 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Representation Learning with Self-Supervised Attention for Low-Label High-data Regime
Jan 30, 2022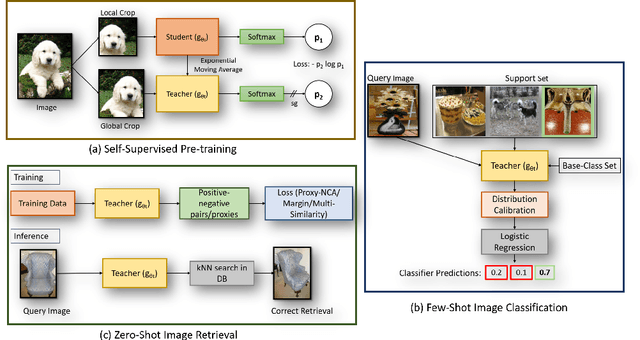
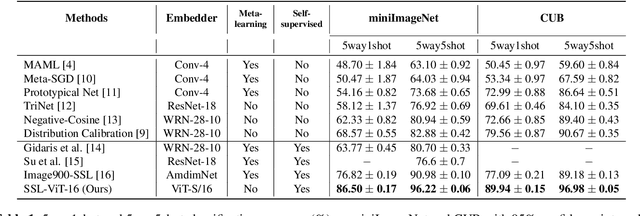
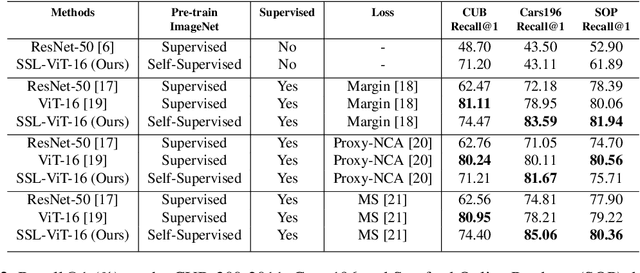

Self-supervision has shown outstanding results for natural language processing, and more recently, for image recognition. Simultaneously, vision transformers and its variants have emerged as a promising and scalable alternative to convolutions on various computer vision tasks. In this paper, we are the first to question if self-supervised vision transformers (SSL-ViTs) can be adapted to two important computer vision tasks in the low-label, high-data regime: few-shot image classification and zero-shot image retrieval. The motivation is to reduce the number of manual annotations required to train a visual embedder, and to produce generalizable and semantically meaningful embeddings. For few-shot image classification we train SSL-ViTs without any supervision, on external data, and use this trained embedder to adapt quickly to novel classes with limited number of labels. For zero-shot image retrieval, we use SSL-ViTs pre-trained on a large dataset without any labels and fine-tune them with several metric learning objectives. Our self-supervised attention representations outperforms the state-of-the-art on several public benchmarks for both tasks, namely miniImageNet and CUB200 for few-shot image classification by up-to 6%-10%, and Stanford Online Products, Cars196 and CUB200 for zero-shot image retrieval by up-to 4%-11%. Code is available at \url{https://github.com/AutoVision-cloud/SSL-ViT-lowlabel-highdata}.
Towards Good Practices in Self-supervised Representation Learning
Dec 01, 2020

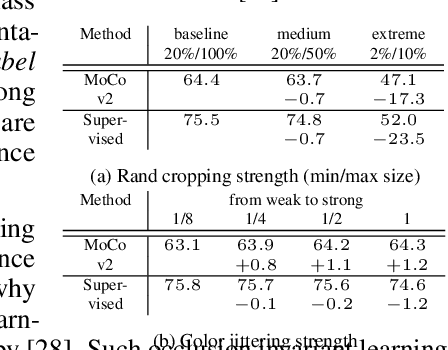

Self-supervised representation learning has seen remarkable progress in the last few years. More recently, contrastive instance learning has shown impressive results compared to its supervised learning counterparts. However, even with the ever increased interest in contrastive instance learning, it is still largely unclear why these methods work so well. In this paper, we aim to unravel some of the mysteries behind their success, which are the good practices. Through an extensive empirical analysis, we hope to not only provide insights but also lay out a set of best practices that led to the success of recent work in self-supervised representation learning.