 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Overconfidence in Out-of-Distribution Detection by Capturing Extreme Activations
May 21, 2024Detecting out-of-distribution (OOD) instances is crucial for the reliable deployment of machine learning models in real-world scenarios. OOD inputs are commonly expected to cause a more uncertain prediction in the primary task; however, there are OOD cases for which the model returns a highly confident prediction. This phenomenon, denoted as "overconfidence", presents a challenge to OOD detection. Specifically, theoretical evidence indicates that overconfidence is an intrinsic property of certain neural network architectures, leading to poor OOD detection. In this work, we address this issue by measuring extreme activation values in the penultimate layer of neural networks and then leverage this proxy of overconfidence to improve on several OOD detection baselines. We test our method on a wide array of experiments spanning synthetic data and real-world data, tabular and image datasets, multiple architectures such as ResNet and Transformer, different training loss functions, and include the scenarios examined in previous theoretical work. Compared to the baselines, our method often grants substantial improvements, with double-digit increases in OOD detection AUC, and it does not damage performance in any scenario.
Causal prediction models for medication safety monitoring: The diagnosis of vancomycin-induced acute kidney injury
Nov 15, 2023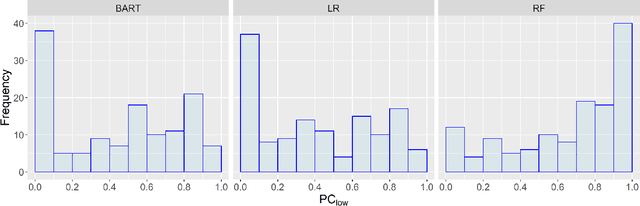


The current best practice approach for the retrospective diagnosis of adverse drug events (ADEs) in hospitalized patients relies on a full patient chart review and a formal causality assessment by multiple medical experts. This evaluation serves to qualitatively estimate the probability of causation (PC); the probability that a drug was a necessary cause of an adverse event. This practice is manual, resource intensive and prone to human biases, and may thus benefit from data-driven decision support. Here, we pioneer a causal modeling approach using observational data to estimate a lower bound of the PC (PC$_{low}$). This method includes two key causal inference components: (1) the target trial emulation framework and (2) estimation of individualized treatment effects using machine learning. We apply our method to the clinically relevant use-case of vancomycin-induced acute kidney injury in intensive care patients, and compare our causal model-based PC$_{low}$ estimates to qualitative estimates of the PC provided by a medical expert. Important limitations and potential improvements are discussed, and we conclude that future improved causal models could provide essential data-driven support for medication safety monitoring in hospitalized patients.
Fixing confirmation bias in feature attribution methods via semantic match
Jul 03, 2023
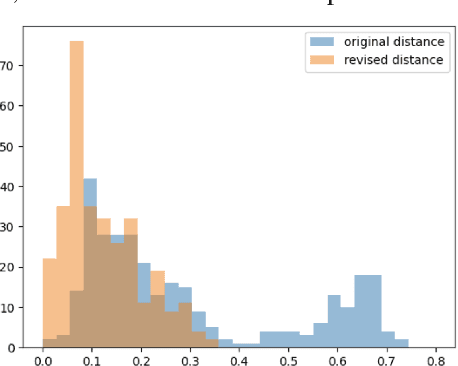
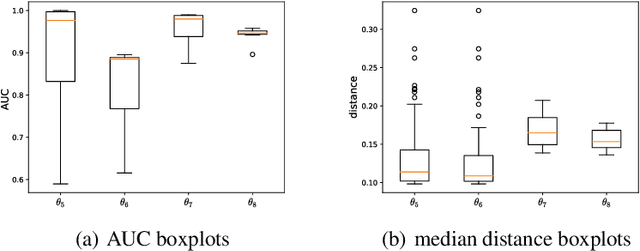
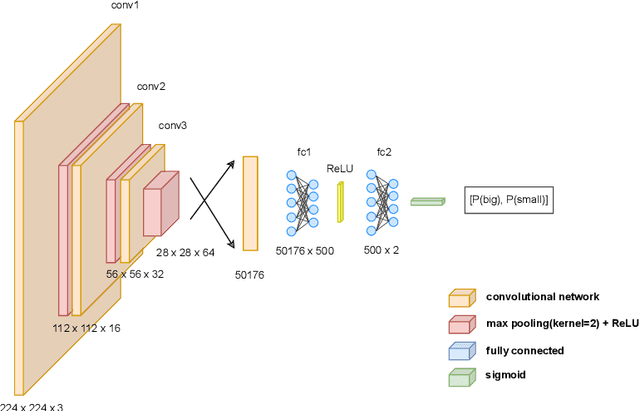
Feature attribution methods have become a staple method to disentangle the complex behavior of black box models. Despite their success, some scholars have argued that such methods suffer from a serious flaw: they do not allow a reliable interpretation in terms of human concepts. Simply put, visualizing an array of feature contributions is not enough for humans to conclude something about a model's internal representations, and confirmation bias can trick users into false beliefs about model behavior. We argue that a structured approach is required to test whether our hypotheses on the model are confirmed by the feature attributions. This is what we call the "semantic match" between human concepts and (sub-symbolic) explanations. Building on the conceptual framework put forward in Cin\`a et al. [2023], we propose a structured approach to evaluate semantic match in practice. We showcase the procedure in a suite of experiments spanning tabular and image data, and show how the assessment of semantic match can give insight into both desirable (e.g., focusing on an object relevant for prediction) and undesirable model behaviors (e.g., focusing on a spurious correlation). We couple our experimental results with an analysis on the metrics to measure semantic match, and argue that this approach constitutes the first step towards resolving the issue of confirmation bias in XAI.
Semantic match: Debugging feature attribution methods in XAI for healthcare
Jan 06, 2023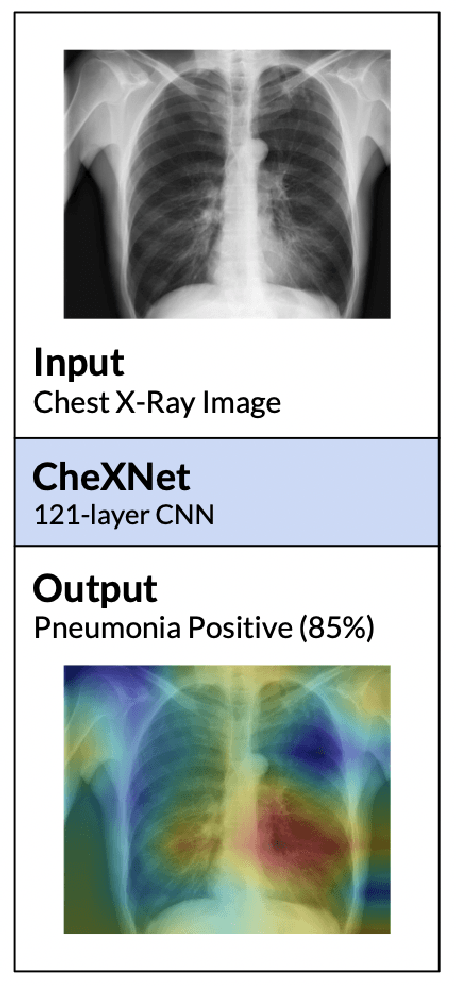

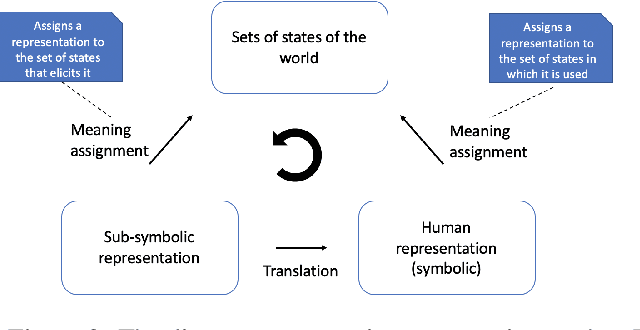
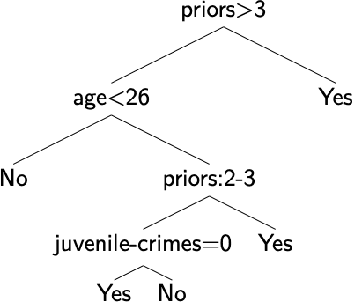
The recent spike in certified Artificial Intelligence (AI) tools for healthcare has renewed the debate around adoption of this technology. One thread of such debate concerns Explainable AI (XAI) and its promise to render AI devices more transparent and trustworthy. A few voices active in the medical AI space have expressed concerns on the reliability of Explainable AI techniques and especially feature attribution methods, questioning their use and inclusion in guidelines and standards. Despite valid concerns, we argue that existing criticism on the viability of post-hoc local explainability methods throws away the baby with the bathwater by generalizing a problem that is specific to image data. We begin by characterizing the problem as a lack of semantic match between explanations and human understanding. To understand when feature importance can be used reliably, we introduce a distinction between feature importance of low- and high-level features. We argue that for data types where low-level features come endowed with a clear semantics, such as tabular data like Electronic Health Records (EHRs), semantic match can be obtained, and thus feature attribution methods can still be employed in a meaningful and useful way.
Why we do need Explainable AI for Healthcare
Jun 30, 2022
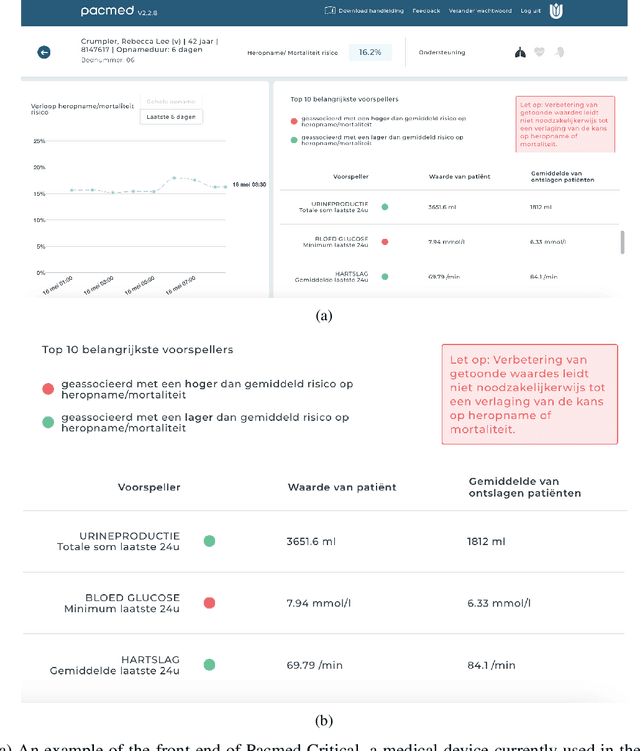
The recent spike in certified Artificial Intelligence (AI) tools for healthcare has renewed the debate around adoption of this technology. One thread of such debate concerns Explainable AI and its promise to render AI devices more transparent and trustworthy. A few voices active in the medical AI space have expressed concerns on the reliability of Explainable AI techniques, questioning their use and inclusion in guidelines and standards. Revisiting such criticisms, this article offers a balanced and comprehensive perspective on the utility of Explainable AI, focusing on the specificity of clinical applications of AI and placing them in the context of healthcare interventions. Against its detractors and despite valid concerns, we argue that the Explainable AI research program is still central to human-machine interaction and ultimately our main tool against loss of control, a danger that cannot be prevented by rigorous clinical validation alone.
Out-of-Distribution Detection for Medical Applications: Guidelines for Practical Evaluation
Sep 30, 2021
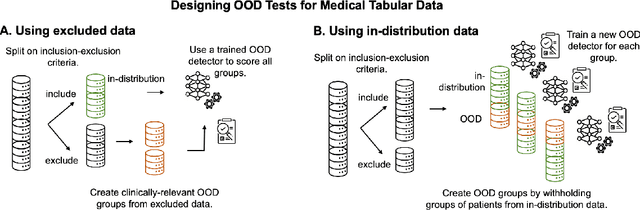
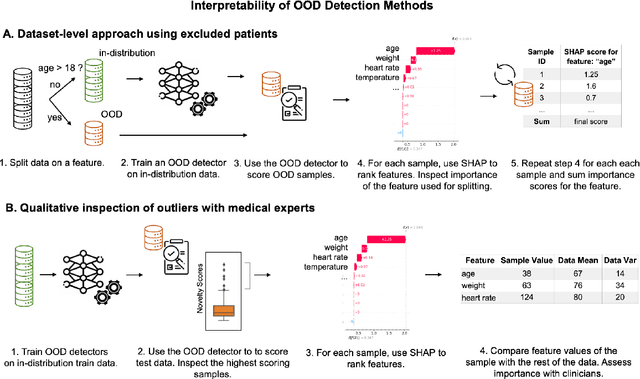
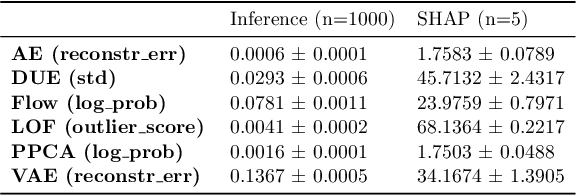
Detection of Out-of-Distribution (OOD) samples in real time is a crucial safety check for deployment of machine learning models in the medical field. Despite a growing number of uncertainty quantification techniques, there is a lack of evaluation guidelines on how to select OOD detection methods in practice. This gap impedes implementation of OOD detection methods for real-world applications. Here, we propose a series of practical considerations and tests to choose the best OOD detector for a specific medical dataset. These guidelines are illustrated on a real-life use case of Electronic Health Records (EHR). Our results can serve as a guide for implementation of OOD detection methods in clinical practice, mitigating risks associated with the use of machine learning models in healthcare.
A pragmatic approach to estimating average treatment effects from EHR data: the effect of prone positioning on mechanically ventilated COVID-19 patients
Sep 14, 2021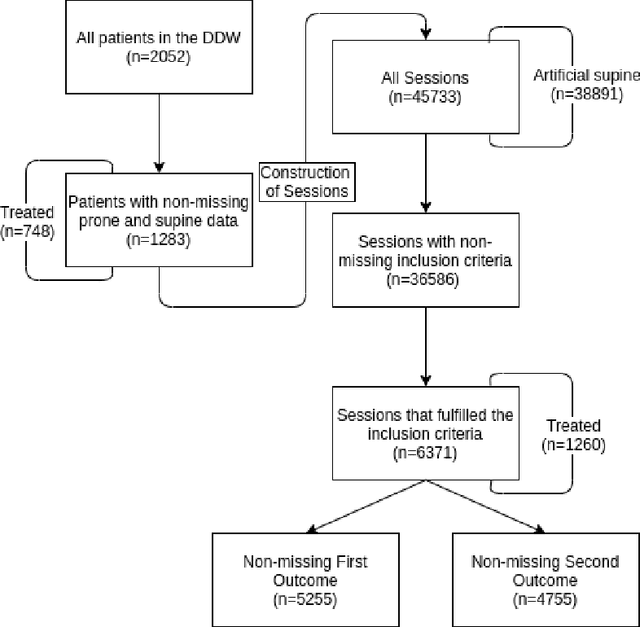
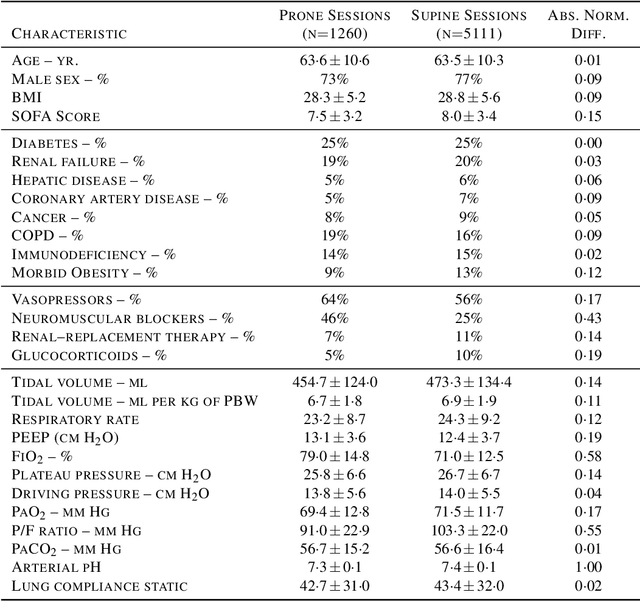


Despite the recent progress in the field of causal inference, to date there is no agreed upon methodology to glean treatment effect estimation from observational data. The consequence on clinical practice is that, when lacking results from a randomized trial, medical personnel is left without guidance on what seems to be effective in a real-world scenario. This article showcases a pragmatic methodology to obtain preliminary estimation of treatment effect from observational studies. Our approach was tested on the estimation of treatment effect of the proning maneuver on oxygenation levels, on a cohort of COVID-19 Intensive Care patients. We modeled our study design on a recent RCT for proning (the PROSEVA trial). Linear regression, propensity score models such as blocking and DR-IPW, BART and two versions of Counterfactual Regression were employed to provide estimates on observational data comprising first wave COVID-19 ICU patient data from 25 Dutch hospitals. 6371 data points, from 745 mechanically ventilated patients, were included in the study. Estimates for the early effect of proning -- P/F ratio from 2 to 8 hours after proning -- ranged between 14.54 and 20.11 mm Hg depending on the model. Estimates for the late effect of proning -- oxygenation from 12 to 24 hours after proning -- ranged between 13.53 and 15.26 mm Hg. All confidence interval being strictly above zero indicated that the effect of proning on oxygenation for COVID-19 patient was positive and comparable in magnitude to the effect on non COVID-19 patients. These results provide further evidence on the effectiveness of proning on the treatment of COVID-19 patients. This study, along with the accompanying open-source code, provides a blueprint for treatment effect estimation in scenarios where RCT data is lacking. Funding: SIDN fund, CovidPredict consortium, Pacmed.
Know Your Limits: Monotonicity & Softmax Make Neural Classifiers Overconfident on OOD Data
Dec 11, 2020

A crucial requirement for reliable deployment of deep learning models for safety-critical applications is the ability to identify out-of-distribution (OOD) data points, samples which differ from the training data and on which a model might underperform. Previous work has attempted to tackle this problem using uncertainty estimation techniques. However, there is empirical evidence that a large family of these techniques do not detect OOD reliably in classification tasks. This paper puts forward a theoretical explanation for said experimental findings. We prove that such techniques are not able to reliably identify OOD samples in a classification setting, provided the models satisfy weak assumptions about the monotonicity of feature values and resulting class probabilities. This result stems from the interplay between the saturating nature of activation functions like sigmoid or softmax, coupled with the most widely-used uncertainty metrics.
Trust Issues: Uncertainty Estimation Does Not Enable Reliable OOD Detection On Medical Tabular Data
Nov 06, 2020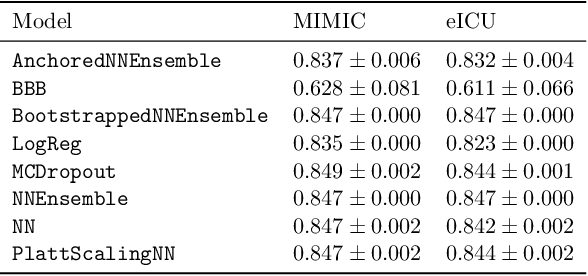
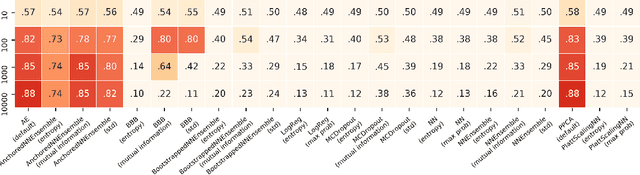
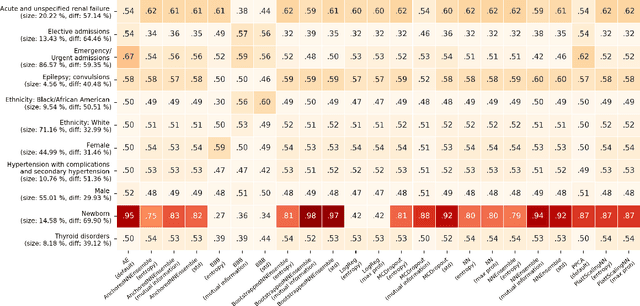

When deploying machine learning models in high-stakes real-world environments such as health care, it is crucial to accurately assess the uncertainty concerning a model's prediction on abnormal inputs. However, there is a scarcity of literature analyzing this problem on medical data, especially on mixed-type tabular data such as Electronic Health Records. We close this gap by presenting a series of tests including a large variety of contemporary uncertainty estimation techniques, in order to determine whether they are able to identify out-of-distribution (OOD) patients. In contrast to previous work, we design tests on realistic and clinically relevant OOD groups, and run experiments on real-world medical data. We find that almost all techniques fail to achieve convincing results, partly disagreeing with earlier findings.
Uncertainty estimation for classification and risk prediction in medical settings
Apr 13, 2020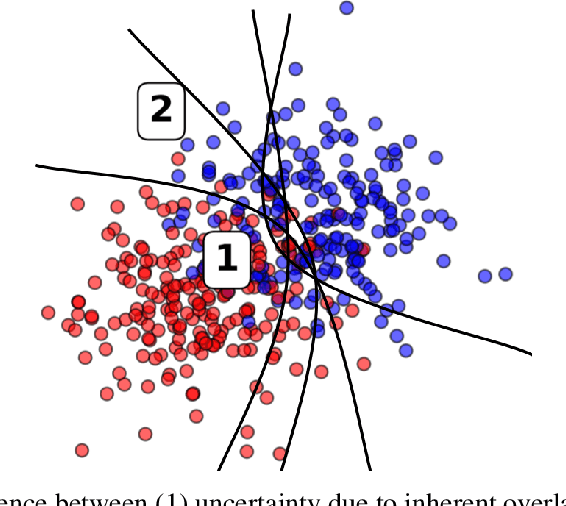
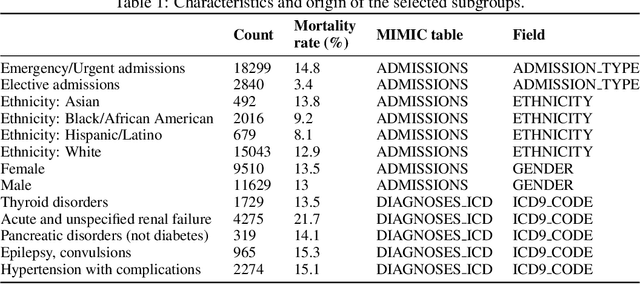
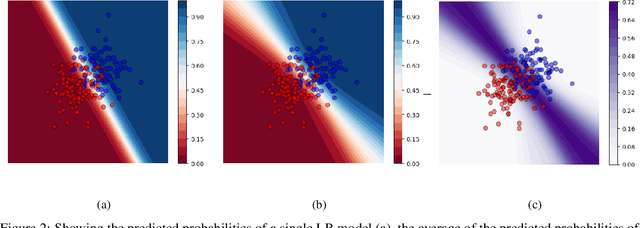
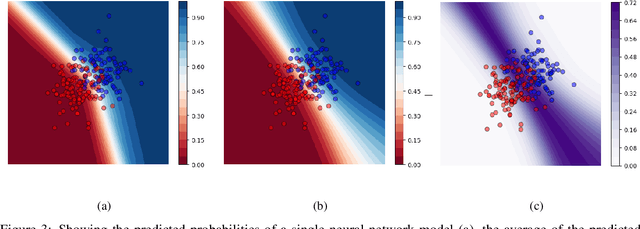
In a data-scarce field such as healthcare, where models often deliver predictions on patients with rare conditions, the ability to measure the uncertainty of a model's prediction could potentially lead to improved effectiveness of decision support tools and increased user trust. This work advances the understanding of uncertainty estimation for classification and risk prediction on medical tabular data, in a three-fold way. First, we analyze two families of promising methods and discuss the preferred approach for uncertainty estimation for classification and risk prediction. Second, these remarks are enriched by considerations of the interplay of uncertainty estimation with class imbalance, post-modeling calibration and other modeling procedures. Finally, we expand and refine the set of heuristics to select an uncertainty estimation technique, introducing tests for clinically-relevant scenarios such as generalization to uncommon pathologies, changes in clinical protocol and simulations of corrupted data. These findings are supported by an array of experiments on toy and real-world data