 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoencoder-based prediction of ICU clinical codes
May 08, 2023Availability of diagnostic codes in Electronic Health Records (EHRs) is crucial for patient care as well as reimbursement purposes. However, entering them in the EHR is tedious, and some clinical codes may be overlooked. Given an in-complete list of clinical codes, we investigate the performance of ML methods on predicting the complete ones, and assess the added predictive value of including other clinical patient data in this task. We used the MIMIC-III dataset and frame the task of completing the clinical codes as a recommendation problem. We con-sider various autoencoder approaches plus two strong baselines; item co-occurrence and Singular Value Decomposition (SVD). Inputs are 1) a record's known clinical codes, 2) the codes plus variables. The co-occurrence-based ap-proach performed slightly better (F1 score=0.26, Mean Average Precision [MAP]=0.19) than the SVD (F1=0.24, MAP=0.18). However, the adversarial autoencoder achieved the best performance when using the codes plus variables (F1=0.32, MAP=0.25). Adversarial autoencoders performed best in terms of F1 and were equal to vanilla and denoising autoencoders in term of MAP. Using clinical variables in addition to the incomplete codes list, improves the predictive performance of the models.
Soft-prompt tuning to predict lung cancer using primary care free-text Dutch medical notes
Mar 28, 2023We investigate different natural language processing (NLP) approaches based on contextualised word representations for the problem of early prediction of lung cancer using free-text patient medical notes of Dutch primary care physicians. Because lung cancer has a low prevalence in primary care, we also address the problem of classification under highly imbalanced classes. Specifically, we use large Transformer-based pretrained language models (PLMs) and investigate: 1) how \textit{soft prompt-tuning} -- an NLP technique used to adapt PLMs using small amounts of training data -- compares to standard model fine-tuning; 2) whether simpler static word embedding models (WEMs) can be more robust compared to PLMs in highly imbalanced settings; and 3) how models fare when trained on notes from a small number of patients. We find that 1) soft-prompt tuning is an efficient alternative to standard model fine-tuning; 2) PLMs show better discrimination but worse calibration compared to simpler static word embedding models as the classification problem becomes more imbalanced; and 3) results when training models on small number of patients are mixed and show no clear differences between PLMs and WEMs. All our code is available open source in \url{https://bitbucket.org/aumc-kik/prompt_tuning_cancer_prediction/}.
Lifelong Learning in Evolving Graphs with Limited Labeled Data and Unseen Class Detection
Dec 20, 2021
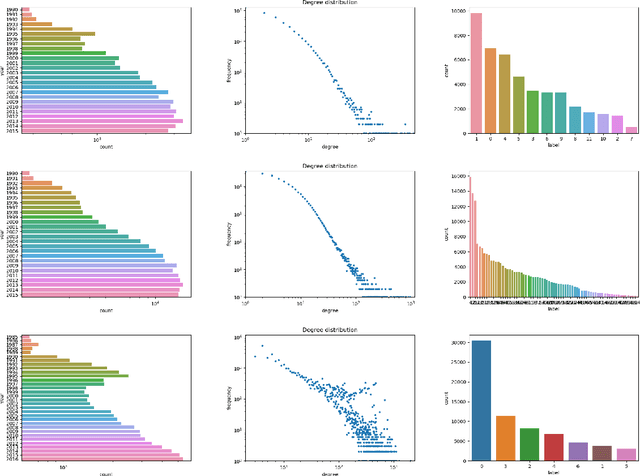

Large-scale graph data in the real-world are often dynamic rather than static. The data are changing with new nodes, edges, and even classes appearing over time, such as in citation networks and research-and-development collaboration networks. Graph neural networks (GNNs) have emerged as the standard method for numerous tasks on graph-structured data. In this work, we employ a two-step procedure to explore how GNNs can be incrementally adapted to new unseen graph data. First, we analyze the verge between transductive and inductive learning on standard benchmark datasets. After inductive pretraining, we add unlabeled data to the graph and show that the models are stable. Then, we explore the case of continually adding more and more labeled data, while considering cases, where not all past instances are annotated with class labels. Furthermore, we introduce new classes while the graph evolves and explore methods that automatically detect instances from previously unseen classes. In order to deal with evolving graphs in a principled way, we propose a lifelong learning framework for graph data along with an evaluation protocol. In this framework, we evaluate representative GNN architectures. We observe that implicit knowledge within model parameters becomes more important when explicit knowledge, i.e., data from past tasks, is limited. We find that in open-world node classification, the data from surprisingly few past tasks are sufficient to reach the performance reached by remembering data from all past tasks. In the challenging task of unseen class detection, we find that using a weighted cross-entropy loss is important for stability.
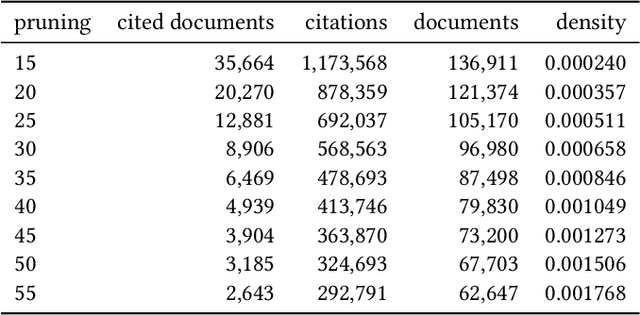
Recommendations for Item Set Completion: On the Semantics of Item Co-Occurrence With Data Sparsity, Input Size, and Input Modalities
May 10, 2021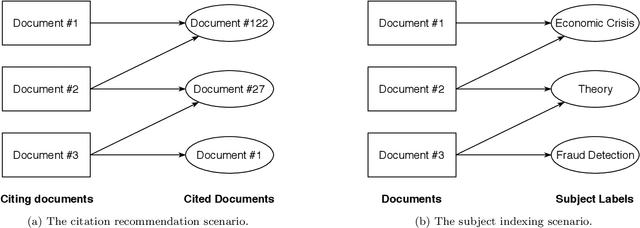

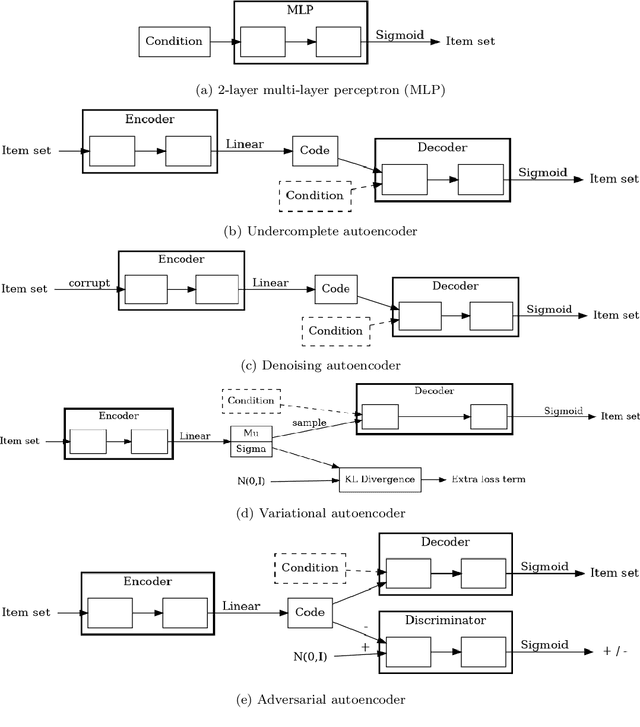
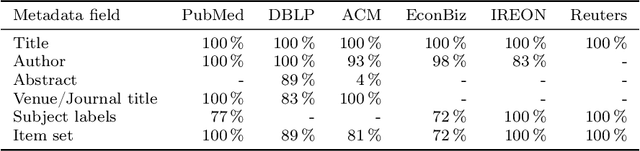
We address the problem of recommending relevant items to a user in order to "complete" a partial set of items already known. We consider the two scenarios of citation and subject label recommendation, which resemble different semantics of item co-occurrence: relatedness for co-citations and diversity for subject labels. We assess the influence of the completeness of an already known partial item set on the recommender performance. We also investigate data sparsity through a pruning parameter and the influence of using additional metadata. As recommender models, we focus on different autoencoders, which are particularly suited for reconstructing missing items in a set. We extend autoencoders to exploit a multi-modal input of text and structured data. Our experiments on six real-world datasets show that supplying the partial item set as input is helpful when item co-occurrence resembles relatedness, while metadata are effective when co-occurrence implies diversity. This outcome means that the semantics of item co-occurrence is an important factor. The simple item co-occurrence model is a strong baseline for citation recommendation. However, autoencoders have the advantage to enable exploiting additional metadata besides the partial item set as input and achieve comparable performance. For the subject label recommendation task, the title is the most important attribute. Adding more input modalities sometimes even harms the result. In conclusion, it is crucial to consider the semantics of the item co-occurrence for the choice of an appropriate recommendation model and carefully decide which metadata to exploit.
Incremental Training of Graph Neural Networks on Temporal Graphs under Distribution Shift
Jun 25, 2020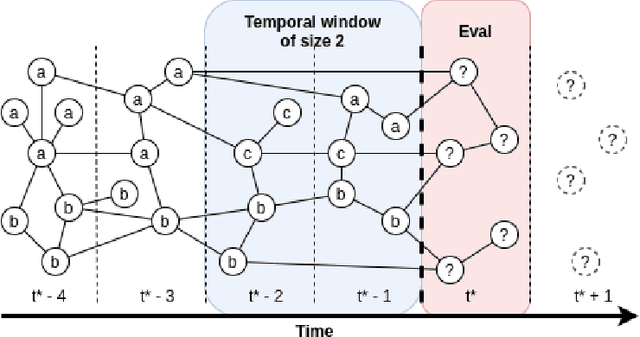


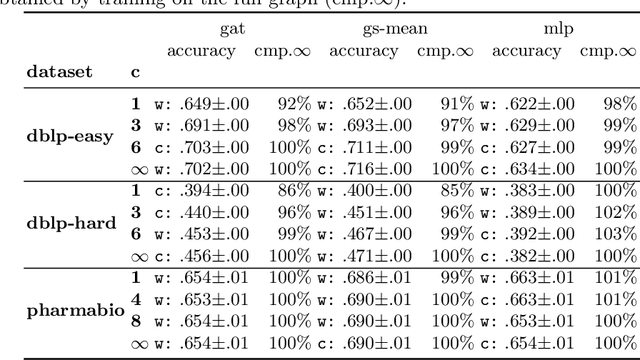
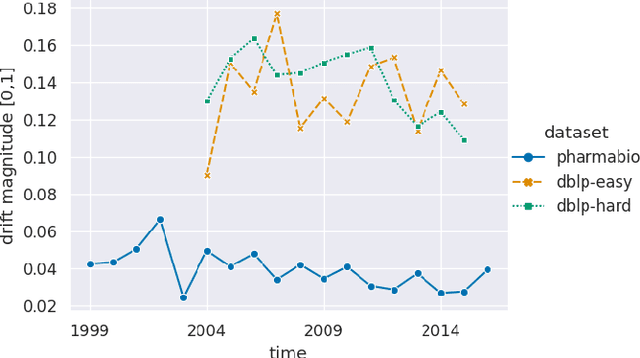
Current graph neural networks (GNNs) are promising, especially when the entire graph is known for training. However, it is not yet clear how to efficiently train GNNs on temporal graphs, where new vertices, edges, and even classes appear over time. We face two challenges: First, shifts in the label distribution (including the appearance of new labels), which require adapting the model. Second, the growth of the graph, which makes it, at some point, infeasible to train over all vertices and edges. We address these issues by applying a sliding window technique, i.e., we incrementally train GNNs on limited window sizes and analyze their performance. For our experiments, we have compiled three new temporal graph datasets based on scientific publications and evaluate isotropic and anisotropic GNN architectures. Our results show that both GNN types provide good results even for a window size of just 1 time step. With window sizes of 3 to 4 time steps, GNNs achieve at least 95% accuracy compared to using the entire timeline of the graph. With window sizes of 6 or 8, at least 99% accuracy could be retained. These discoveries have direct consequences for training GNNs over temporal graphs. We provide the code (https://github.com/Incremental-GNNs) and the newly compiled datasets (https://zenodo.org/record/3764770) for reproducibility and reuse.
Multi-Modal Adversarial Autoencoders for Recommendations of Citations and Subject Labels
Jul 22, 2019
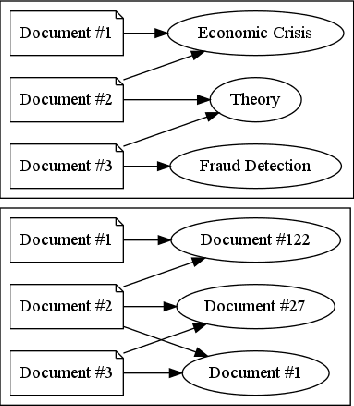
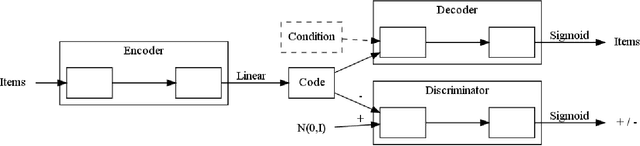
We present multi-modal adversarial autoencoders for recommendation and evaluate them on two different tasks: citation recommendation and subject label recommendation. We analyze the effects of adversarial regularization, sparsity, and different input modalities. By conducting 408 experiments, we show that adversarial regularization consistently improves the performance of autoencoders for recommendation. We demonstrate, however, that the two tasks differ in the semantics of item co-occurrence in the sense that item co-occurrence resembles relatedness in case of citations, yet implies diversity in case of subject labels. Our results reveal that supplying the partial item set as input is only helpful, when item co-occurrence resembles relatedness. When facing a new recommendation task it is therefore crucial to consider the semantics of item co-occurrence for the choice of an appropriate model.
Can Graph Neural Networks Go "Online"? An Analysis of Pretraining and Inference
May 15, 2019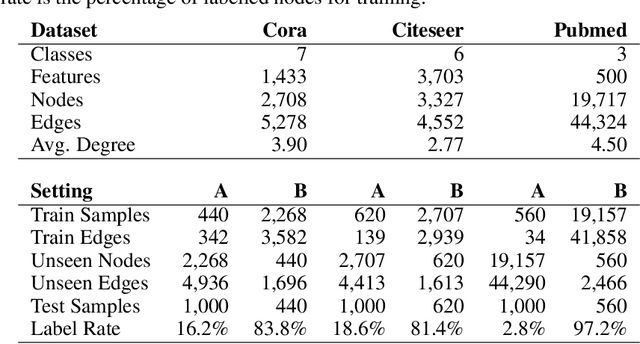

Large-scale graph data in real-world applications is often not static but dynamic, i. e., new nodes and edges appear over time. Current graph convolution approaches are promising, especially, when all the graph's nodes and edges are available during training. When unseen nodes and edges are inserted after training, it is not yet evaluated whether up-training or re-training from scratch is preferable. We construct an experimental setup, in which we insert previously unseen nodes and edges after training and conduct a limited amount of inference epochs. In this setup, we compare adapting pretrained graph neural networks against retraining from scratch. Our results show that pretrained models yield high accuracy scores on the unseen nodes and that pretraining is preferable over retraining from scratch. Our experiments represent a first step to evaluate and develop truly online variants of graph neural networks.