 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Is Not a Safety Net for Clinical VQA, but Can It Anticipate Model Failure?
Jun 15, 2026Safe deployment of clinical vision-language models (VLMs) requires reliable uncertainty estimation (UE): a signal indicating when predictions should be trusted or escalated to a clinician. We test whether current UE methods actually deliver this signal. Benchmarking 8 methods across 12 VLMs on clinical visual question-answering (VQA), we find that UE quality is not an intrinsic property of the UE method: it tracks model accuracy, degrading precisely where the model performance is weakest, and therefore where reliability is most needed. When we stress-test models by hiding the correct option among the multiple-choice answers (NOTA perturbations), accuracy collapses while uncertainty barely changes, leaving models systematically miscalibrated. Yet, we find that uncertainty on the unperturbed input reliably anticipates which predictions will collapse under NOTA, indicating that UE in current VLMs carries diagnostic information about model fragility. Our results position UE as a diagnostic tool for identifying fragile predictions and motivate perturbation-based evaluation as a path toward safe clinical deployment.
Differentially Private De-identification of Dutch Clinical Notes: A Comparative Evaluation
Apr 23, 2026Protecting patient privacy in clinical narratives is essential for enabling secondary use of healthcare data under regulations such as GDPR and HIPAA. While manual de-identification remains the gold standard, it is costly and slow, motivating the need for automated methods that combine privacy guarantees with high utility. Most automated text de-identification pipelines employed named entity recognition (NER) to identify protected entities for redaction. Although methods based on differential privacy (DP) provide formal privacy guarantees, more recently also large language models (LLMs) are increasingly used for text de-identification in the clinical domain. In this work, we present the first comparative study of DP, NER, and LLMs for Dutch clinical text de-identification. We investigate these methods separately as well as hybrid strategies that apply NER or LLM preprocessing prior to DP, and assess performance in terms of privacy leakage and extrinsic evaluation (entity and relation classification). We show that DP mechanisms alone degrade utility substantially, but combining them with linguistic preprocessing, especially LLM-based redaction, significantly improves the privacy-utility trade-off.
A Causal Framework for Evaluating ICU Discharge Strategies
Mar 26, 2026In this applied paper, we address the difficult open problem of when to discharge patients from the Intensive Care Unit. This can be conceived as an optimal stopping scenario with three added challenges: 1) the evaluation of a stopping strategy from observational data is itself a complex causal inference problem, 2) the composite objective is to minimize the length of intervention and maximize the outcome, but the two cannot be collapsed to a single dimension, and 3) the recording of variables stops when the intervention is discontinued. Our contributions are two-fold. First, we generalize the implementation of the g-formula Python package, providing a framework to evaluate stopping strategies for problems with the aforementioned structure, including positivity and coverage checks. Second, with a fully open-source pipeline, we apply this approach to MIMIC-IV, a public ICU dataset, demonstrating the potential for strategies that improve upon current care.
Interpretable phenotyping of Heart Failure patients with Dutch discharge letters
May 30, 2025



Objective: Heart failure (HF) patients present with diverse phenotypes affecting treatment and prognosis. This study evaluates models for phenotyping HF patients based on left ventricular ejection fraction (LVEF) classes, using structured and unstructured data, assessing performance and interpretability. Materials and Methods: The study analyzes all HF hospitalizations at both Amsterdam UMC hospitals (AMC and VUmc) from 2015 to 2023 (33,105 hospitalizations, 16,334 patients). Data from AMC were used for model training, and from VUmc for external validation. The dataset was unlabelled and included tabular clinical measurements and discharge letters. Silver labels for LVEF classes were generated by combining diagnosis codes, echocardiography results, and textual mentions. Gold labels were manually annotated for 300 patients for testing. Multiple Transformer-based (black-box) and Aug-Linear (white-box) models were trained and compared with baselines on structured and unstructured data. To evaluate interpretability, two clinicians annotated 20 discharge letters by highlighting information they considered relevant for LVEF classification. These were compared to SHAP and LIME explanations from black-box models and the inherent explanations of Aug-Linear models. Results: BERT-based and Aug-Linear models, using discharge letters alone, achieved the highest classification results (AUC=0.84 for BERT, 0.81 for Aug-Linear on external validation), outperforming baselines. Aug-Linear explanations aligned more closely with clinicians' explanations than post-hoc explanations on black-box models. Conclusions: Discharge letters emerged as the most informative source for phenotyping HF patients. Aug-Linear models matched black-box performance while providing clinician-aligned interpretability, supporting their use in transparent clinical decision-making.
Mitigating Overconfidence in Out-of-Distribution Detection by Capturing Extreme Activations
May 21, 2024Detecting out-of-distribution (OOD) instances is crucial for the reliable deployment of machine learning models in real-world scenarios. OOD inputs are commonly expected to cause a more uncertain prediction in the primary task; however, there are OOD cases for which the model returns a highly confident prediction. This phenomenon, denoted as "overconfidence", presents a challenge to OOD detection. Specifically, theoretical evidence indicates that overconfidence is an intrinsic property of certain neural network architectures, leading to poor OOD detection. In this work, we address this issue by measuring extreme activation values in the penultimate layer of neural networks and then leverage this proxy of overconfidence to improve on several OOD detection baselines. We test our method on a wide array of experiments spanning synthetic data and real-world data, tabular and image datasets, multiple architectures such as ResNet and Transformer, different training loss functions, and include the scenarios examined in previous theoretical work. Compared to the baselines, our method often grants substantial improvements, with double-digit increases in OOD detection AUC, and it does not damage performance in any scenario.
LLM aided semi-supervision for Extractive Dialog Summarization
Nov 23, 2023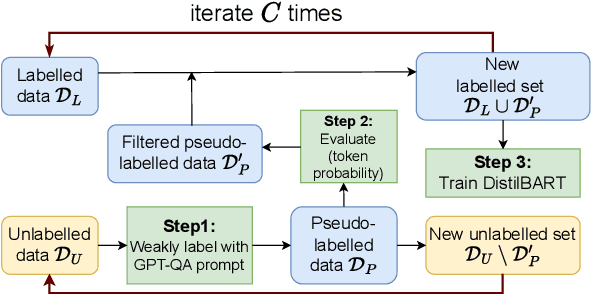
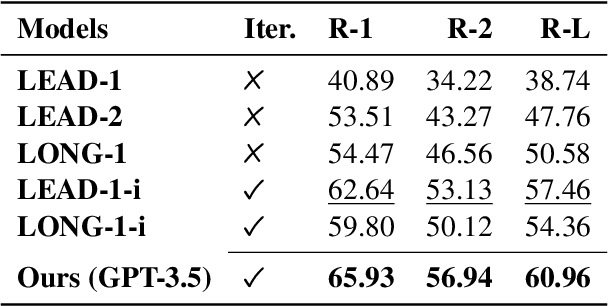
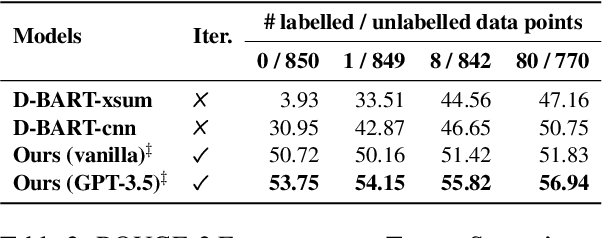

Generating high-quality summaries for chat dialogs often requires large labeled datasets. We propose a method to efficiently use unlabeled data for extractive summarization of customer-agent dialogs. In our method, we frame summarization as a question-answering problem and use state-of-the-art large language models (LLMs) to generate pseudo-labels for a dialog. We then use these pseudo-labels to fine-tune a chat summarization model, effectively transferring knowledge from the large LLM into a smaller specialized model. We demonstrate our method on the \tweetsumm dataset, and show that using 10% of the original labelled data set we can achieve 65.9/57.0/61.0 ROUGE-1/-2/-L, whereas the current state-of-the-art trained on the entire training data set obtains 65.16/55.81/64.37 ROUGE-1/-2/-L. In other words, in the worst case (i.e., ROUGE-L) we still effectively retain 94.7% of the performance while using only 10% of the data.
Causal prediction models for medication safety monitoring: The diagnosis of vancomycin-induced acute kidney injury
Nov 15, 2023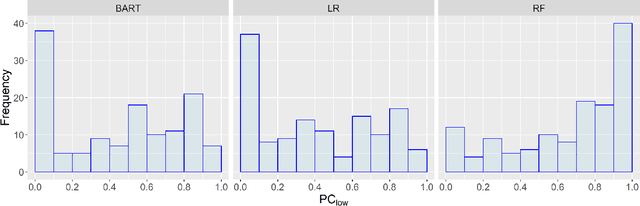


The current best practice approach for the retrospective diagnosis of adverse drug events (ADEs) in hospitalized patients relies on a full patient chart review and a formal causality assessment by multiple medical experts. This evaluation serves to qualitatively estimate the probability of causation (PC); the probability that a drug was a necessary cause of an adverse event. This practice is manual, resource intensive and prone to human biases, and may thus benefit from data-driven decision support. Here, we pioneer a causal modeling approach using observational data to estimate a lower bound of the PC (PC$_{low}$). This method includes two key causal inference components: (1) the target trial emulation framework and (2) estimation of individualized treatment effects using machine learning. We apply our method to the clinically relevant use-case of vancomycin-induced acute kidney injury in intensive care patients, and compare our causal model-based PC$_{low}$ estimates to qualitative estimates of the PC provided by a medical expert. Important limitations and potential improvements are discussed, and we conclude that future improved causal models could provide essential data-driven support for medication safety monitoring in hospitalized patients.
Unmasking the Chameleons: A Benchmark for Out-of-Distribution Detection in Medical Tabular Data
Sep 28, 2023Despite their success, Machine Learning (ML) models do not generalize effectively to data not originating from the training distribution. To reliably employ ML models in real-world healthcare systems and avoid inaccurate predictions on out-of-distribution (OOD) data, it is crucial to detect OOD samples. Numerous OOD detection approaches have been suggested in other fields - especially in computer vision - but it remains unclear whether the challenge is resolved when dealing with medical tabular data. To answer this pressing need, we propose an extensive reproducible benchmark to compare different methods across a suite of tests including both near and far OODs. Our benchmark leverages the latest versions of eICU and MIMIC-IV, two public datasets encompassing tens of thousands of ICU patients in several hospitals. We consider a wide array of density-based methods and SOTA post-hoc detectors across diverse predictive architectures, including MLP, ResNet, and Transformer. Our findings show that i) the problem appears to be solved for far-OODs, but remains open for near-OODs; ii) post-hoc methods alone perform poorly, but improve substantially when coupled with distance-based mechanisms; iii) the transformer architecture is far less overconfident compared to MLP and ResNet.
Autoencoder-based prediction of ICU clinical codes
May 08, 2023Availability of diagnostic codes in Electronic Health Records (EHRs) is crucial for patient care as well as reimbursement purposes. However, entering them in the EHR is tedious, and some clinical codes may be overlooked. Given an in-complete list of clinical codes, we investigate the performance of ML methods on predicting the complete ones, and assess the added predictive value of including other clinical patient data in this task. We used the MIMIC-III dataset and frame the task of completing the clinical codes as a recommendation problem. We con-sider various autoencoder approaches plus two strong baselines; item co-occurrence and Singular Value Decomposition (SVD). Inputs are 1) a record's known clinical codes, 2) the codes plus variables. The co-occurrence-based ap-proach performed slightly better (F1 score=0.26, Mean Average Precision [MAP]=0.19) than the SVD (F1=0.24, MAP=0.18). However, the adversarial autoencoder achieved the best performance when using the codes plus variables (F1=0.32, MAP=0.25). Adversarial autoencoders performed best in terms of F1 and were equal to vanilla and denoising autoencoders in term of MAP. Using clinical variables in addition to the incomplete codes list, improves the predictive performance of the models.
Soft-prompt tuning to predict lung cancer using primary care free-text Dutch medical notes
Mar 28, 2023We investigate different natural language processing (NLP) approaches based on contextualised word representations for the problem of early prediction of lung cancer using free-text patient medical notes of Dutch primary care physicians. Because lung cancer has a low prevalence in primary care, we also address the problem of classification under highly imbalanced classes. Specifically, we use large Transformer-based pretrained language models (PLMs) and investigate: 1) how \textit{soft prompt-tuning} -- an NLP technique used to adapt PLMs using small amounts of training data -- compares to standard model fine-tuning; 2) whether simpler static word embedding models (WEMs) can be more robust compared to PLMs in highly imbalanced settings; and 3) how models fare when trained on notes from a small number of patients. We find that 1) soft-prompt tuning is an efficient alternative to standard model fine-tuning; 2) PLMs show better discrimination but worse calibration compared to simpler static word embedding models as the classification problem becomes more imbalanced; and 3) results when training models on small number of patients are mixed and show no clear differences between PLMs and WEMs. All our code is available open source in \url{https://bitbucket.org/aumc-kik/prompt_tuning_cancer_prediction/}.