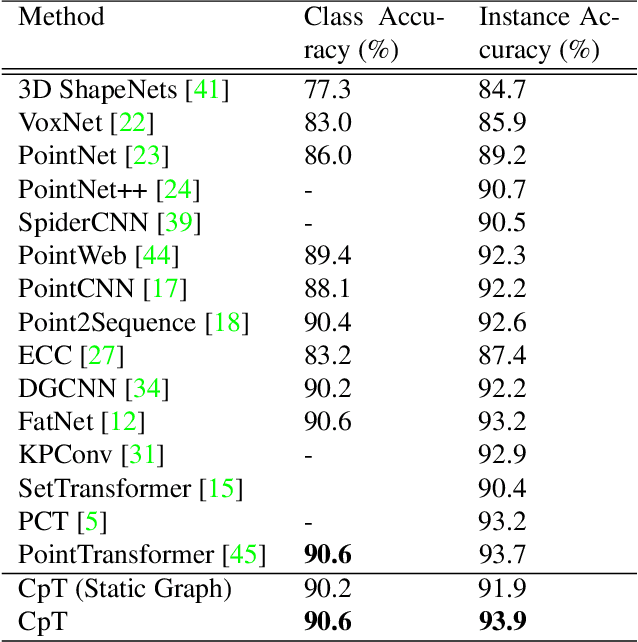
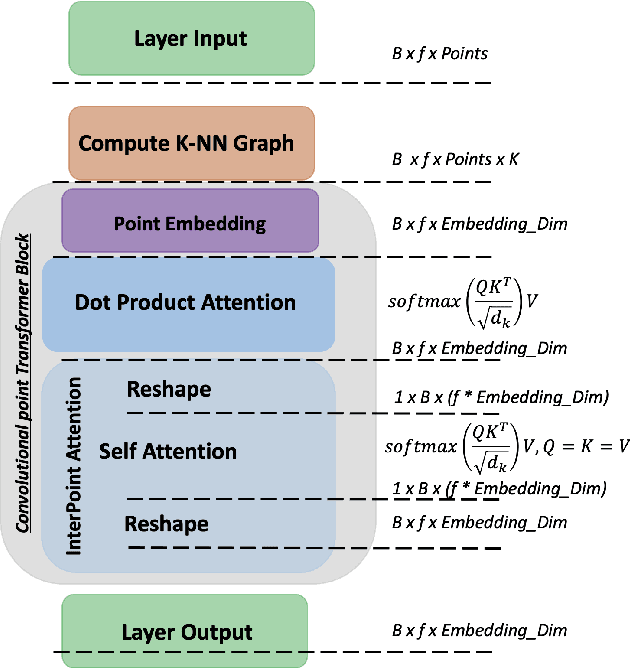

We present CpT: Convolutional point Transformer - a novel deep learning architecture for dealing with the unstructured nature of 3D point cloud data. CpT is an improvement over existing attention-based Convolutions Neural Networks as well as previous 3D point cloud processing transformers. It achieves this feat due to its effectiveness in creating a novel and robust attention-based point set embedding through a convolutional projection layer crafted for processing dynamically local point set neighbourhoods. The resultant point set embedding is robust to the permutations of the input points. Our novel CpT block builds over local neighbourhoods of points obtained via a dynamic graph computation at each layer of the networks' structure. It is fully differentiable and can be stacked just like convolutional layers to learn global properties of the points. We evaluate our model on standard benchmark datasets such as ModelNet40, ShapeNet Part Segmentation, and the S3DIS 3D indoor scene semantic segmentation dataset to show that our model can serve as an effective backbone for various point cloud processing tasks when compared to the existing state-of-the-art approaches.