 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepNeCTI: Dependency-based Nested Compound Type Identification for Sanskrit
Oct 14, 2023



Multi-component compounding is a prevalent phenomenon in Sanskrit, and understanding the implicit structure of a compound's components is crucial for deciphering its meaning. Earlier approaches in Sanskrit have focused on binary compounds and neglected the multi-component compound setting. This work introduces the novel task of nested compound type identification (NeCTI), which aims to identify nested spans of a multi-component compound and decode the implicit semantic relations between them. To the best of our knowledge, this is the first attempt in the field of lexical semantics to propose this task. We present 2 newly annotated datasets including an out-of-domain dataset for this task. We also benchmark these datasets by exploring the efficacy of the standard problem formulations such as nested named entity recognition, constituency parsing and seq2seq, etc. We present a novel framework named DepNeCTI: Dependency-based Nested Compound Type Identifier that surpasses the performance of the best baseline with an average absolute improvement of 13.1 points F1-score in terms of Labeled Span Score (LSS) and a 5-fold enhancement in inference efficiency. In line with the previous findings in the binary Sanskrit compound identification task, context provides benefits for the NeCTI task. The codebase and datasets are publicly available at: https://github.com/yaswanth-iitkgp/DepNeCTI
Aesthetics of Sanskrit Poetry from the Perspective of Computational Linguistics: A Case Study Analysis on Siksastaka
Aug 14, 2023
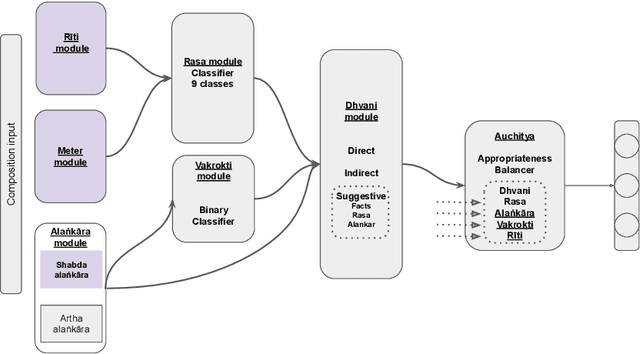
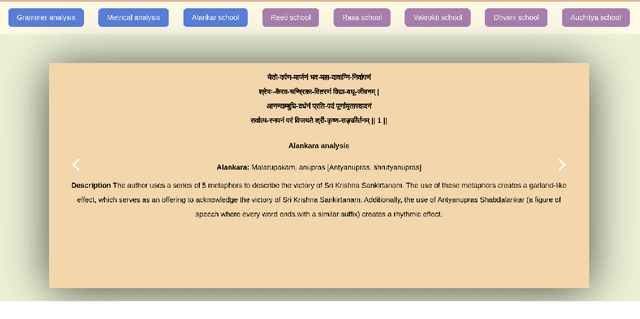
Sanskrit poetry has played a significant role in shaping the literary and cultural landscape of the Indian subcontinent for centuries. However, not much attention has been devoted to uncovering the hidden beauty of Sanskrit poetry in computational linguistics. This article explores the intersection of Sanskrit poetry and computational linguistics by proposing a roadmap of an interpretable framework to analyze and classify the qualities and characteristics of fine Sanskrit poetry. We discuss the rich tradition of Sanskrit poetry and the significance of computational linguistics in automatically identifying the characteristics of fine poetry. The proposed framework involves a human-in-the-loop approach that combines deterministic aspects delegated to machines and deep semantics left to human experts. We provide a deep analysis of Siksastaka, a Sanskrit poem, from the perspective of 6 prominent kavyashastra schools, to illustrate the proposed framework. Additionally, we provide compound, dependency, anvaya (prose order linearised form), meter, rasa (mood), alankar (figure of speech), and riti (writing style) annotations for Siksastaka and a web application to illustrate the poem's analysis and annotations. Our key contributions include the proposed framework, the analysis of Siksastaka, the annotations and the web application for future research. Link for interactive analysis: https://sanskritshala.github.io/shikshastakam/
Neural Approaches for Data Driven Dependency Parsing in Sanskrit
Apr 17, 2020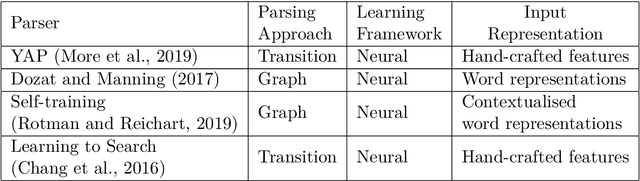
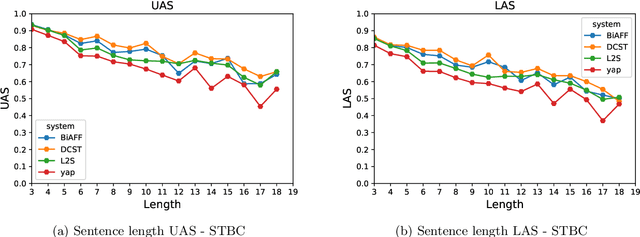
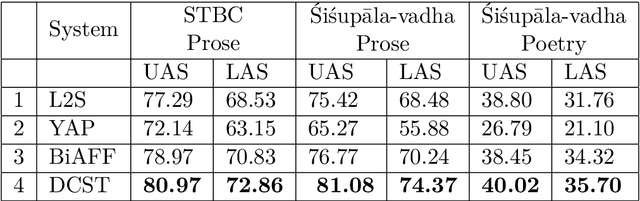
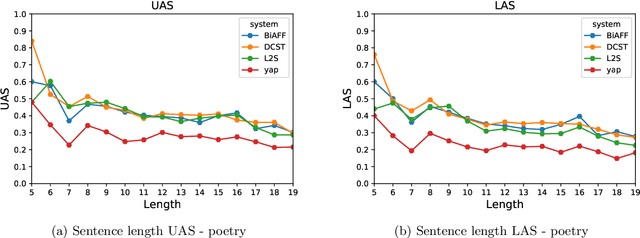
Data-driven approaches for dependency parsing have been of great interest in Natural Language Processing for the past couple of decades. However, Sanskrit still lacks a robust purely data-driven dependency parser, probably with an exception to Krishna (2019). This can primarily be attributed to the lack of availability of task-specific labelled data and the morphologically rich nature of the language. In this work, we evaluate four different data-driven machine learning models, originally proposed for different languages, and compare their performances on Sanskrit data. We experiment with 2 graph based and 2 transition based parsers. We compare the performance of each of the models in a low-resource setting, with 1,500 sentences for training. Further, since our focus is on the learning power of each of the models, we do not incorporate any Sanskrit specific features explicitly into the models, and rather use the default settings in each of the paper for obtaining the feature functions. In this work, we analyse the performance of the parsers using both an in-domain and an out-of-domain test dataset. We also investigate the impact of word ordering in which the sentences are provided as input to these systems, by parsing verses and their corresponding prose order (anvaya) sentences.
Free as in Free Word Order: An Energy Based Model for Word Segmentation and Morphological Tagging in Sanskrit
Oct 25, 2018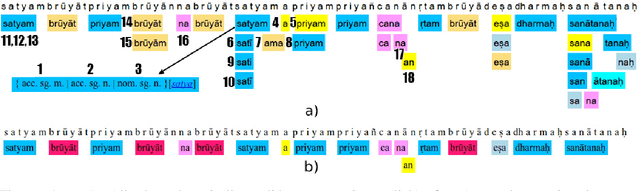
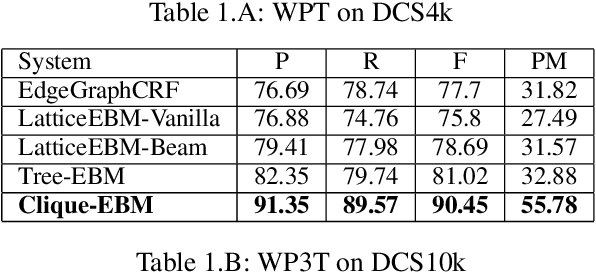
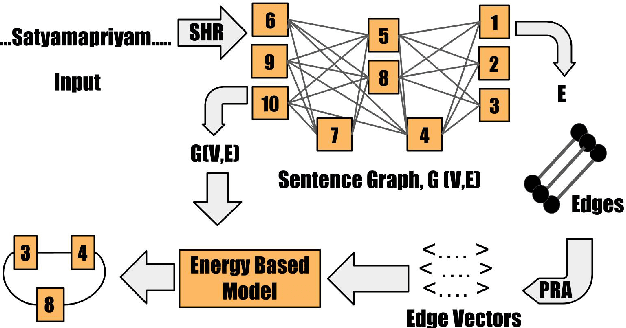
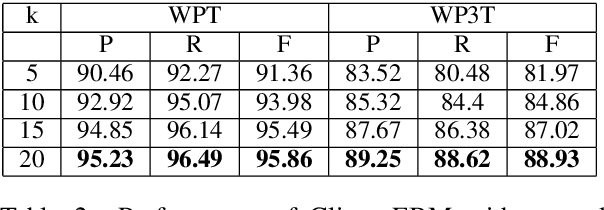
The configurational information in sentences of a free word order language such as Sanskrit is of limited use. Thus, the context of the entire sentence will be desirable even for basic processing tasks such as word segmentation. We propose a structured prediction framework that jointly solves the word segmentation and morphological tagging tasks in Sanskrit. We build an energy based model where we adopt approaches generally employed in graph based parsing techniques (McDonald et al., 2005a; Carreras, 2007). Our model outperforms the state of the art with an F-Score of 96.92 (percentage improvement of 7.06%) while using less than one-tenth of the task-specific training data. We find that the use of a graph based ap- proach instead of a traditional lattice-based sequential labelling approach leads to a percentage gain of 12.6% in F-Score for the segmentation task.