 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Representation Learning with Self-Supervised Attention for Low-Label High-data Regime
Jan 30, 2022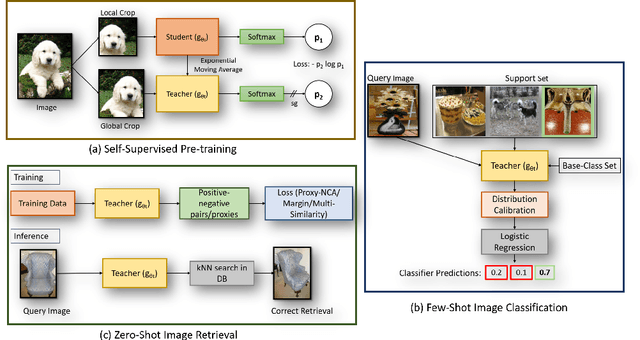
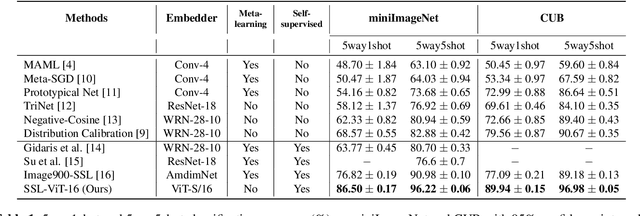
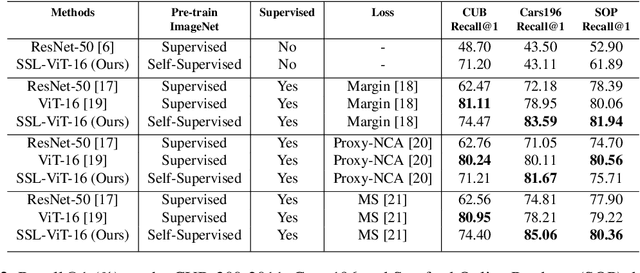

Self-supervision has shown outstanding results for natural language processing, and more recently, for image recognition. Simultaneously, vision transformers and its variants have emerged as a promising and scalable alternative to convolutions on various computer vision tasks. In this paper, we are the first to question if self-supervised vision transformers (SSL-ViTs) can be adapted to two important computer vision tasks in the low-label, high-data regime: few-shot image classification and zero-shot image retrieval. The motivation is to reduce the number of manual annotations required to train a visual embedder, and to produce generalizable and semantically meaningful embeddings. For few-shot image classification we train SSL-ViTs without any supervision, on external data, and use this trained embedder to adapt quickly to novel classes with limited number of labels. For zero-shot image retrieval, we use SSL-ViTs pre-trained on a large dataset without any labels and fine-tune them with several metric learning objectives. Our self-supervised attention representations outperforms the state-of-the-art on several public benchmarks for both tasks, namely miniImageNet and CUB200 for few-shot image classification by up-to 6%-10%, and Stanford Online Products, Cars196 and CUB200 for zero-shot image retrieval by up-to 4%-11%. Code is available at \url{https://github.com/AutoVision-cloud/SSL-ViT-lowlabel-highdata}.
TrackNet: Simultaneous Object Detection and Tracking and Its Application in Traffic Video Analysis
Feb 04, 2019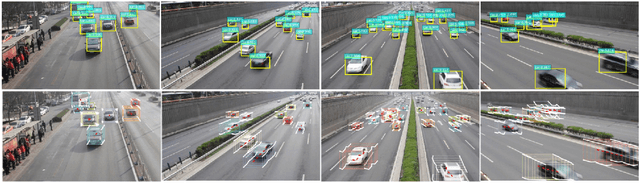
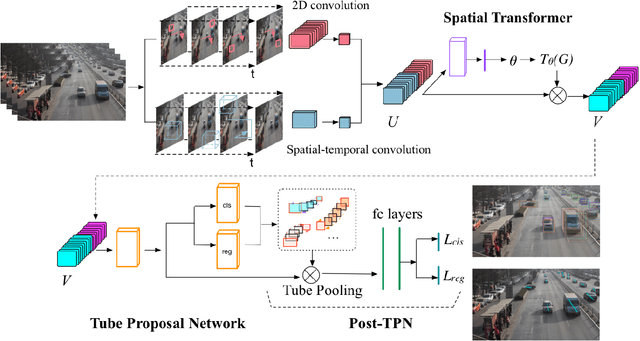
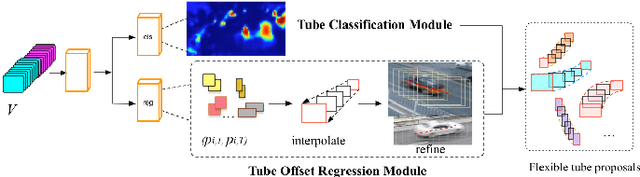
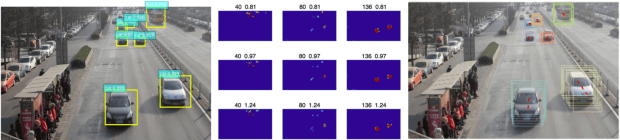
Object detection and object tracking are usually treated as two separate processes. Significant progress has been made for object detection in 2D images using deep learning networks. The usual tracking-by-detection pipeline for object tracking requires that the object is successfully detected in the first frame and all subsequent frames, and tracking is done by associating detection results. Performing object detection and object tracking through a single network remains a challenging open question. We propose a novel network structure named trackNet that can directly detect a 3D tube enclosing a moving object in a video segment by extending the faster R-CNN framework. A Tube Proposal Network (TPN) inside the trackNet is proposed to predict the objectness of each candidate tube and location parameters specifying the bounding tube. The proposed framework is applicable for detecting and tracking any object and in this paper, we focus on its application for traffic video analysis. The proposed model is trained and tested on UA-DETRAC, a large traffic video dataset available for multi-vehicle detection and tracking, and obtained very promising results.
Very Long Term Field of View Prediction for 360-degree Video Streaming
Feb 04, 2019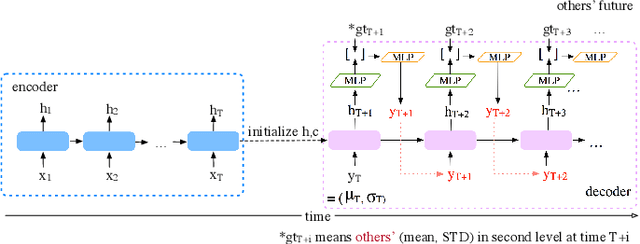
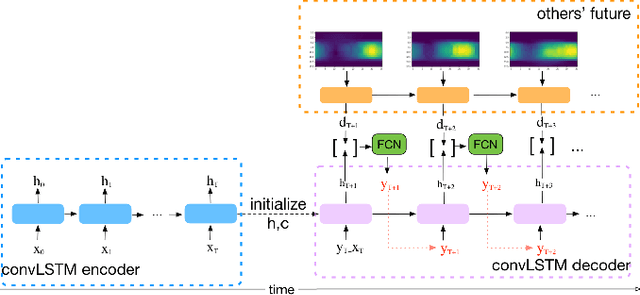
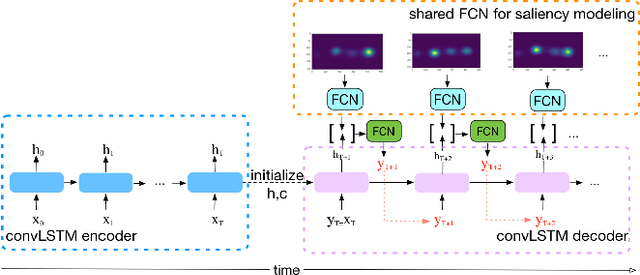
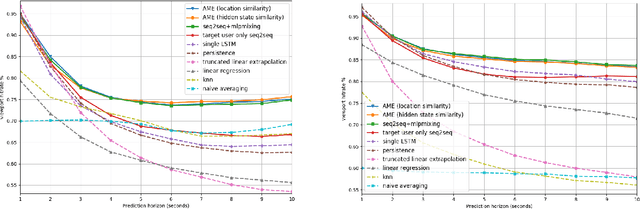
360-degree videos have gained increasing popularity in recent years with the developments and advances in Virtual Reality (VR) and Augmented Reality (AR) technologies. In such applications, a user only watches a video scene within a field of view (FoV) centered in a certain direction. Predicting the future FoV in a long time horizon (more than seconds ahead) can help save bandwidth resources in on-demand video streaming while minimizing video freezing in networks with significant bandwidth variations. In this work, we treat the FoV prediction as a sequence learning problem, and propose to predict the target user's future FoV not only based on the user's own past FoV center trajectory but also other users' future FoV locations. We propose multiple prediction models based on two different FoV representations: one using FoV center trajectories and another using equirectangular heatmaps that represent the FoV center distributions. Extensive evaluations with two public datasets demonstrate that the proposed models can significantly outperform benchmark models, and other users' FoVs are very helpful for improving long-term predictions.
Pixel-wise object tracking
Jul 03, 2018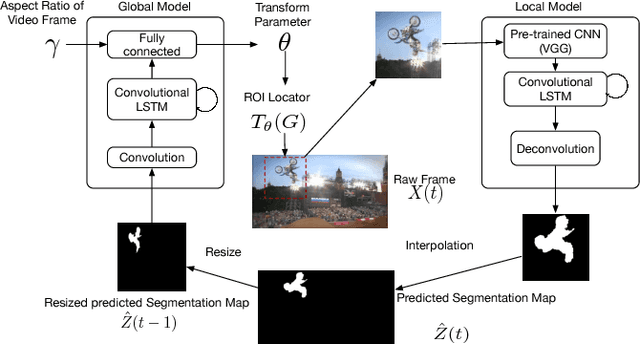
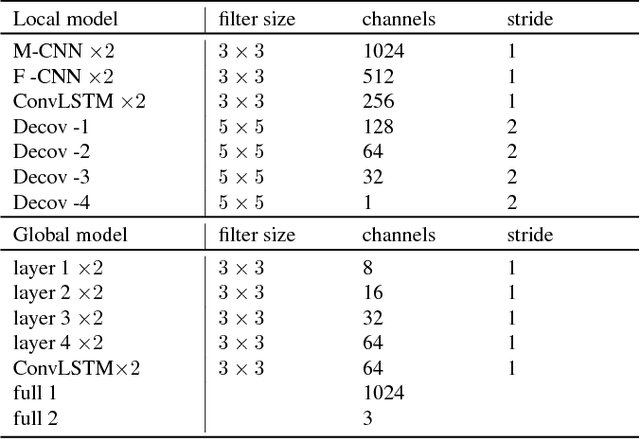
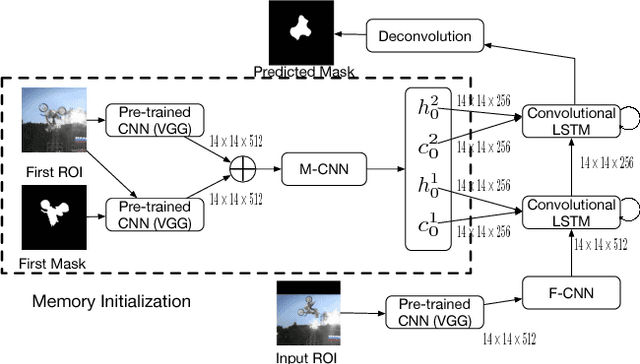
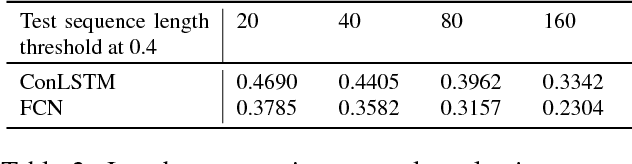
In this paper, we propose a novel pixel-wise visual object tracking framework that can track any anonymous object in a noisy background. The framework consists of two submodels, a global attention model and a local segmentation model. The global model generates a region of interests (ROI) that the object may lie in the new frame based on the past object segmentation maps, while the local model segments the new image in the ROI. Each model uses a LSTM structure to model the temporal dynamics of the motion and appearance, respectively. To circumvent the dependency of the training data between the two models, we use an iterative update strategy. Once the models are trained, there is no need to refine them to track specific objects, making our method efficient compared to online learning approaches. We demonstrate our real time pixel-wise object tracking framework on a challenging VOT dataset