 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGAF: Incremental Guided Attention Fusion for Depth Super-Resolution
Jan 03, 2025Accurate depth estimation is crucial for many fields, including robotics, navigation, and medical imaging. However, conventional depth sensors often produce low-resolution (LR) depth maps, making detailed scene perception challenging. To address this, enhancing LR depth maps to high-resolution (HR) ones has become essential, guided by HR-structured inputs like RGB or grayscale images. We propose a novel sensor fusion methodology for guided depth super-resolution (GDSR), a technique that combines LR depth maps with HR images to estimate detailed HR depth maps. Our key contribution is the Incremental guided attention fusion (IGAF) module, which effectively learns to fuse features from RGB images and LR depth maps, producing accurate HR depth maps. Using IGAF, we build a robust super-resolution model and evaluate it on multiple benchmark datasets. Our model achieves state-of-the-art results compared to all baseline models on the NYU v2 dataset for $\times 4$, $\times 8$, and $\times 16$ upsampling. It also outperforms all baselines in a zero-shot setting on the Middlebury, Lu, and RGB-D-D datasets. Code, environments, and models are available on GitHub.
AI-Enabled sensor fusion of time of flight imaging and mmwave for concealed metal detection
Aug 01, 2024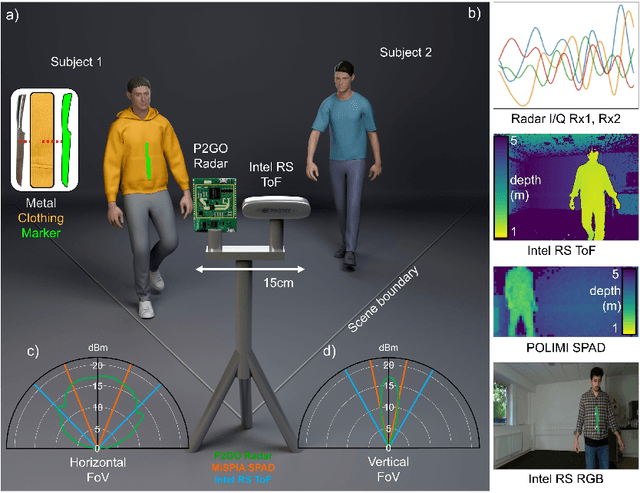
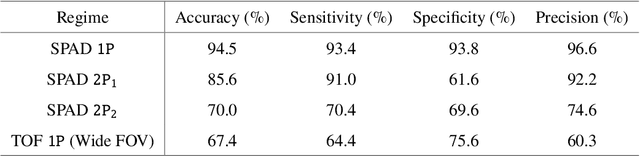
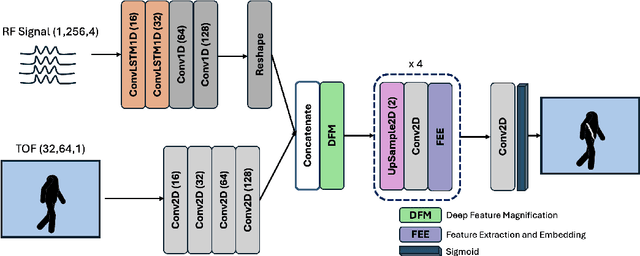

In the field of detection and ranging, multiple complementary sensing modalities may be used to enrich the information obtained from a dynamic scene. One application of this sensor fusion is in public security and surveillance, whose efficacy and privacy protection measures must be continually evaluated. We present a novel deployment of sensor fusion for the discrete detection of concealed metal objects on persons whilst preserving their privacy. This is achieved by coupling off-the-shelf mmWave radar and depth camera technology with a novel neural network architecture that processes the radar signals using convolutional Long Short-term Memory (LSTM) blocks and the depth signal, using convolutional operations. The combined latent features are then magnified using a deep feature magnification to learn cross-modality dependencies in the data. We further propose a decoder, based on the feature extraction and embedding block, to learn an efficient upsampling of the latent space to learn the location of the concealed object in the spatial domain through radar feature guidance. We demonstrate the detection of presence and inference of 3D location of concealed metal objects with an accuracy of up to 95%, using a technique that is robust to multiple persons. This work provides a demonstration of the potential for cost effective and portable sensor fusion, with strong opportunities for further development.
Is One GPU Enough? Pushing Image Generation at Higher-Resolutions with Foundation Models
Jun 12, 2024



In this work, we introduce Pixelsmith, a zero-shot text-to-image generative framework to sample images at higher resolutions with a single GPU. We are the first to show that it is possible to scale the output of a pre-trained diffusion model by a factor of 1000, opening the road for gigapixel image generation at no additional cost. Our cascading method uses the image generated at the lowest resolution as a baseline to sample at higher resolutions. For the guidance, we introduce the Slider, a tunable mechanism that fuses the overall structure contained in the first-generated image with enhanced fine details. At each inference step, we denoise patches rather than the entire latent space, minimizing memory demands such that a single GPU can handle the process, regardless of the image's resolution. Our experimental results show that Pixelsmith not only achieves higher quality and diversity compared to existing techniques, but also reduces sampling time and artifacts. The code for our work is available at https://github.com/Thanos-DB/Pixelsmith.
GLFNET: Global-Local (frequency) Filter Networks for efficient medical image segmentation
Mar 01, 2024



We propose a novel transformer-style architecture called Global-Local Filter Network (GLFNet) for medical image segmentation and demonstrate its state-of-the-art performance. We replace the self-attention mechanism with a combination of global-local filter blocks to optimize model efficiency. The global filters extract features from the whole feature map whereas the local filters are being adaptively created as 4x4 patches of the same feature map and add restricted scale information. In particular, the feature extraction takes place in the frequency domain rather than the commonly used spatial (image) domain to facilitate faster computations. The fusion of information from both spatial and frequency spaces creates an efficient model with regards to complexity, required data and performance. We test GLFNet on three benchmark datasets achieving state-of-the-art performance on all of them while being almost twice as efficient in terms of GFLOP operations.
The Fully Convolutional Transformer for Medical Image Segmentation
Jun 01, 2022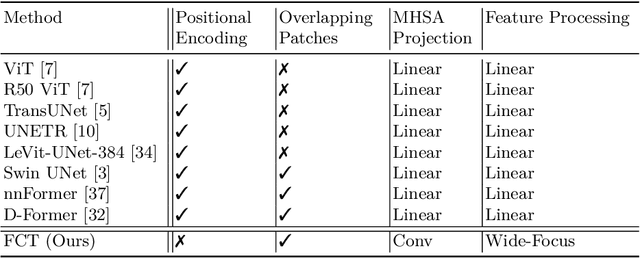
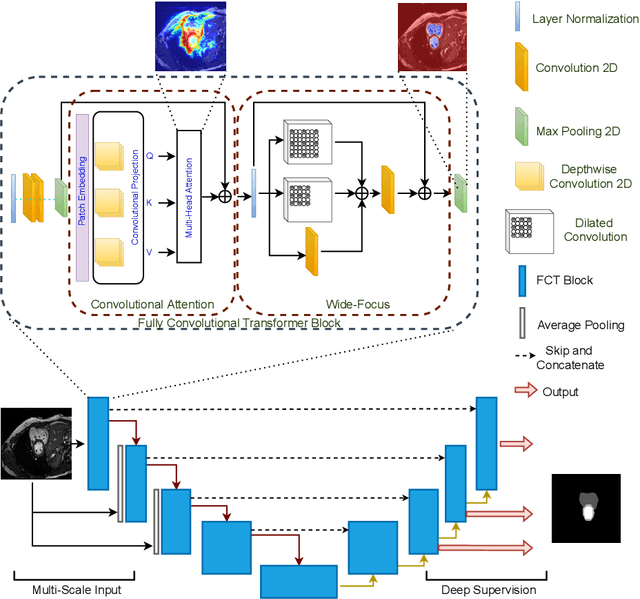
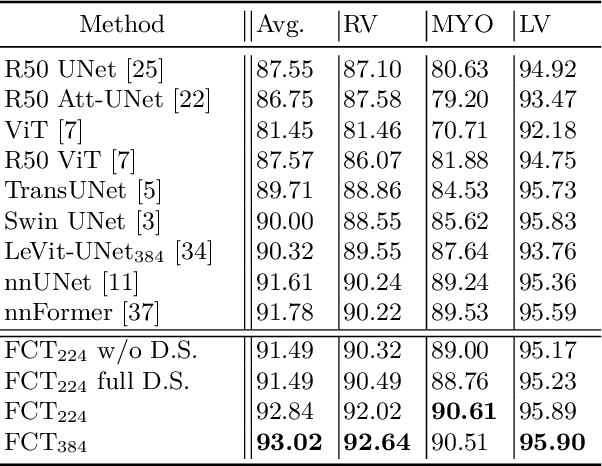
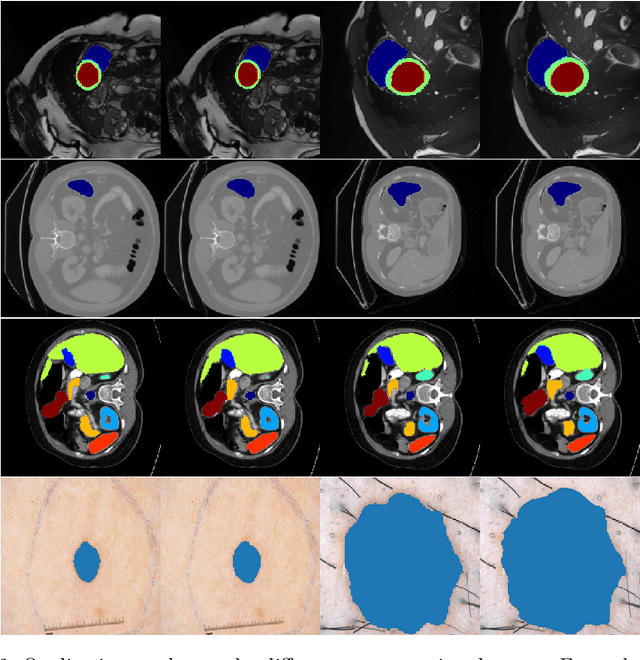
We propose a novel transformer model, capable of segmenting medical images of varying modalities. Challenges posed by the fine grained nature of medical image analysis mean that the adaptation of the transformer for their analysis is still at nascent stages. The overwhelming success of the UNet lay in its ability to appreciate the fine-grained nature of the segmentation task, an ability which existing transformer based models do not currently posses. To address this shortcoming, we propose The Fully Convolutional Transformer (FCT), which builds on the proven ability of Convolutional Neural Networks to learn effective image representations, and combines them with the ability of Transformers to effectively capture long-term dependencies in its inputs. The FCT is the first fully convolutional Transformer model in medical imaging literature. It processes its input in two stages, where first, it learns to extract long range semantic dependencies from the input image, and then learns to capture hierarchical global attributes from the features. FCT is compact, accurate and robust. Our results show that it outperforms all existing transformer architectures by large margins across multiple medical image segmentation datasets of varying data modalities without the need for any pre-training. FCT outperforms its immediate competitor on the ACDC dataset by 1.3%, on the Synapse dataset by 4.4%, on the Spleen dataset by 1.2% and on ISIC 2017 dataset by 1.1% on the dice metric, with up to five times fewer parameters. Our code, environments and models will be available via GitHub.