 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISLIX: An XAI Framework for Validating Vision Models with Slice Discovery and Analysis
May 06, 2025Real-world machine learning models require rigorous evaluation before deployment, especially in safety-critical domains like autonomous driving and surveillance. The evaluation of machine learning models often focuses on data slices, which are subsets of the data that share a set of characteristics. Data slice finding automatically identifies conditions or data subgroups where models underperform, aiding developers in mitigating performance issues. Despite its popularity and effectiveness, data slicing for vision model validation faces several challenges. First, data slicing often needs additional image metadata or visual concepts, and falls short in certain computer vision tasks, such as object detection. Second, understanding data slices is a labor-intensive and mentally demanding process that heavily relies on the expert's domain knowledge. Third, data slicing lacks a human-in-the-loop solution that allows experts to form hypothesis and test them interactively. To overcome these limitations and better support the machine learning operations lifecycle, we introduce VISLIX, a novel visual analytics framework that employs state-of-the-art foundation models to help domain experts analyze slices in computer vision models. Our approach does not require image metadata or visual concepts, automatically generates natural language insights, and allows users to test data slice hypothesis interactively. We evaluate VISLIX with an expert study and three use cases, that demonstrate the effectiveness of our tool in providing comprehensive insights for validating object detection models.
InterChat: Enhancing Generative Visual Analytics using Multimodal Interactions
Mar 06, 2025



The rise of Large Language Models (LLMs) and generative visual analytics systems has transformed data-driven insights, yet significant challenges persist in accurately interpreting users' analytical and interaction intents. While language inputs offer flexibility, they often lack precision, making the expression of complex intents inefficient, error-prone, and time-intensive. To address these limitations, we investigate the design space of multimodal interactions for generative visual analytics through a literature review and pilot brainstorming sessions. Building on these insights, we introduce a highly extensible workflow that integrates multiple LLM agents for intent inference and visualization generation. We develop InterChat, a generative visual analytics system that combines direct manipulation of visual elements with natural language inputs. This integration enables precise intent communication and supports progressive, visually driven exploratory data analyses. By employing effective prompt engineering, and contextual interaction linking, alongside intuitive visualization and interaction designs, InterChat bridges the gap between user interactions and LLM-driven visualizations, enhancing both interpretability and usability. Extensive evaluations, including two usage scenarios, a user study, and expert feedback, demonstrate the effectiveness of InterChat. Results show significant improvements in the accuracy and efficiency of handling complex visual analytics tasks, highlighting the potential of multimodal interactions to redefine user engagement and analytical depth in generative visual analytics.
USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation
Jun 07, 2024

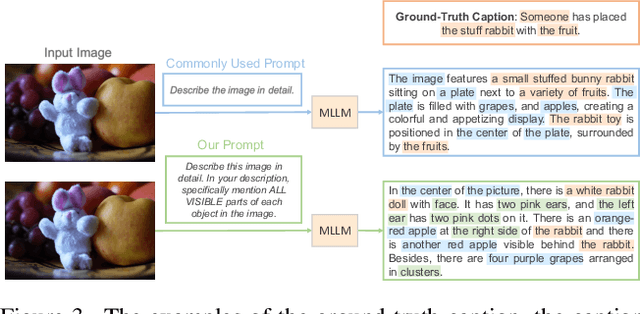
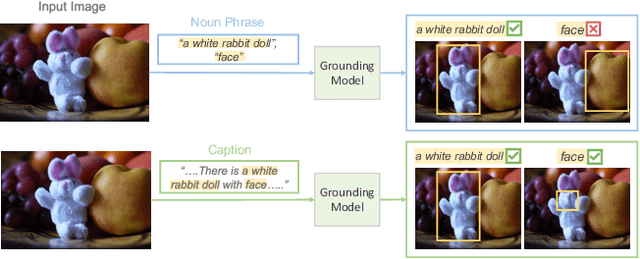
The open-vocabulary image segmentation task involves partitioning images into semantically meaningful segments and classifying them with flexible text-defined categories. The recent vision-based foundation models such as the Segment Anything Model (SAM) have shown superior performance in generating class-agnostic image segments. The main challenge in open-vocabulary image segmentation now lies in accurately classifying these segments into text-defined categories. In this paper, we introduce the Universal Segment Embedding (USE) framework to address this challenge. This framework is comprised of two key components: 1) a data pipeline designed to efficiently curate a large amount of segment-text pairs at various granularities, and 2) a universal segment embedding model that enables precise segment classification into a vast range of text-defined categories. The USE model can not only help open-vocabulary image segmentation but also facilitate other downstream tasks (e.g., querying and ranking). Through comprehensive experimental studies on semantic segmentation and part segmentation benchmarks, we demonstrate that the USE framework outperforms state-of-the-art open-vocabulary segmentation methods.
AttributionScanner: A Visual Analytics System for Metadata-Free Data-Slicing Based Model Validation
Jan 12, 2024Data slice-finding is an emerging technique for evaluating machine learning models. It works by identifying subgroups within a specified dataset that exhibit poor performance, often defined by distinct feature sets or meta-information. However, in the context of unstructured image data, data slice-finding poses two notable challenges: it requires additional metadata -- a laborious and costly requirement, and also demands non-trivial efforts for interpreting the root causes of the underperformance within data slices. To address these challenges, we introduce AttributionScanner, an innovative human-in-the-loop Visual Analytics (VA) system, designed for data-slicing-based machine learning (ML) model validation. Our approach excels in identifying interpretable data slices, employing explainable features extracted through the lens of Explainable AI (XAI) techniques, and removing the necessity for additional metadata of textual annotations or cross-model embeddings. AttributionScanner demonstrates proficiency in pinpointing critical model issues, including spurious correlations and mislabeled data. Our novel VA interface visually summarizes data slices, enabling users to gather insights into model behavior patterns effortlessly. Furthermore, our framework closes the ML Development Cycle by empowering domain experts to address model issues by using a cutting-edge neural network regularization technique. The efficacy of AttributionScanner is underscored through two prototype use cases, elucidating its substantial effectiveness in model validation for vision-centric tasks. Our approach paves the way for ML researchers and practitioners to drive interpretable model validation in a data-efficient way, ultimately leading to more reliable and accurate models.
AlphaD3M: Machine Learning Pipeline Synthesis
Nov 03, 2021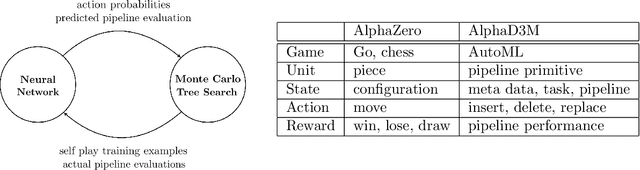
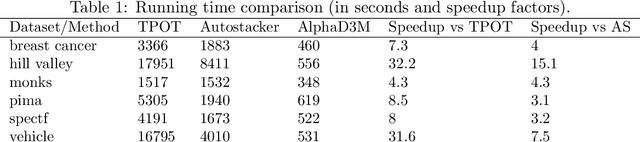
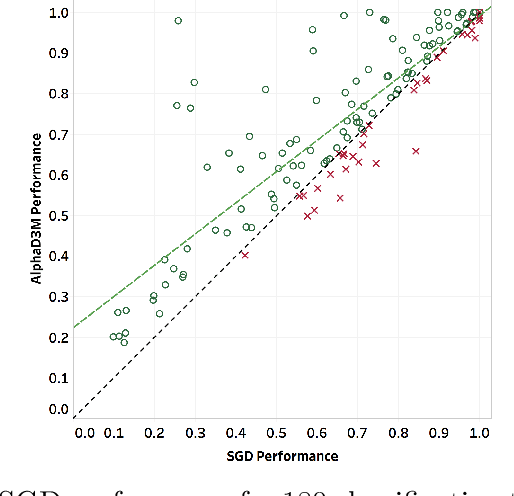
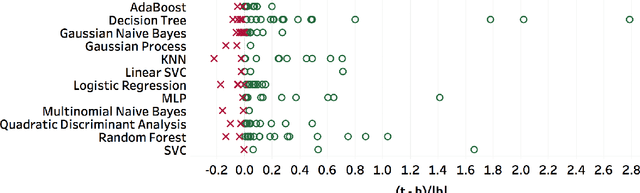
We introduce AlphaD3M, an automatic machine learning (AutoML) system based on meta reinforcement learning using sequence models with self play. AlphaD3M is based on edit operations performed over machine learning pipeline primitives providing explainability. We compare AlphaD3M with state-of-the-art AutoML systems: Autosklearn, Autostacker, and TPOT, on OpenML datasets. AlphaD3M achieves competitive performance while being an order of magnitude faster, reducing computation time from hours to minutes, and is explainable by design.
Visus: An Interactive System for Automatic Machine Learning Model Building and Curation
Jul 05, 2019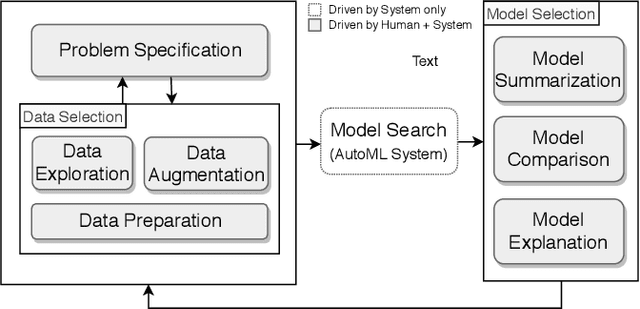
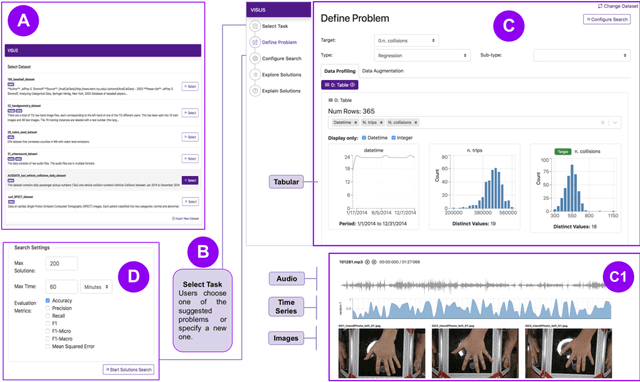
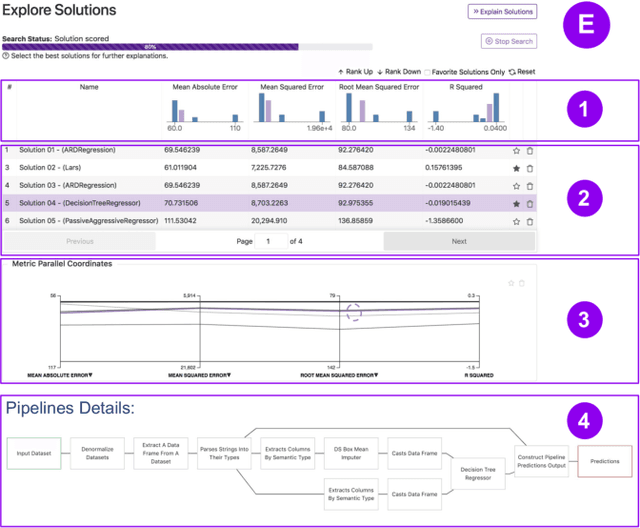
While the demand for machine learning (ML) applications is booming, there is a scarcity of data scientists capable of building such models. Automatic machine learning (AutoML) approaches have been proposed that help with this problem by synthesizing end-to-end ML data processing pipelines. However, these follow a best-effort approach and a user in the loop is necessary to curate and refine the derived pipelines. Since domain experts often have little or no expertise in machine learning, easy-to-use interactive interfaces that guide them throughout the model building process are necessary. In this paper, we present Visus, a system designed to support the model building process and curation of ML data processing pipelines generated by AutoML systems. We describe the framework used to ground our design choices and a usage scenario enabled by Visus. Finally, we discuss the feedback received in user testing sessions with domain experts.