 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing confirmation bias in feature attribution methods via semantic match
Jul 03, 2023
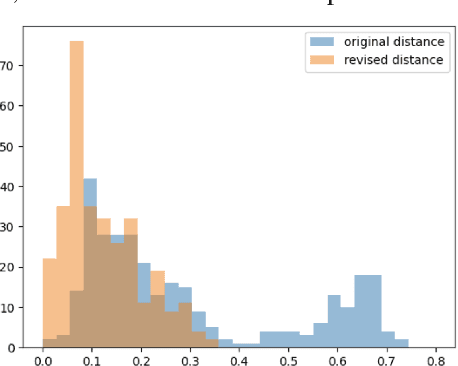
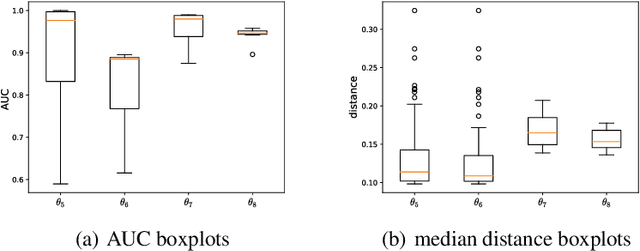
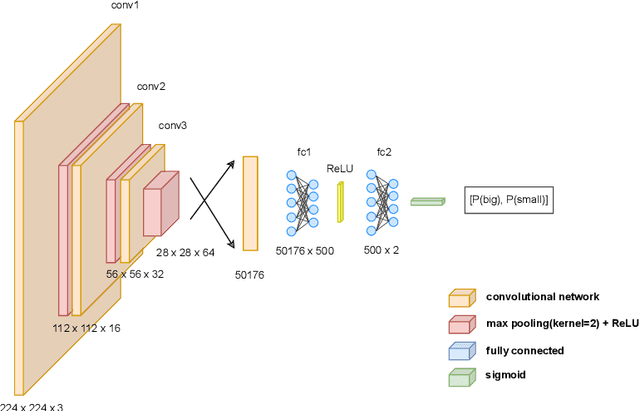
Feature attribution methods have become a staple method to disentangle the complex behavior of black box models. Despite their success, some scholars have argued that such methods suffer from a serious flaw: they do not allow a reliable interpretation in terms of human concepts. Simply put, visualizing an array of feature contributions is not enough for humans to conclude something about a model's internal representations, and confirmation bias can trick users into false beliefs about model behavior. We argue that a structured approach is required to test whether our hypotheses on the model are confirmed by the feature attributions. This is what we call the "semantic match" between human concepts and (sub-symbolic) explanations. Building on the conceptual framework put forward in Cin\`a et al. [2023], we propose a structured approach to evaluate semantic match in practice. We showcase the procedure in a suite of experiments spanning tabular and image data, and show how the assessment of semantic match can give insight into both desirable (e.g., focusing on an object relevant for prediction) and undesirable model behaviors (e.g., focusing on a spurious correlation). We couple our experimental results with an analysis on the metrics to measure semantic match, and argue that this approach constitutes the first step towards resolving the issue of confirmation bias in XAI.
Finding Regions of Counterfactual Explanations via Robust Optimization
Jan 26, 2023



Counterfactual explanations play an important role in detecting bias and improving the explainability of data-driven classification models. A counterfactual explanation (CE) is a minimal perturbed data point for which the decision of the model changes. Most of the existing methods can only provide one CE, which may not be achievable for the user. In this work we derive an iterative method to calculate robust CEs, i.e. CEs that remain valid even after the features are slightly perturbed. To this end, our method provides a whole region of CEs allowing the user to choose a suitable recourse to obtain a desired outcome. We use algorithmic ideas from robust optimization and prove convergence results for the most common machine learning methods including logistic regression, decision trees, random forests, and neural networks. Our experiments show that our method can efficiently generate globally optimal robust CEs for a variety of common data sets and classification models.
Semantic match: Debugging feature attribution methods in XAI for healthcare
Jan 06, 2023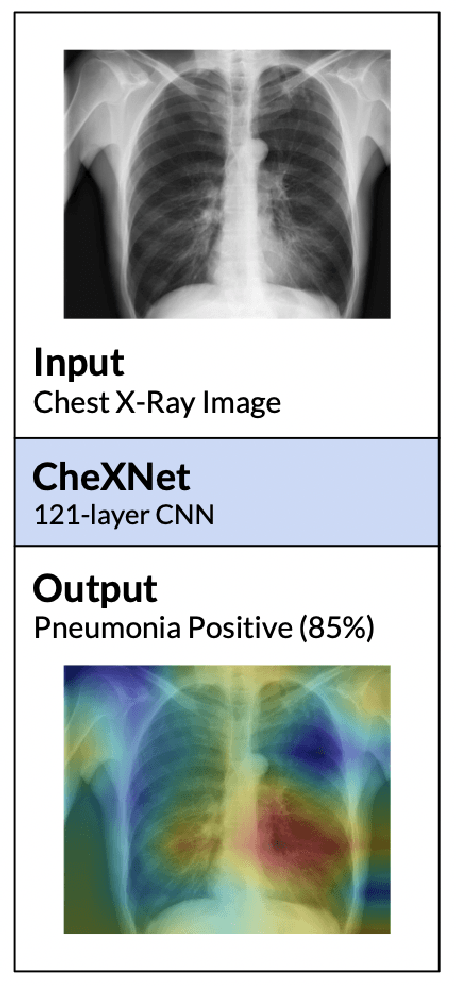

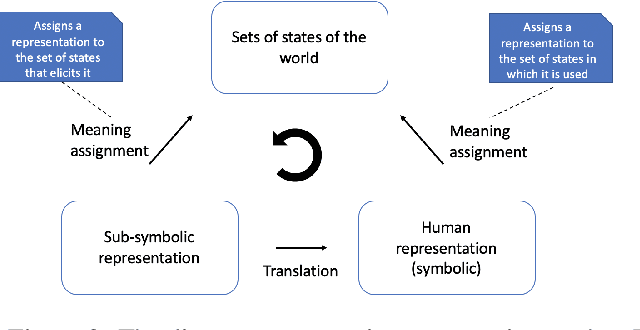
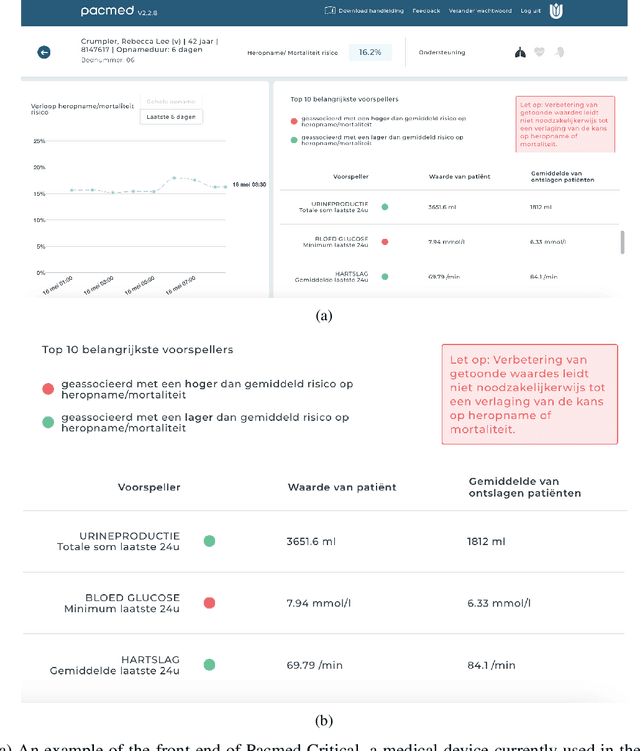
The recent spike in certified Artificial Intelligence (AI) tools for healthcare has renewed the debate around adoption of this technology. One thread of such debate concerns Explainable AI (XAI) and its promise to render AI devices more transparent and trustworthy. A few voices active in the medical AI space have expressed concerns on the reliability of Explainable AI techniques and especially feature attribution methods, questioning their use and inclusion in guidelines and standards. Despite valid concerns, we argue that existing criticism on the viability of post-hoc local explainability methods throws away the baby with the bathwater by generalizing a problem that is specific to image data. We begin by characterizing the problem as a lack of semantic match between explanations and human understanding. To understand when feature importance can be used reliably, we introduce a distinction between feature importance of low- and high-level features. We argue that for data types where low-level features come endowed with a clear semantics, such as tabular data like Electronic Health Records (EHRs), semantic match can be obtained, and thus feature attribution methods can still be employed in a meaningful and useful way.
Why we do need Explainable AI for Healthcare
Jun 30, 2022
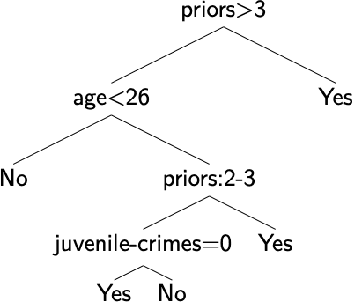
The recent spike in certified Artificial Intelligence (AI) tools for healthcare has renewed the debate around adoption of this technology. One thread of such debate concerns Explainable AI and its promise to render AI devices more transparent and trustworthy. A few voices active in the medical AI space have expressed concerns on the reliability of Explainable AI techniques, questioning their use and inclusion in guidelines and standards. Revisiting such criticisms, this article offers a balanced and comprehensive perspective on the utility of Explainable AI, focusing on the specificity of clinical applications of AI and placing them in the context of healthcare interventions. Against its detractors and despite valid concerns, we argue that the Explainable AI research program is still central to human-machine interaction and ultimately our main tool against loss of control, a danger that cannot be prevented by rigorous clinical validation alone.