 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSanskrit Segmentation Revisited
Paper and Code
May 13, 2020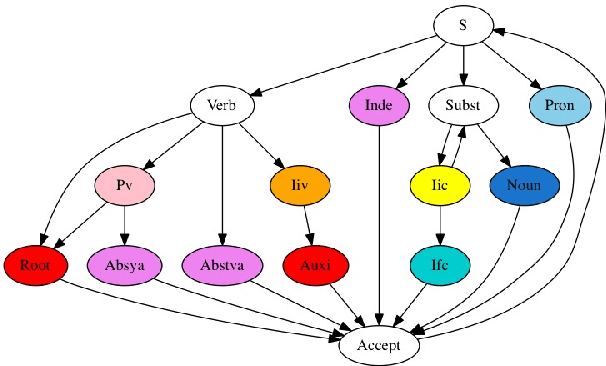



Computationally analyzing Sanskrit texts requires proper segmentation in the initial stages. There have been various tools developed for Sanskrit text segmentation. Of these, G\'erard Huet's Reader in the Sanskrit Heritage Engine analyzes the input text and segments it based on the word parameters - phases like iic, ifc, Pr, Subst, etc., and sandhi (or transition) that takes place at the end of a word with the initial part of the next word. And it enlists all the possible solutions differentiating them with the help of the phases. The phases and their analyses have their use in the domain of sentential parsers. In segmentation, though, they are not used beyond deciding whether the words formed with the phases are morphologically valid. This paper tries to modify the above segmenter by ignoring the phase details (except for a few cases), and also proposes a probability function to prioritize the list of solutions to bring up the most valid solutions at the top.