 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepNeCTI: Dependency-based Nested Compound Type Identification for Sanskrit
Oct 14, 2023



Multi-component compounding is a prevalent phenomenon in Sanskrit, and understanding the implicit structure of a compound's components is crucial for deciphering its meaning. Earlier approaches in Sanskrit have focused on binary compounds and neglected the multi-component compound setting. This work introduces the novel task of nested compound type identification (NeCTI), which aims to identify nested spans of a multi-component compound and decode the implicit semantic relations between them. To the best of our knowledge, this is the first attempt in the field of lexical semantics to propose this task. We present 2 newly annotated datasets including an out-of-domain dataset for this task. We also benchmark these datasets by exploring the efficacy of the standard problem formulations such as nested named entity recognition, constituency parsing and seq2seq, etc. We present a novel framework named DepNeCTI: Dependency-based Nested Compound Type Identifier that surpasses the performance of the best baseline with an average absolute improvement of 13.1 points F1-score in terms of Labeled Span Score (LSS) and a 5-fold enhancement in inference efficiency. In line with the previous findings in the binary Sanskrit compound identification task, context provides benefits for the NeCTI task. The codebase and datasets are publicly available at: https://github.com/yaswanth-iitkgp/DepNeCTI
Validation and Normalization of DCS corpus using Sanskrit Heritage tools to build a tagged Gold Corpus
May 13, 2020

The Digital Corpus of Sanskrit records around 650,000 sentences along with their morphological and lexical tagging. But inconsistencies in morphological analysis, and in providing crucial information like the segmented word, urges the need for standardization and validation of this corpus. Automating the validation process requires efficient analyzers which also provide the missing information. The Sanskrit Heritage Engine's Reader produces all possible segmentations with morphological and lexical analyses. Aligning these systems would help us in recording the linguistic differences, which can be used to update these systems to produce standardized results and will also provide a Gold corpus tagged with complete morphological and lexical information along with the segmented words. Krishna et al. (2017) aligned 115,000 sentences, considering some of the linguistic differences. As both these systems have evolved significantly, the alignment is done again considering all the remaining linguistic differences between these systems. This paper describes the modified alignment process in detail and records the additional linguistic differences observed. Reference: Amrith Krishna, Pavankumar Satuluri, and Pawan Goyal. 2017. A dataset for Sanskrit word segmentation. In Proceedings of the Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, page 105-114. Association for Computational Linguistics, August.
Sanskrit Segmentation Revisited
May 13, 2020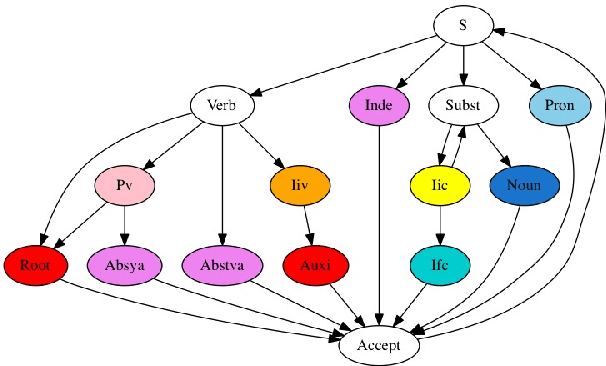



Computationally analyzing Sanskrit texts requires proper segmentation in the initial stages. There have been various tools developed for Sanskrit text segmentation. Of these, G\'erard Huet's Reader in the Sanskrit Heritage Engine analyzes the input text and segments it based on the word parameters - phases like iic, ifc, Pr, Subst, etc., and sandhi (or transition) that takes place at the end of a word with the initial part of the next word. And it enlists all the possible solutions differentiating them with the help of the phases. The phases and their analyses have their use in the domain of sentential parsers. In segmentation, though, they are not used beyond deciding whether the words formed with the phases are morphologically valid. This paper tries to modify the above segmenter by ignoring the phase details (except for a few cases), and also proposes a probability function to prioritize the list of solutions to bring up the most valid solutions at the top.