 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster, Cheaper, More Accurate: Specialised Knowledge Tracing Models Outperform LLMs
Mar 03, 2026Predicting future student responses to questions is particularly valuable for educational learning platforms where it enables effective interventions. One of the key approaches to do this has been through the use of knowledge tracing (KT) models. These are small, domain-specific, temporal models trained on student question-response data. KT models are optimised for high accuracy on specific educational domains and have fast inference and scalable deployments. The rise of Large Language Models (LLMs) motivates us to ask the following questions: (1) How well can LLMs perform at predicting students' future responses to questions? (2) Are LLMs scalable for this domain? (3) How do LLMs compare to KT models on this domain-specific task? In this paper, we compare multiple LLMs and KT models across predictive performance, deployment cost, and inference speed to answer the above questions. We show that KT models outperform LLMs with respect to accuracy and F1 scores on this domain-specific task. Further, we demonstrate that LLMs are orders of magnitude slower than KT models and cost orders of magnitude more to deploy. This highlights the importance of domain-specific models for education prediction tasks and the fact that current closed source LLMs should not be used as a universal solution for all tasks.
Misconception Diagnosis From Student-Tutor Dialogue: Generate, Retrieve, Rerank
Feb 02, 2026Timely and accurate identification of student misconceptions is key to improving learning outcomes and pre-empting the compounding of student errors. However, this task is highly dependent on the effort and intuition of the teacher. In this work, we present a novel approach for detecting misconceptions from student-tutor dialogues using large language models (LLMs). First, we use a fine-tuned LLM to generate plausible misconceptions, and then retrieve the most promising candidates among these using embedding similarity with the input dialogue. These candidates are then assessed and re-ranked by another fine-tuned LLM to improve misconception relevance. Empirically, we evaluate our system on real dialogues from an educational tutoring platform. We consider multiple base LLM models including LLaMA, Qwen and Claude on zero-shot and fine-tuned settings. We find that our approach improves predictive performance over baseline models and that fine-tuning improves both generated misconception quality and can outperform larger closed-source models. Finally, we conduct ablation studies to both validate the importance of our generation and reranking steps on misconception generation quality.
Helios 2.0: A Robust, Ultra-Low Power Gesture Recognition System Optimised for Event-Sensor based Wearables
Mar 10, 2025


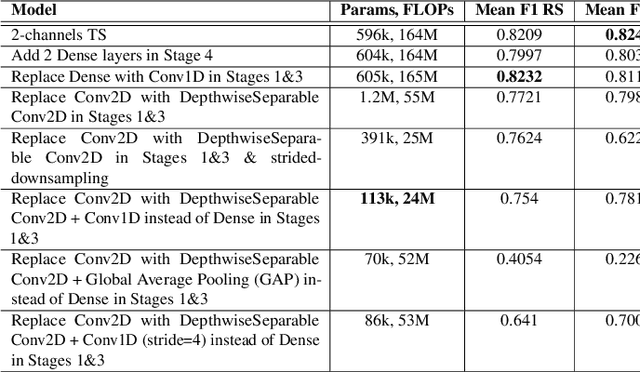
We present an advance in wearable technology: a mobile-optimized, real-time, ultra-low-power event camera system that enables natural hand gesture control for smart glasses, dramatically improving user experience. While hand gesture recognition in computer vision has advanced significantly, critical challenges remain in creating systems that are intuitive, adaptable across diverse users and environments, and energy-efficient enough for practical wearable applications. Our approach tackles these challenges through carefully selected microgestures: lateral thumb swipes across the index finger (in both directions) and a double pinch between thumb and index fingertips. These human-centered interactions leverage natural hand movements, ensuring intuitive usability without requiring users to learn complex command sequences. To overcome variability in users and environments, we developed a novel simulation methodology that enables comprehensive domain sampling without extensive real-world data collection. Our power-optimised architecture maintains exceptional performance, achieving F1 scores above 80\% on benchmark datasets featuring diverse users and environments. The resulting models operate at just 6-8 mW when exploiting the Qualcomm Snapdragon Hexagon DSP, with our 2-channel implementation exceeding 70\% F1 accuracy and our 6-channel model surpassing 80\% F1 accuracy across all gesture classes in user studies. These results were achieved using only synthetic training data. This improves on the state-of-the-art for F1 accuracy by 20\% with a power reduction 25x when using DSP. This advancement brings deploying ultra-low-power vision systems in wearable devices closer and opens new possibilities for seamless human-computer interaction.
Helios: An extremely low power event-based gesture recognition for always-on smart eyewear
Jul 11, 2024



This paper introduces Helios, the first extremely low-power, real-time, event-based hand gesture recognition system designed for all-day on smart eyewear. As augmented reality (AR) evolves, current smart glasses like the Meta Ray-Bans prioritize visual and wearable comfort at the expense of functionality. Existing human-machine interfaces (HMIs) in these devices, such as capacitive touch and voice controls, present limitations in ergonomics, privacy and power consumption. Helios addresses these challenges by leveraging natural hand interactions for a more intuitive and comfortable user experience. Our system utilizes a extremely low-power and compact 3mmx4mm/20mW event camera to perform natural hand-based gesture recognition for always-on smart eyewear. The camera's output is processed by a convolutional neural network (CNN) running on a NXP Nano UltraLite compute platform, consuming less than 350mW. Helios can recognize seven classes of gestures, including subtle microgestures like swipes and pinches, with 91% accuracy. We also demonstrate real-time performance across 20 users at a remarkably low latency of 60ms. Our user testing results align with the positive feedback we received during our recent successful demo at AWE-USA-2024.
SSL-Interactions: Pretext Tasks for Interactive Trajectory Prediction
Jan 15, 2024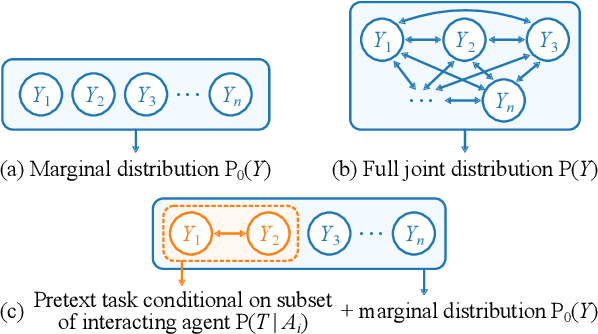
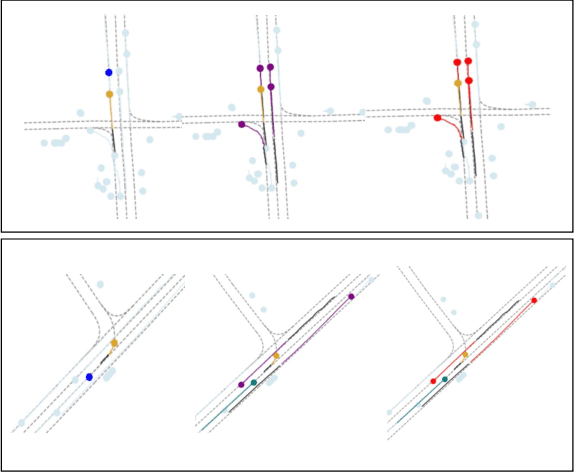
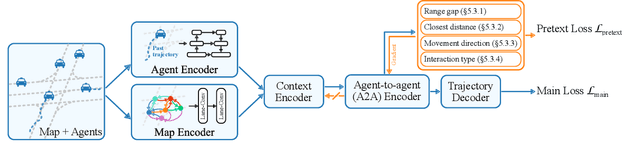
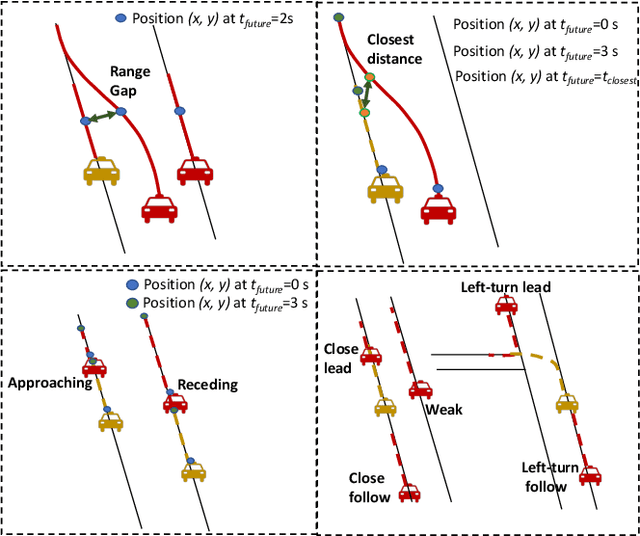
This paper addresses motion forecasting in multi-agent environments, pivotal for ensuring safety of autonomous vehicles. Traditional as well as recent data-driven marginal trajectory prediction methods struggle to properly learn non-linear agent-to-agent interactions. We present SSL-Interactions that proposes pretext tasks to enhance interaction modeling for trajectory prediction. We introduce four interaction-aware pretext tasks to encapsulate various aspects of agent interactions: range gap prediction, closest distance prediction, direction of movement prediction, and type of interaction prediction. We further propose an approach to curate interaction-heavy scenarios from datasets. This curated data has two advantages: it provides a stronger learning signal to the interaction model, and facilitates generation of pseudo-labels for interaction-centric pretext tasks. We also propose three new metrics specifically designed to evaluate predictions in interactive scenes. Our empirical evaluations indicate SSL-Interactions outperforms state-of-the-art motion forecasting methods quantitatively with up to 8% improvement, and qualitatively, for interaction-heavy scenarios.
SSL-Lanes: Self-Supervised Learning for Motion Forecasting in Autonomous Driving
Jun 28, 2022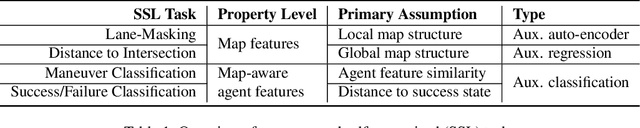
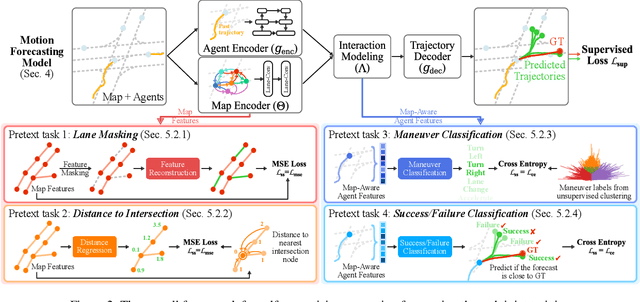
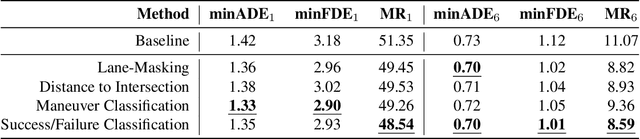
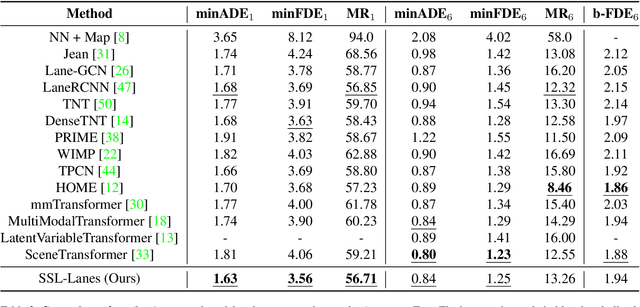
Self-supervised learning (SSL) is an emerging technique that has been successfully employed to train convolutional neural networks (CNNs) and graph neural networks (GNNs) for more transferable, generalizable, and robust representation learning. However its potential in motion forecasting for autonomous driving has rarely been explored. In this study, we report the first systematic exploration and assessment of incorporating self-supervision into motion forecasting. We first propose to investigate four novel self-supervised learning tasks for motion forecasting with theoretical rationale and quantitative and qualitative comparisons on the challenging large-scale Argoverse dataset. Secondly, we point out that our auxiliary SSL-based learning setup not only outperforms forecasting methods which use transformers, complicated fusion mechanisms and sophisticated online dense goal candidate optimization algorithms in terms of performance accuracy, but also has low inference time and architectural complexity. Lastly, we conduct several experiments to understand why SSL improves motion forecasting. Code is open-sourced at \url{https://github.com/AutoVision-cloud/SSL-Lanes}.
Visual Representation Learning with Self-Supervised Attention for Low-Label High-data Regime
Jan 30, 2022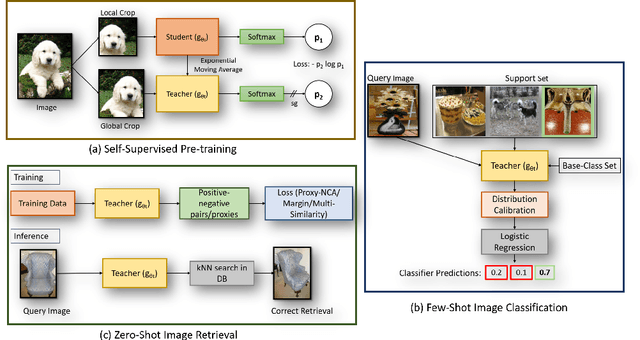
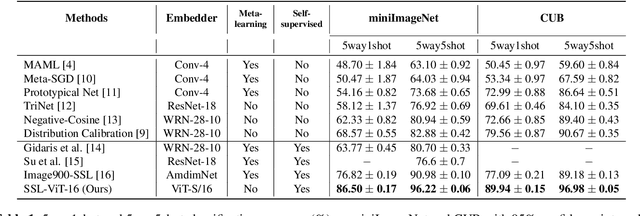
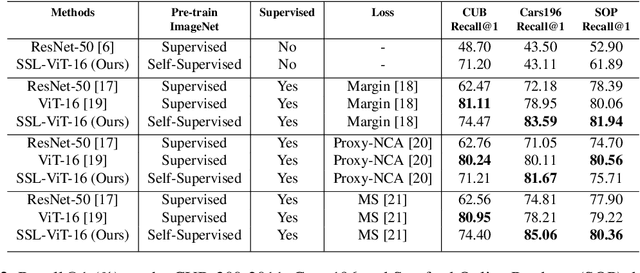

Self-supervision has shown outstanding results for natural language processing, and more recently, for image recognition. Simultaneously, vision transformers and its variants have emerged as a promising and scalable alternative to convolutions on various computer vision tasks. In this paper, we are the first to question if self-supervised vision transformers (SSL-ViTs) can be adapted to two important computer vision tasks in the low-label, high-data regime: few-shot image classification and zero-shot image retrieval. The motivation is to reduce the number of manual annotations required to train a visual embedder, and to produce generalizable and semantically meaningful embeddings. For few-shot image classification we train SSL-ViTs without any supervision, on external data, and use this trained embedder to adapt quickly to novel classes with limited number of labels. For zero-shot image retrieval, we use SSL-ViTs pre-trained on a large dataset without any labels and fine-tune them with several metric learning objectives. Our self-supervised attention representations outperforms the state-of-the-art on several public benchmarks for both tasks, namely miniImageNet and CUB200 for few-shot image classification by up-to 6%-10%, and Stanford Online Products, Cars196 and CUB200 for zero-shot image retrieval by up-to 4%-11%. Code is available at \url{https://github.com/AutoVision-cloud/SSL-ViT-lowlabel-highdata}.
3D Scene Understanding at Urban Intersection using Stereo Vision and Digital Map
Dec 10, 2021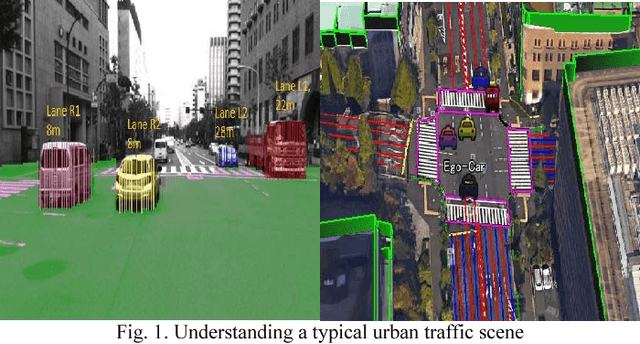
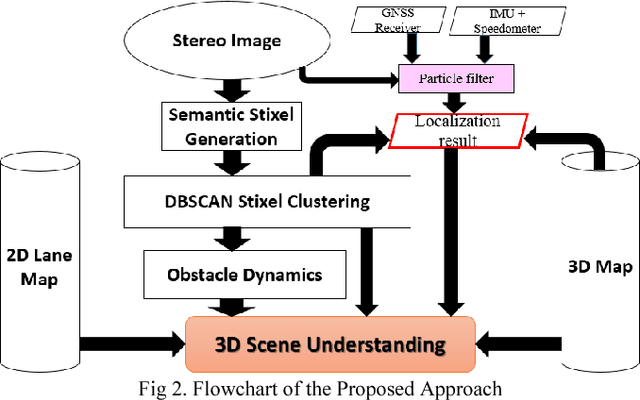
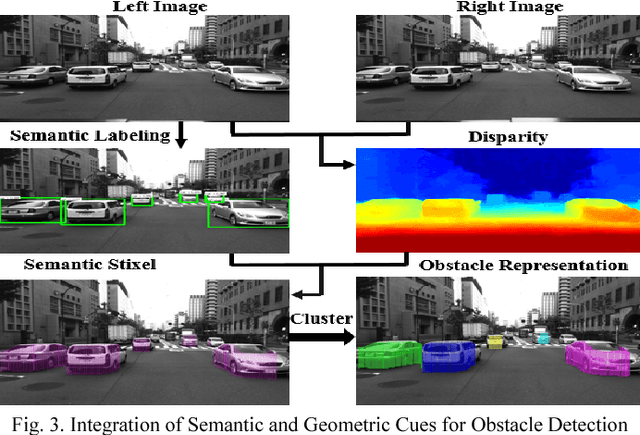
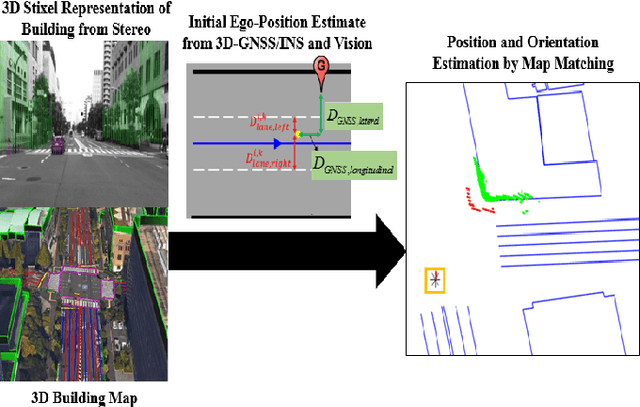
The driving behavior at urban intersections is very complex. It is thus crucial for autonomous vehicles to comprehensively understand challenging urban traffic scenes in order to navigate intersections and prevent accidents. In this paper, we introduce a stereo vision and 3D digital map based approach to spatially and temporally analyze the traffic situation at urban intersections. Stereo vision is used to detect, classify and track obstacles, while a 3D digital map is used to improve ego-localization and provide context in terms of road-layout information. A probabilistic approach that temporally integrates these geometric, semantic, dynamic and contextual cues is presented. We qualitatively and quantitatively evaluate our proposed technique on real traffic data collected at an urban canyon in Tokyo to demonstrate the efficacy of the system in providing comprehensive awareness of the traffic surroundings.
* 6 pages, 6 figures
Self-Attention Based Context-Aware 3D Object Detection
Jan 07, 2021
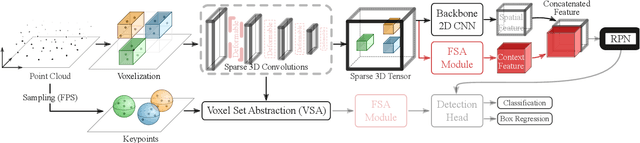
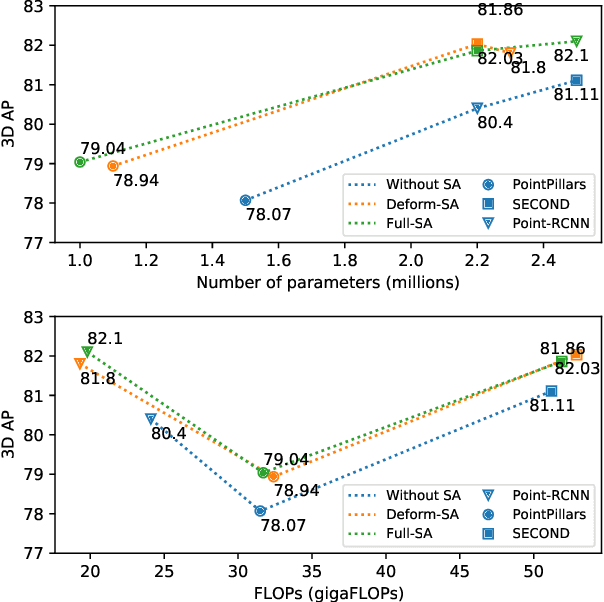
Most existing point-cloud based 3D object detectors use convolution-like operators to process information in a local neighbourhood with fixed-weight kernels and aggregate global context hierarchically. However, recent work on non-local neural networks and self-attention for 2D vision has shown that explicitly modeling global context and long-range interactions between positions can lead to more robust and competitive models. In this paper, we explore two variants of self-attention for contextual modeling in 3D object detection by augmenting convolutional features with self-attention features. We first incorporate the pairwise self-attention mechanism into the current state-of-the-art BEV, voxel and point-based detectors and show consistent improvement over strong baseline models while simultaneously significantly reducing their parameter footprint and computational cost. We also propose a self-attention variant that samples a subset of the most representative features by learning deformations over randomly sampled locations. This not only allows us to scale explicit global contextual modeling to larger point-clouds, but also leads to more discriminative and informative feature descriptors. Our method can be flexibly applied to most state-of-the-art detectors with increased accuracy and parameter and compute efficiency. We achieve new state-of-the-art detection performance on KITTI and nuScenes datasets. Code is available at \url{https://github.com/AutoVision-cloud/SA-Det3D}.
Deformable PV-RCNN: Improving 3D Object Detection with Learned Deformations
Aug 20, 2020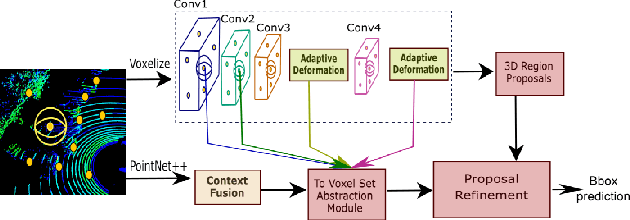
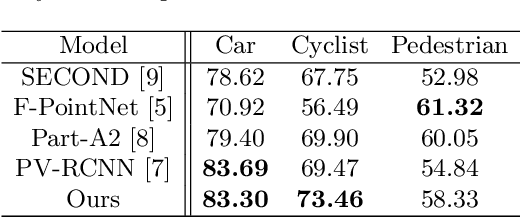
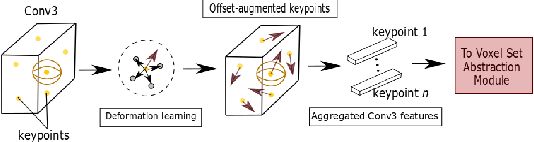

We present Deformable PV-RCNN, a high-performing point-cloud based 3D object detector. Currently, the proposal refinement methods used by the state-of-the-art two-stage detectors cannot adequately accommodate differing object scales, varying point-cloud density, part-deformation and clutter. We present a proposal refinement module inspired by 2D deformable convolution networks that can adaptively gather instance-specific features from locations where informative content exists. We also propose a simple context gating mechanism which allows the keypoints to select relevant context information for the refinement stage. We show state-of-the-art results on the KITTI dataset.