 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Data Harmonization with LLM Agents
Feb 10, 2025



Data harmonization is an essential task that entails integrating datasets from diverse sources. Despite years of research in this area, it remains a time-consuming and challenging task due to schema mismatches, varying terminologies, and differences in data collection methodologies. This paper presents the case for agentic data harmonization as a means to both empower experts to harmonize their data and to streamline the process. We introduce Harmonia, a system that combines LLM-based reasoning, an interactive user interface, and a library of data harmonization primitives to automate the synthesis of data harmonization pipelines. We demonstrate Harmonia in a clinical data harmonization scenario, where it helps to interactively create reusable pipelines that map datasets to a standard format. Finally, we discuss challenges and open problems, and suggest research directions for advancing our vision.
Correlation Sketches for Approximate Join-Correlation Queries
Apr 07, 2021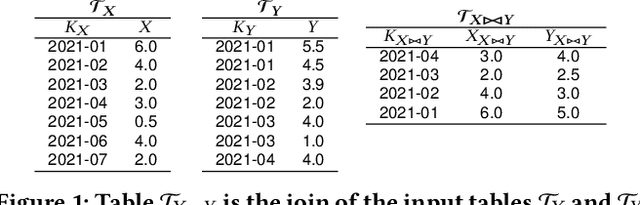


The increasing availability of structured datasets, from Web tables and open-data portals to enterprise data, opens up opportunities~to enrich analytics and improve machine learning models through relational data augmentation. In this paper, we introduce a new class of data augmentation queries: join-correlation queries. Given a column $Q$ and a join column $K_Q$ from a query table $\mathcal{T}_Q$, retrieve tables $\mathcal{T}_X$ in a dataset collection such that $\mathcal{T}_X$ is joinable with $\mathcal{T}_Q$ on $K_Q$ and there is a column $C \in \mathcal{T}_X$ such that $Q$ is correlated with $C$. A na\"ive approach to evaluate these queries, which first finds joinable tables and then explicitly joins and computes correlations between $Q$ and all columns of the discovered tables, is prohibitively expensive. To efficiently support correlated column discovery, we 1) propose a sketching method that enables the construction of an index for a large number of tables and that provides accurate estimates for join-correlation queries, and 2) explore different scoring strategies that effectively rank the query results based on how well the columns are correlated with the query. We carry out a detailed experimental evaluation, using both synthetic and real data, which shows that our sketches attain high accuracy and the scoring strategies lead to high-quality rankings.
Auctus: A Dataset Search Engine for Data Augmentation
Feb 10, 2021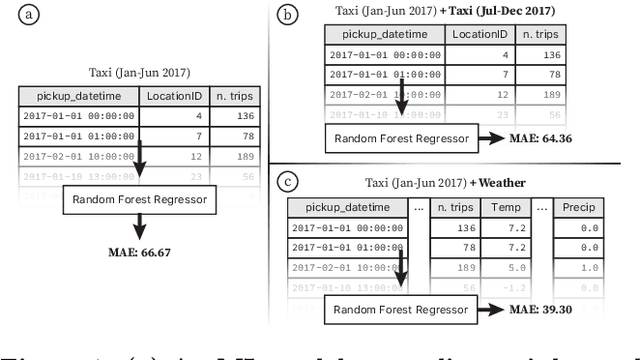
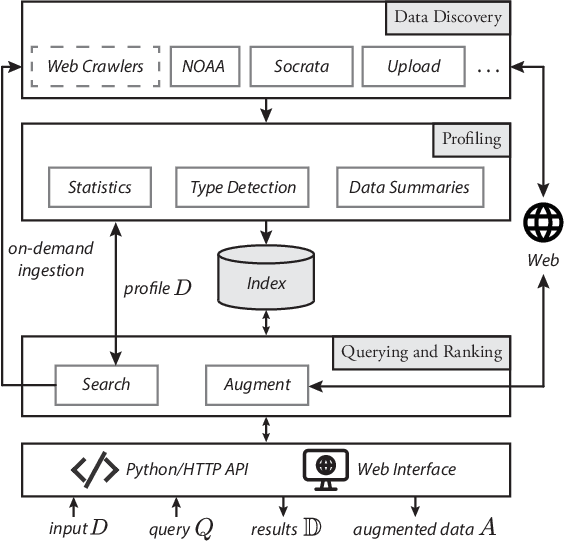
Machine Learning models are increasingly being adopted in many applications. The quality of these models critically depends on the input data on which they are trained, and by augmenting their input data with external data, we have the opportunity to create better models. However, the massive number of datasets available on the Web makes it challenging to find data suitable for augmentation. In this demo, we present our ongoing efforts to develop a dataset search engine tailored for data augmentation. Our prototype, named Auctus, automatically discovers datasets on the Web and, different from existing dataset search engines, infers consistent metadata for indexing and supports join and union search queries. Auctus is already being used in a real deployment environment to improve the performance of ML models. The demonstration will include various real-world data augmentation examples and visitors will be able to interact with the system.
Visus: An Interactive System for Automatic Machine Learning Model Building and Curation
Jul 05, 2019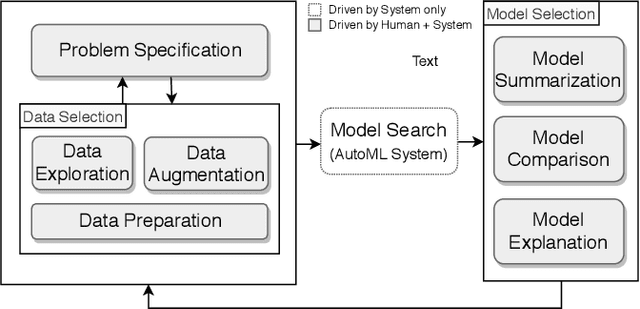
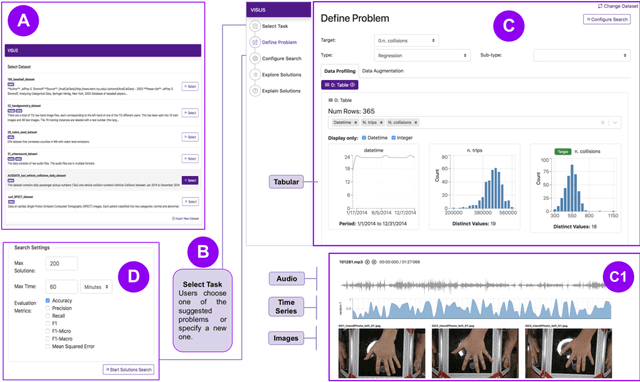
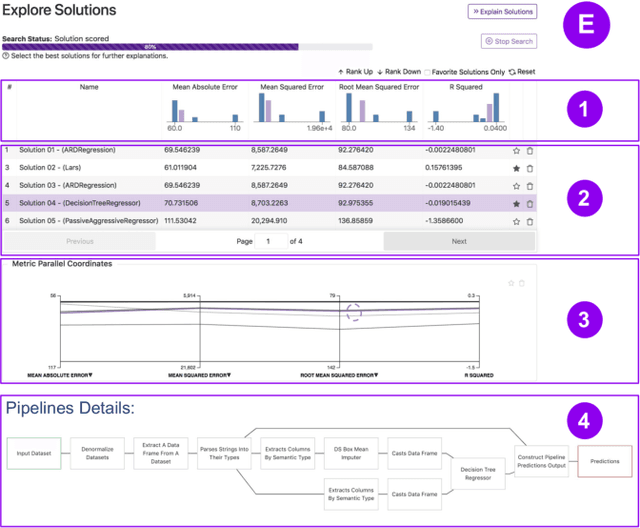
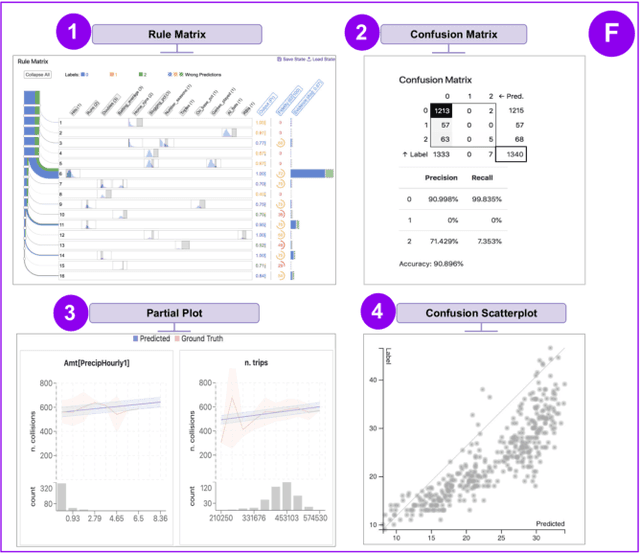
While the demand for machine learning (ML) applications is booming, there is a scarcity of data scientists capable of building such models. Automatic machine learning (AutoML) approaches have been proposed that help with this problem by synthesizing end-to-end ML data processing pipelines. However, these follow a best-effort approach and a user in the loop is necessary to curate and refine the derived pipelines. Since domain experts often have little or no expertise in machine learning, easy-to-use interactive interfaces that guide them throughout the model building process are necessary. In this paper, we present Visus, a system designed to support the model building process and curation of ML data processing pipelines generated by AutoML systems. We describe the framework used to ground our design choices and a usage scenario enabled by Visus. Finally, we discuss the feedback received in user testing sessions with domain experts.
A Topic-Agnostic Approach for Identifying Fake News Pages
May 02, 2019
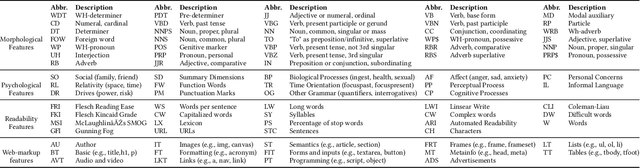
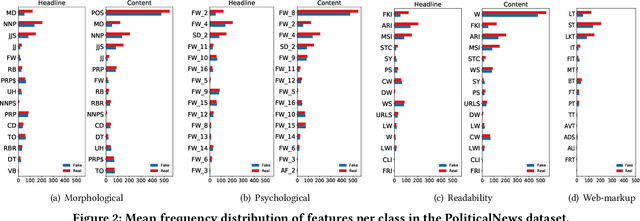
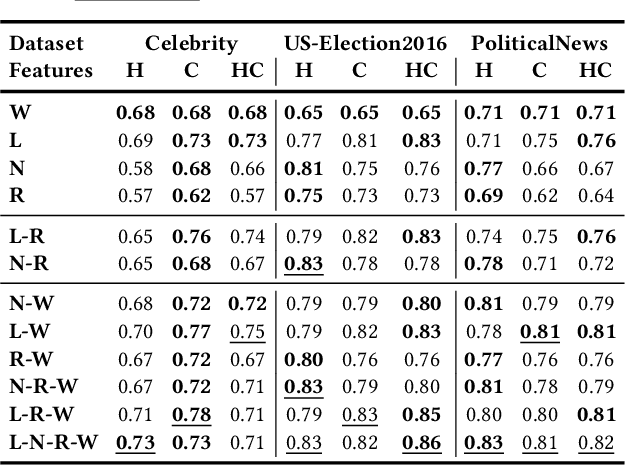
Fake news and misinformation have been increasingly used to manipulate popular opinion and influence political processes. To better understand fake news, how they are propagated, and how to counter their effect, it is necessary to first identify them. Recently, approaches have been proposed to automatically classify articles as fake based on their content. An important challenge for these approaches comes from the dynamic nature of news: as new political events are covered, topics and discourse constantly change and thus, a classifier trained using content from articles published at a given time is likely to become ineffective in the future. To address this challenge, we propose a topic-agnostic (TAG) classification strategy that uses linguistic and web-markup features to identify fake news pages. We report experimental results using multiple data sets which show that our approach attains high accuracy in the identification of fake news, even as topics evolve over time.