 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-tuned Large Language Models for Machine Translation in the Medical Domain
Aug 29, 2024Large Language Models (LLMs) have shown promising results on machine translation for high resource language pairs and domains. However, in specialised domains (e.g. medical) LLMs have shown lower performance compared to standard neural machine translation models. The consistency in the machine translation of terminology is crucial for users, researchers, and translators in specialised domains. In this study, we compare the performance between baseline LLMs and instruction-tuned LLMs in the medical domain. In addition, we introduce terminology from specialised medical dictionaries into the instruction formatted datasets for fine-tuning LLMs. The instruction-tuned LLMs significantly outperform the baseline models with automatic metrics.
Mortality Prediction Models with Clinical Notes Using Sparse Attention at the Word and Sentence Levels
Dec 12, 2022



Intensive Care in-hospital mortality prediction has various clinical applications. Neural prediction models, especially when capitalising on clinical notes, have been put forward as improvement on currently existing models. However, to be acceptable these models should be performant and transparent. This work studies different attention mechanisms for clinical neural prediction models in terms of their discrimination and calibration. Specifically, we investigate sparse attention as an alternative to dense attention weights in the task of in-hospital mortality prediction from clinical notes. We evaluate the attention mechanisms based on: i) local self-attention over words in a sentence, and ii) global self-attention with a transformer architecture across sentences. We demonstrate that the sparse mechanism approach outperforms the dense one for the local self-attention in terms of predictive performance with a publicly available dataset, and puts higher attention to prespecified relevant directive words. The performance at the sentence level, however, deteriorates as sentences including the influential directive words tend to be dropped all together.
Impact of Domain-Adapted Multilingual Neural Machine Translation in the Medical Domain
Dec 05, 2022



Multilingual Neural Machine Translation (MNMT) models leverage many language pairs during training to improve translation quality for low-resource languages by transferring knowledge from high-resource languages. We study the quality of a domain-adapted MNMT model in the medical domain for English-Romanian with automatic metrics and a human error typology annotation which includes terminology-specific error categories. We compare the out-of-domain MNMT with the in-domain adapted MNMT. The in-domain MNMT model outperforms the out-of-domain MNMT in all measured automatic metrics and produces fewer terminology errors.
Deep Kernel Learning for Mortality Prediction in the Face of Temporal Shift
Dec 01, 2022Neural models, with their ability to provide novel representations, have shown promising results in prediction tasks in healthcare. However, patient demographics, medical technology, and quality of care change over time. This often leads to drop in the performance of neural models for prospective patients, especially in terms of their calibration. The deep kernel learning (DKL) framework may be robust to such changes as it combines neural models with Gaussian processes, which are aware of prediction uncertainty. Our hypothesis is that out-of-distribution test points will result in probabilities closer to the global mean and hence prevent overconfident predictions. This in turn, we hypothesise, will result in better calibration on prospective data. This paper investigates DKL's behaviour when facing a temporal shift, which was naturally introduced when an information system that feeds a cohort database was changed. We compare DKL's performance to that of a neural baseline based on recurrent neural networks. We show that DKL indeed produced superior calibrated predictions. We also confirm that the DKL's predictions were indeed less sharp. In addition, DKL's discrimination ability was even improved: its AUC was 0.746 (+- 0.014 std), compared to 0.739 (+- 0.028 std) for the baseline. The paper demonstrated the importance of including uncertainty in neural computing, especially for their prospective use.
Latent Visual Cues for Neural Machine Translation
Nov 01, 2018

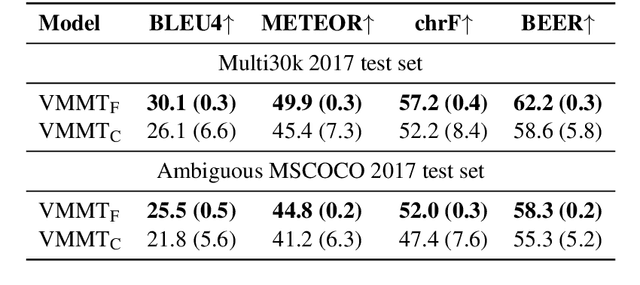
In this work, we propose to model the interaction between visual and textual features for multi-modal neural machine translation through a latent variable model. This latent variable can be seen as a stochastic embedding and it is used in the target-language decoder and also to predict image features. Importantly, even though in our model formulation we capture correlations between visual and textual features, we do not require that images be available at test time. We show that our latent variable MMT formulation improves considerably over strong baselines, including the multi-task learning approach of Elliott and Kadar (2017) and the conditional variational auto-encoder approach of Toyama et al. (2016). Finally, in an ablation study we show that (i) predicting image features in addition to only conditioning on them and (ii) imposing a constraint on the minimum amount of information encoded in the latent variable slightly improved translations.
Deep Generative Model for Joint Alignment and Word Representation
Apr 23, 2018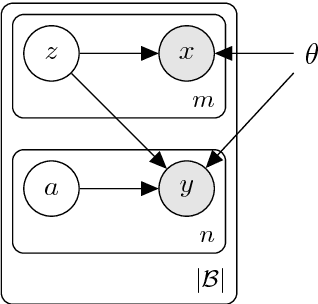



This work exploits translation data as a source of semantically relevant learning signal for models of word representation. In particular, we exploit equivalence through translation as a form of distributed context and jointly learn how to embed and align with a deep generative model. Our EmbedAlign model embeds words in their complete observed context and learns by marginalisation of latent lexical alignments. Besides, it embeds words as posterior probability densities, rather than point estimates, which allows us to compare words in context using a measure of overlap between distributions (e.g. KL divergence). We investigate our model's performance on a range of lexical semantics tasks achieving competitive results on several standard benchmarks including natural language inference, paraphrasing, and text similarity.