 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Issues: Uncertainty Estimation Does Not Enable Reliable OOD Detection On Medical Tabular Data
Nov 06, 2020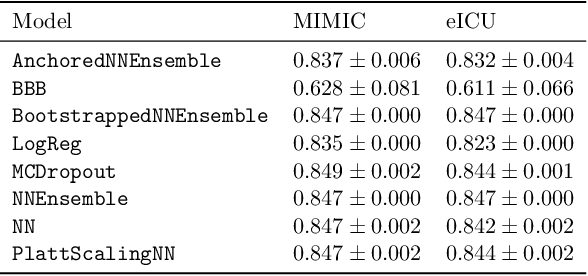
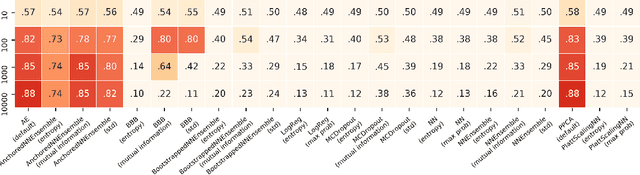
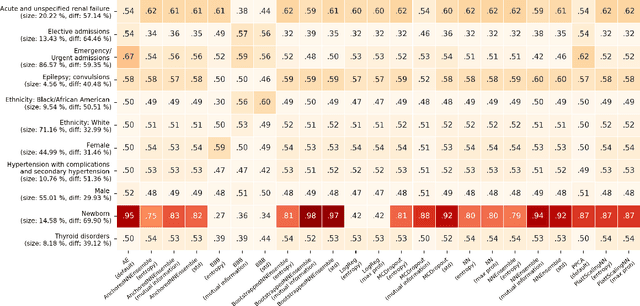

When deploying machine learning models in high-stakes real-world environments such as health care, it is crucial to accurately assess the uncertainty concerning a model's prediction on abnormal inputs. However, there is a scarcity of literature analyzing this problem on medical data, especially on mixed-type tabular data such as Electronic Health Records. We close this gap by presenting a series of tests including a large variety of contemporary uncertainty estimation techniques, in order to determine whether they are able to identify out-of-distribution (OOD) patients. In contrast to previous work, we design tests on realistic and clinically relevant OOD groups, and run experiments on real-world medical data. We find that almost all techniques fail to achieve convincing results, partly disagreeing with earlier findings.
Uncertainty estimation for classification and risk prediction in medical settings
Apr 13, 2020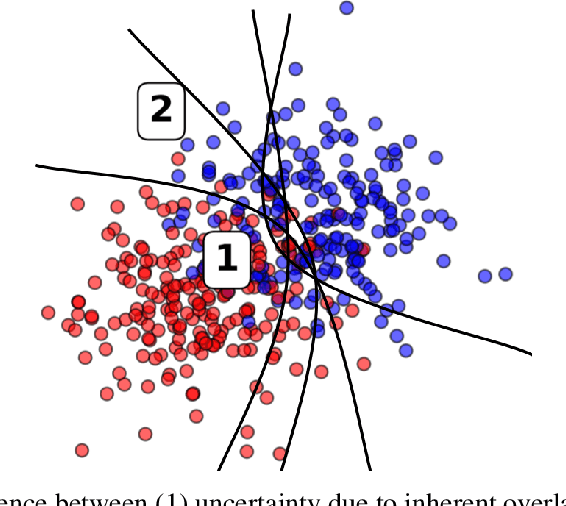
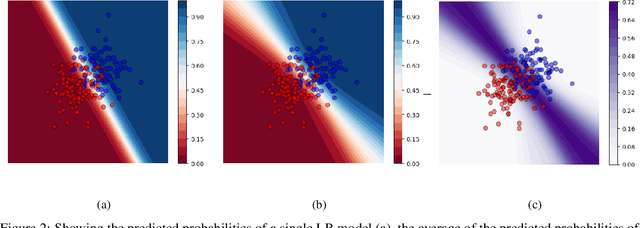
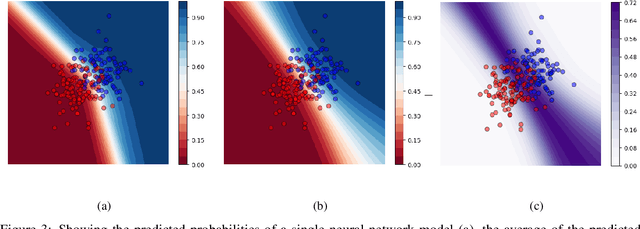
In a data-scarce field such as healthcare, where models often deliver predictions on patients with rare conditions, the ability to measure the uncertainty of a model's prediction could potentially lead to improved effectiveness of decision support tools and increased user trust. This work advances the understanding of uncertainty estimation for classification and risk prediction on medical tabular data, in a three-fold way. First, we analyze two families of promising methods and discuss the preferred approach for uncertainty estimation for classification and risk prediction. Second, these remarks are enriched by considerations of the interplay of uncertainty estimation with class imbalance, post-modeling calibration and other modeling procedures. Finally, we expand and refine the set of heuristics to select an uncertainty estimation technique, introducing tests for clinically-relevant scenarios such as generalization to uncommon pathologies, changes in clinical protocol and simulations of corrupted data. These findings are supported by an array of experiments on toy and real-world data